大数据(2)---HDFS集群搭建
一、准备工作
1.准备几台机器,我这里使用VMware准备了四台机器,一个name node,三个data node。
VMware安装虚拟机:https://www.cnblogs.com/nijunyang/p/12001312.html
2.Hadoop生态几乎都是用的java开发的,因此四台机器还需要安装JDK。
3.集群内主机域名映射,将四台机器的IP和主机名映射分别写到hosts文件中(切记主机名不要带非法字符,图片中的下划线”_”请忽略)
vim /etc/hosts
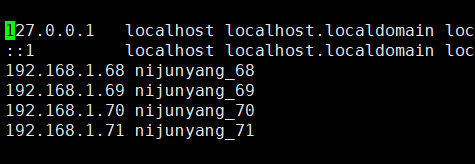
配好一个之后可以直接将这个复制到其他机器上面去,不用每台都去配置:
scp /etc/hosts nijunyang69:/etc/
scp /etc/hosts nijunyang70:/etc/
scp /etc/hosts nijunyang71:/etc/
二、hdfs集群安装
1.下载hadoop安装包到linux服务器上面,并进行解压,我这里使用的的2.8.5,
tar -zxvf hadoop-2.8.5.tar.gz
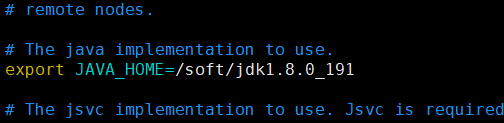
2.hadoop指定java环境变量:
hadoop-2.8.5/etc/hadoop/hadoop-env.sh 文件中指定java环境变量:
export JAVA_HOME=/soft/jdk1.8.0_191
3.配置核心参数:
默认参数:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
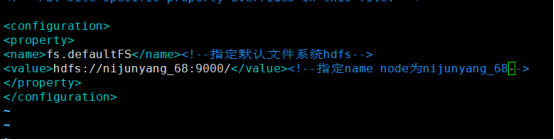
1)指定hadoop的默认文件系统为:hdfs
2)指定hdfs的namenode节点为哪台机器
修改/etc/hadoop/core-site.xml 指定hadoop默认文件系统为hdfs,并且指定name node
<configuration> <property> <name>fs.defaultFS</name><!--指定默认文件系统hdfs--> <value>hdfs://nijunyang68:9000/</value><!--指定name node为nijunyang_68--> </property> </configuration>
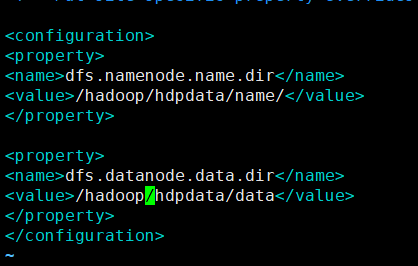
3) 指定namenode存储数据的本地目录
4) 指定datanode存放文件块的本地目录
修改/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/hadoop/hdpdata/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/hadoop/hdpdata/data</value>
</property>
</configuration>
每台机器都执行同样的操作,配置好上述配置,可以使用scp -r /soft/hadoop-2.8.5 nijunyang69:/soft 这个命令将第一台机器配置好的全部打包拷贝到另外机器上面去。
4.配置hadoop环境变量
5.初始化namenode:hadoop namenode -format
这时我们设置的namenode数据目录下面就会初始化出来对应的文件夹
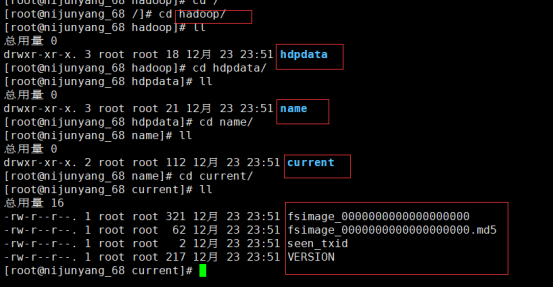
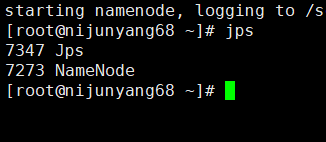
6.启动namenode:在之前指定的namenode上面执行:hadoop-daemon.sh start namenode
Jps查看可以看到一个namenode的java进程,同时通过默认的50070端口可以进行web访问
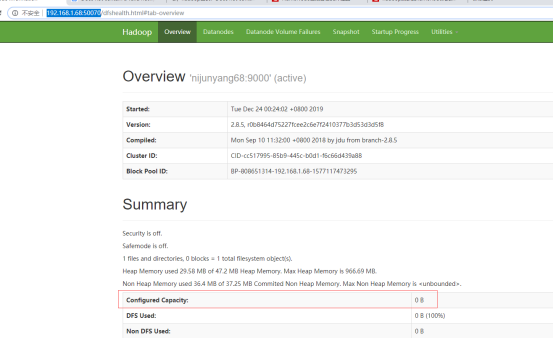
可以看到现在HDFS的容量还是0,因为我还没有启动datanode
7.依次启动datanode:hadoop-daemon.sh start datanode
同样可以看到一个datanode的java进程启动了,再看web页面这个时候的hdfs容量大小差不多就是三个datanode之和了。
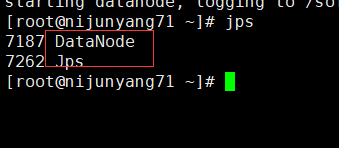

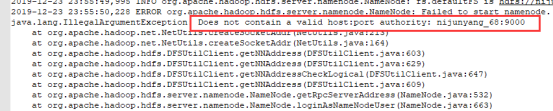
至此整个hdfs集群基本就搭建完毕了,中间的一个小插曲,主机名一定不要带”.” “/” “_”等特殊符号,否则启动无服务的时候可能报错无法启动:Does not contain a valid host
三、脚本一键启动集群
1.在启动的机器上配置SSH免密登录集群所有机器,在任意一台机器配置都可以
1)生成秘钥:ssh-keygen
2)设置免密连接:
ssh-copy-id nijunyang68
ssh-copy-id nijunyang69
ssh-copy-id nijunyang70
ssh-copy-id nijunyang71
设置好之后就可以当前机器直接通过SSH连接其他机器,不需要输入密码
2. 修改文件hadoop-2.8.5/etc/hadoop/etc/hadoop/slaves,加入需要启动的datanode
默认有个本机。如果不需要再本机启动datanode就把localhost删掉
