CSDN这么公然爬取(piao qie)cnblogs的文章,给钱了吗?
在CSDN网站经常看到有博客转载cnblogs的文章,开始还以为是网友自行转载,后来才发现,这些所谓的转载应该都是机器爬取(piao qie)过去的。不知道cnblogs对此怎么看。
下面看看几个示例
博主发博客的时间比它注册博客的时间还早,而且转载的时间和原稿发布时间分秒不差。

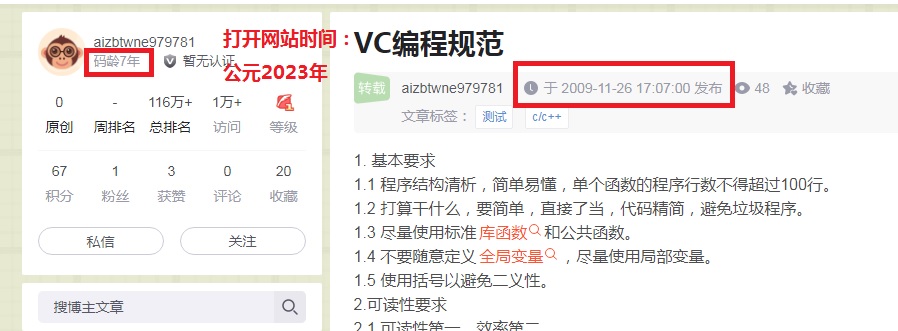
这爬取也太直白了吧,马脚也不藏一下,虽然你标记了转载。
这下我总算明白了,为什么CSDN明明是转的别人文章,标题那里却还是显示着“原创”。原因是,这些是真网友转载的,只是在文章后面注明了来源,并没有申明原创或者转载;但上面那些机器爬取的文章,则显示在标题处申明为转载。
下面再放几个对比文章
CSDN爬取的文章 https://blog.csdn.net/aizbtwne979781/article/details/101130277

cnblogs的文章 https://www.cnblogs.com/afarmer/archive/2011/12/09/2282719.html

这样的结果是,很多问题百度出来都是csdn的结果,其实文章都是来源于cnblogs。博客园你不觉得亏吗?CSDN你不觉得无耻吗?
不过在bing搜索时,一般优先显示cnblogs的内容。
CSDN这么公然爬取(piao qie)cnblogs的文章,给钱了吗?的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Scrapy爬取伯乐在线的所有文章
本篇文章将从搭建虚拟环境开始,爬取伯乐在线上的所有文章的数据. 搭建虚拟环境之前需要配置环境变量,该环境变量的变量值为虚拟环境的存放目录 1. 配置环境变量 2.创建虚拟环境 用mkvirtualen ...
- 爬取博主的所有文章并保存为PDF文件
继续改进上一个项目,上次我们爬取了所有文章,但是保存为TXT文件,查看不方便,而且还无法保存文章中的代码和图片. 所以这次保存为PDF文件,方便查看. 需要的工具: 1.wkhtmltopdf安装包, ...
- python:爬取博主的所有文章的链接、标题和内容
以爬取我自己的博客为例:https://www.cnblogs.com/Mr-choa/ 1.获取所有的文章的链接: 博客文章总共占两页,比如打开第一页:https://www.cnblogs.com ...
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python递归爬取头条用户的所有文章、视频
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- 记一次python写爬虫爬取学校官网的文章
有一位老师想要把官网上有关数字化的文章全部下载下来,于是找到我,使用python来达到目的 首先先查看了文章的网址 获取了网页的源代码发现一个问题,源代码里面没有url,这里的话就需要用到抓包了,因为 ...
- scrapy爬取简书整站文章
在这里我们使用CrawlSpider爬虫模板, 通过其过滤规则进行抓取, 并将抓取后的结果存入mysql中,下面直接上代码: jianshu_spider.py # -*- coding: utf-8 ...
- 一文搞定scrapy爬取众多知名技术博客文章保存到本地数据库,包含:cnblog、csdn、51cto、itpub、jobbole、oschina等
本文旨在通过爬取一系列博客网站技术文章的实践,介绍一下scrapy这个python语言中强大的整站爬虫框架的使用.各位童鞋可不要用来干坏事哦,这些技术博客平台也是为了让我们大家更方便的交流.学习.提高 ...
- scrapy爬取cnblogs文章列表
scrapy爬取cnblogs文章 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/cnblogs.py 编写 pipelines.py 编写 settings.py 运行 ...
随机推荐
- 关于Java中代码的执行顺序
结论 注意 只有显式的加载类 JVM才会加载到内存中 先加载父类的静态代码块 然后执行子类静态代码块 当前类存在类静态变量注意引用类型没进行赋值操作初始化为null 并不会显式的加载类又存在静态代码块 ...
- MKL稀疏矩阵运算示例及函数封装
Intel MKL库提供了大量优化程度高.效率快的稀疏矩阵算法,使用MKL库的将大型矩阵进行稀疏表示后,利用稀疏矩阵运算可大量节省计算时间和空间,但由于MKL中的原生API接口繁杂,因此将常用函数封装 ...
- A-O-P 一篇概览
一.什么是AOP? AOP 即 Aspect-oriented Programming,Aspect 切面,什么是切面,就是一条大路上的收费站,检查站,首先它是一个统一的功能单元,或是收费.或是检查, ...
- Python 使用列表一部分(切片)
使用列表的一部分(切片) 处理列表的部分元素 切片 指定第一个元素的索引和最后一个元素索引加1 列表名[索引:索引+1] 索引加1:列表中第索引个元素 (左包括右不包括) 未指定索引 列表名[:] 提 ...
- 如何通过C#/VB.NET代码将PowerPoint转换为HTML
利用PowerPoint可以很方便的呈现多媒体信息,且信息形式多媒体化,表现力强.但难免在某些情况下我们会需要将PowerPoint转换为HTML格式.因为HTML文档能独立于各种操作系统平台(如Un ...
- 2022-11-30:小红拿到了一个仅由r、e、d组成的字符串 她定义一个字符e为“好e“ : 当且仅当这个e字符和r、d相邻 例如“reeder“只有一个“好e“,前两个e都不是“好e“,只有第三个
2022-11-30:小红拿到了一个仅由r.e.d组成的字符串 她定义一个字符e为"好e" : 当且仅当这个e字符和r.d相邻 例如"reeder"只有一个&q ...
- 解决:django.db.utils.OperationalError: no such table: auth_user
解决:django.db.utils.OperationalError: no such table: auth_user 我们在创建Django项目的时候已经创建这个表了,表一般都保存在轻量级数据库 ...
- lec-6-Actor-Critic Algorithms
从PG→Policy evaluation 更多样本的均值+Causality+Baseline 减少variance 只要拟合估计Q.V:这需要两个网络 Value function fitting ...
- 【GiraKoo】C++编译中常用的内置宏
开源项目:https://girakoo.com/ 联系方式:girakoo@163.com 简介 针对不同的平台,很多头文件,函数名称,类型占用空间不一致. 为了保证跨平台可编译,经常需要在项目中使 ...
- y总算法基础课+算法提高课+算法进阶课超全模板
y总超全算法模板 y总模板自取 喜欢的可以点个赞支持一下^-^ 模板展示