python3爬取百度知道的问答并存入数据库(MySQL)
一、链接分析:
以"Linux"为搜索的关键字为例:
首页的链接为:https://zhidao.baidu.com/search?lm=0&rn=10&pn=0&fr=search&ie=gbk&word=linux
第二页的链接为:https://zhidao.baidu.com/search?word=linux&ie=gbk&site=-1&sites=0&date=0&pn=10
第三页的链接为:https://zhidao.baidu.com/search?word=linux&ie=gbk&site=-1&sites=0&date=0&pn=20
链接可以统一为:https://zhidao.baidu.com/search?word= + 关键字 + &ie=gbk&site=-1&sites=0&date=0&pn= + (页面数-1)*10
即使首页也可以这样写,只需要将最后的pn的值定为0,。
这样,我们只需要获取页面的最大页面数,然后遍历处理就可以。
二、分析首页页面:
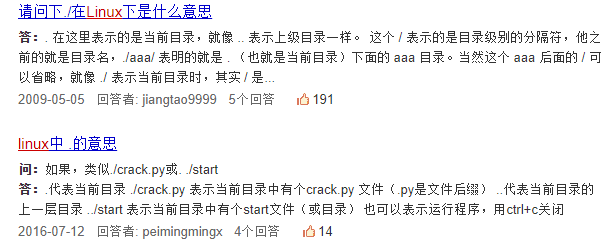
我们可以看到,在索引界面中有问题和问题的答案,此外还有提问时间和答案贡献者,但这些我在这里暂时不爬取,有兴趣的可以去试试。问题的描述一般是完整的但答案的描述就不一定了。
而在详情页两者的描述都很完整,因此为方便起见,我们统一在详情页获取问题和答案,这就需要在索引页获取详情页的URL。
通过分析很容易知道,详情页的URL在 <div class="list-inner"> 这个块中,并且在其中每个的 class="ti" 的a标签的href属性的值就是我们要的URL。
很容易获取,这里我们使用BeautifulSoup来提取。主要的代码如下:
def Get_URL(html):
#从html源码中解析出url并返回,传入参数为html源码,返回URL列表
Soup = BeautifulSoup(html,'lxml')
info = Soup.select('.list-inner')
info = info[0].select('.ti')
return [i['href'] for i in info]
三、从详情页获取问题和答案:
详情页的问题的描述一般有两种形式:一种是普通问题,放在 <span class="ask-title "> 这个块中,提取里面的文本就是问题的描述了;一种是作业帮的问题,放在 <span class="qb-content" data-gradeid="0" data-courseid="0"> 这个块中,提取里面的文本就是问题的描述了。
问题的答案也分上述两种,放在 <pre id="best-content-2257025851" accuse="aContent" class="best-text mb-10" style="min-height: 55px;"> 块中的一般问题的答案和放在 <dt class="title"> 块中的作业帮的问题的答案。
当然,你也可以有不同的获取方式,只要最终能得到信息的存放的位置就可以。知道信息的位置,很容易写代码获取。
def Get_info(url):
#进入详情页获取问题和答案,传入URL,返回问题和答案
res = requests.get(url, headers = header)
res.encoding = 'gbk'
Soup = BeautifulSoup(res.text,'lxml') try:
info = Soup.select('pre[accuse="aContent"]')
if len(info) < 1:
#print(url)
info = Soup.select('div[accuse="aContent"]')
if len(info) < 1:
info = Soup.select('dt[class="title"]') info = info[0].text
except:
info = ''
print('获取回答失败,对应的URL为:',url)
try:
ask = Soup.select('.ask-title ')
if len(ask) < 1:
ask = Soup.select('.qb-content') ask = ask[0].text
except:
ask = ''
print('获取标题失败,对应的URL为:',url) return ask,info
四、存入数据库:
说实话,爬取数据我一个早上就写完了,但是存入数据库中花了三天时间。主要是数据库的知识忘得差不多了,毕竟自从学完后基本没什么机会用。
这里我们使用了Python操纵数据库的一个模块PyMySQL,不清楚的小伙伴可以参考这里:Python+MySQL数据库操作(PyMySQL)。
当然前提是你懂得MySQL,如果这个你也不是很了解,可以先看看这个:MySQL教程
首先,我们创建一个数据库的表test.Data来存储数据,执行下面代码之前请确认:
- 已经创建了一个数据库:test
- MySQL用户"guest"和密码"12345"可以访问test数据库
具体代码如下:
def Create_table(name = 'Data'):
#传入数据库的名称,创建数据库,数据库一共有三列:问题id、问题和答案 db = pymysql.connect("localhost","guest","","test", use_unicode=True, charset="utf8")
#db.set_character_set('utf8')
cursor = db.cursor()
sql_1 = "drop table if exists " + name
sql_2 = """create table %s(
id int(100) not null auto_increment,
question text(10000) not null,
answer text(10000) default NULL,
PRIMARY KEY (`id`)
)engine=InnoDB default charset=utf8;""" %name
cursor.execute(sql_1)
#print(sql_2)
cursor.execute(sql_2) return db def Load_date(db,date):
#将date数据插入数据库 cursor = db.cursor() sql = """insert into Date(question,answer) values(%s,%s);""" %(date[0],date[1])
#print(sql)
cursor.execute(sql) db.commit()
完整的代码如下:
import requests
import re
from bs4 import BeautifulSoup
import time
import pymysql
import sys
url_1 = "https://zhidao.baidu.com/search?word="