3.执行sbin目录下的集群启动脚本/停止脚本:start-dfs.sh/stop-dfs.sh

虽然集群起来了,但是还有个Starting secondary namenodes 启动在本机上,这个时候我最好去将secondary namenodes配置到另外的机器上面去,修改之前的/etc/hadoop/hdfs-site.xml,加入secondary namenodes的配置:
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>nijunyang69:50090</value>
</property>
大数据(2)---HDFS集群搭建的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据平台Hadoop集群搭建
一.概念 Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式分析应用的开源框架,其核心部件是HDFS与MapReduce.HDFS是一个分布式文件系统,类似mogilef ...
- 大数据中Hadoop集群搭建与配置
前提环境是之前搭建的4台Linux虚拟机,详情参见 Linux集群搭建 该环境对应4台服务器,192.168.1.60.61.62.63,其中60为主机,其余为从机 软件版本选择: Java:JDK1 ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- 大数据-HBase HA集群搭建
1.下载对应版本的Hbase,在我们搭建的集群环境中选用的是hbase-1.4.6 将下载完成的hbase压缩包放到对应的目录下,此处我们的目录为/opt/workspace/ 2.对已经有的压缩包进 ...
- 大数据:spark集群搭建
创建spark用户组,组ID1000 groupadd -g 1000 spark 在spark用户组下创建用户ID 2000的spark用户 获取视频中文档资料及完整视频的伙伴请加QQ群:9479 ...
- 大数据学习——hdfs集群启动
第一种方式: 1 格式化namecode(是对namecode进行格式化) hdfs namenode -format(或者是hadoop namenode -format) 进入 cd /root/ ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据中Linux集群搭建与配置
因测试需要,一共安装4台linux系统,在windows上用vm搭建. 对应4个IP为192.168.1.60.61.62.63,这里记录其中一台的搭建过程,其余的可以直接复制虚拟机,并修改相关配置即 ...
随机推荐
- Disable trigger to avoid the ID is auto-updated
CREATE TABLE COBRA.COBRA_PRODUCT_INFO_BAK AS SELECT * FROM COBRA.COBRA_PRODUCT_INFO; TRUNCATE TABLE ...
- 说一下 synchronized 底层实现原理?(未完成)
说一下 synchronized 底层实现原理?(未完成)
- ESLint 报错 import/no-unresolved
马的,就这个规则百度了大半天终于找到可以用的: 不得不说百度真的辣鸡 还是翻墙去谷歌找到了解决方法 解决方法是:在 .eslintrc 中设置 "rules": { "i ...
- 2019HDU多校第四场 Just an Old Puzzle ——八数码有解条件
理论基础 轮换与对换 概念:把 $S$ 中的元素 $i_1$ 变成 $i_2$,$i_2$ 变成 $i_3$ ... $i_k$ 又变成 $i_1$,并使 $S$ 中的其余元素保持不变的置换称为循环, ...
- 洛谷P1273 有线电视网【树形dp】
题目:https://www.luogu.org/problemnew/show/P1273 题意:一棵树,叶子节点是用户,每天边有一个权值表示花费,每一个用户有一个值表示他们会交的钱. 问在不亏本的 ...
- 12、生命周期-@Bean指定初始化和销毁方法
12.生命周期-@Bean指定初始化和销毁方法 Bean的生命周期:创建->初始化->销毁 容器管理bean的生命周期 我们可以自定义初始方法和销毁方法,容器在bean进行到当期那生命周期 ...
- python第三方库的更新和安装指定版本
安装指定版本: pip install openpyxl==2.3.4 更新到最新版本: pip install --upgrade openpyxl
- 【题解】P1638 逛画展-C++
原题传送门 思路这道题目可以通过尺取法来完成 (我才不管什么必须用队列)什么是尺取法呢?顾名思义,像尺子一样取一段,借用挑战书上面的话说,尺取法通常是对数组保存一对下标,即所选取的区间的左右端点,然后 ...
- @ControllerAdvice与@ControllerAdvice统一处理异常
https://blog.csdn.net/zzzgd_666/article/details/81544098(copy) 详细看此 所以结合上面我们可以知道,使用@ExceptionHandler ...
- P4717 快速沃尔什变换FWT 模板题
#include <bits/stdc++.h> using namespace std; #define rep(i,a,n) for (int i=a;i<n;i++) #def ...