url_2 = "&ie=gbk&site=-1&sites=0&date=0&pn="
header = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.78 Safari/537.36'} def Get_html(keyword, number = 0):
#输入关键字,获取得到结果的数量和源码
#如果是首页,返回首页的HTML源码和最大页数;如果不是,则只返回HTML源码 url = url_1 + keyword + url_2 + str(number)
#print(url)
res = requests.get(url = url, headers = header)
res.encoding = 'gbk'
html = res.text
if number == 0:
reg = r'<a class="pager-last".+?pn=(.+?)">尾页</a>'
reg = re.compile(reg)
number = re.findall(reg,html)[0]
return html,number
else:
return html def Get_URL(html):
#从html源码中解析出url并返回
Soup = BeautifulSoup(html,'lxml')
info = Soup.select('.list-inner')
info = info[0].select('.ti')
return [i['href'] for i in info] def Get_info(url):
#传入详情页的URL,进入详情页获取问题和答案并返回 res = requests.get(url, headers = header)
res.encoding = 'gbk'
Soup = BeautifulSoup(res.text,'lxml') #详情页的问题和答案一共有三种情况,一是普通问题,二是作业帮的问答问题,三是丢失的问答
try:
info = Soup.select('pre[accuse="aContent"]')
if len(info) < 1:
#print('不在pre[accuse="aContent"]')
info = Soup.select('div[accuse="aContent"]')
if len(info) < 1:
info = Soup.select('dt[class="title"]') info = info[0].text
except:
info = ''
print('获取回答失败,对应的URL为:',url)
try:
ask = Soup.select('.ask-title ')
if len(ask) < 1:
ask = Soup.select('.qb-content') ask = ask[0].text
except:
ask = ''
print('获取标题失败,对应的URL为:',url) return ask,info def Create_table(name = 'Data'):
#传入数据库的名称,创建数据库,数据库一共有三列:问题id、问题和答案 db = pymysql.connect("localhost","guest","","test", use_unicode=True, charset="utf8")
#db.set_character_set('utf8')
cursor = db.cursor()
sql_1 = "drop table if exists " + name
sql_2 = """create table %s(
id int(100) not null auto_increment,
question text(10000) not null,
answer text(10000) default NULL,
PRIMARY KEY (`id`)
)engine=InnoDB default charset=utf8;""" %name
cursor.execute(sql_1)
#print(sql_2)
cursor.execute(sql_2) return db def Load_date(db,date):
#将date数据插入数据库
#db = pymysql.connect("localhost","guest","12345","test", use_unicode=True, charset="utf8")
cursor = db.cursor() sql = """insert into Date(question,answer) values(%s,%s);""" %(date[0],date[1])
#print(sql)
cursor.execute(sql) db.commit() def main():
#主调函数,负责调度其他辅助函数
#主要流程如下:
#根据获取的关键字,得到首页的HTML源码和最大页数
#从源码中获取详情页的URL
#然后创建数据库用来保存爬取的数据
#遍历详情页的URL,获取问题和答案,并将获得的数据插入数据库 keyword = '标书'
[html,number] = Get_html(keyword) print("总共有%s页的结果!" %str(number)) URL = Get_URL(html)
db = Create_table() for u in URL:
#print(u)
[ask,answer] = Get_info(u)
if len(ask) > 1:
ask = """'%s'""" %ask
answer = """'%s'""" %answer
date = [ask,answer]
Load_date(db,date)
time.sleep(1)
print("首页获取完毕!")
time.sleep(3) for i in range(1,int(int(number)/10+1)):
html = Get_html(keyword,i*10)
URL = Get_URL(html)
for u in URL:
#print(u)
[ask,answer] = Get_info(u)
if len(ask) > 1:
ask = """'%s'""" %ask
answer = """'%s'""" %answer
date = [ask,answer]
Load_date(db,date)
time.sleep(1)
print("第" + str(i+1) + "页获取完毕!")
time.sleep(3) db.close() if __name__ == '__main__':
main()
python3爬取百度知道的问答并存入数据库(MySQL)的更多相关文章
- 从0开始学爬虫8使用requests/pymysql和beautifulsoup4爬取维基百科词条链接并存入数据库
从0开始学爬虫8使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 Python使用requests和beautifulsoup4爬取维基百科词条链接并存入数据库 参考 ...
- python3爬取百度图片(2018年11月3日有效)
最终目的:能通过输入关键字进行搜索,爬取相应的图片存储到本地或者数据库 首先打开百度图片的网站,搜索任意一个关键字,比如说:水果,得到如下的界面 分析: 1.百度图片搜索结果的页面源代码不包含需要提取 ...
- Python3爬取百度百科(配合PHP)
用PHP写了一个网页,可以获取百度百科词条.源代码已分享至github:https://github.com/1049451037/xiaobaike/tree/master 那么通过Python来爬 ...
- <爬虫>利用BeautifulSoup爬取百度百科虚拟人物资料存入Mysql数据库
网页情况: 代码: import requests from requests.exceptions import RequestException from bs4 import Beautiful ...
- NodeJs简单七行爬虫--爬取自己Qzone的说说并存入数据库
没有那么难的,嘿嘿,说起来呢其实挺简单的,或者不能叫爬虫,只需要将自己的数据加载到程序里再进行解析就可以了,如果说你的Qzone是向所有人开放的,那么就有一个JSONP的接口,这么说来就简单了,也就不 ...
- python爬虫爬取ip记录网站信息并存入数据库
import requests import re import pymysql #10页 仔细观察路由 db = pymysql.connect("localhost",&quo ...
- python网络爬虫抓取动态网页并将数据存入数据库MySQL
简述以下的代码是使用python实现的网络爬虫,抓取动态网页 http://hb.qq.com/baoliao/ .此网页中的最新.精华下面的内容是由JavaScript动态生成的.审查网页元素与网页 ...
- Python3实现QQ机器人自动爬取百度文库的搜索结果并发送给好友(主要是爬虫)
一.效果如下: 二.运行环境: win10系统:python3:PyCharm 三.QQ机器人用的是qqbot模块 用pip安装命令是: pip install qqbot (前提需要有request ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
随机推荐
- C# WPF 表单更改提示
微信公众号:Dotnet9,网站:Dotnet9,问题或建议,请网站留言: 如果您觉得Dotnet9对您有帮助,欢迎赞赏 C# WPF 表单更改提示 内容目录 实现效果 业务场景 编码实现 本文参考 ...
- script标签的async和defer
兼容性 IE对于defer一直都支持,async属性IE6-9都没有支持,IE10及以上支持 相同点与不同点 带有async或defer的script都会立刻下载并不阻塞页面解析,而且都提供一个可选的 ...
- PAT (Advanced Level) Practice 1015 Reversible Primes (20 分)
A reversible prime in any number system is a prime whose "reverse" in that number system i ...
- 树莓派环境下使用python将h264格式的视频转为mp4
个人博客 地址:https://www.wenhaofan.com/a/20190430144809 下载安装MP4Box 命令行下执行以下指令安装MP4Box sudo apt-get inst ...
- 0级搭建类005-Oracle Solaris Unix安装 (11.4) 公开
项目文档引子系列是根据项目原型,制作的测试实验文档,目的是为了提升项目过程中的实际动手能力,打造精品文档AskScuti. 项目文档引子系列目前不对外发布,仅作为博客记录.如学员在实际工作过程中需提前 ...
- 摇一摇—微信7.0.8版本audio无法自动播放问题
近日有一个项目出现audio无法自动播放,查看原因才发现是微信版本更新为7.0.8版本,需要有交互行为,第一次播放需要用户手动点击一下,无法使用DOM中的play()进行直接播放操作,那怎么办呢? 通 ...
- 2017-9-15Opencv 杂
Mat::at()的具体含义.指的是三通道.(0),(1),(2)分别表示BGR: Vector<Mat>结构的使用.将Mat类型的数据转化成了具有多个单通道的容器? 灰度图的具体含义.和 ...
- 原生js实现拖拽功能
1. 给个div,给定一些样式 <div class="drag" style="left:0;top:0;width:100px;height:100px&quo ...
- VUE 路由参数改变重新刷新数据
VUE 路由参数改变重新刷新数据 App.vue 里面使用路由,然后通过App.vue文件中的搜索功能搜索刷新路由文件中的列表. 修改 index.js 文件 首先在路由文件 index.js 文件中 ...
- 判断是否网络连通 .net Ping
using System; using System.Collections.Generic; using System.Diagnostics; using System.Linq; using S ...