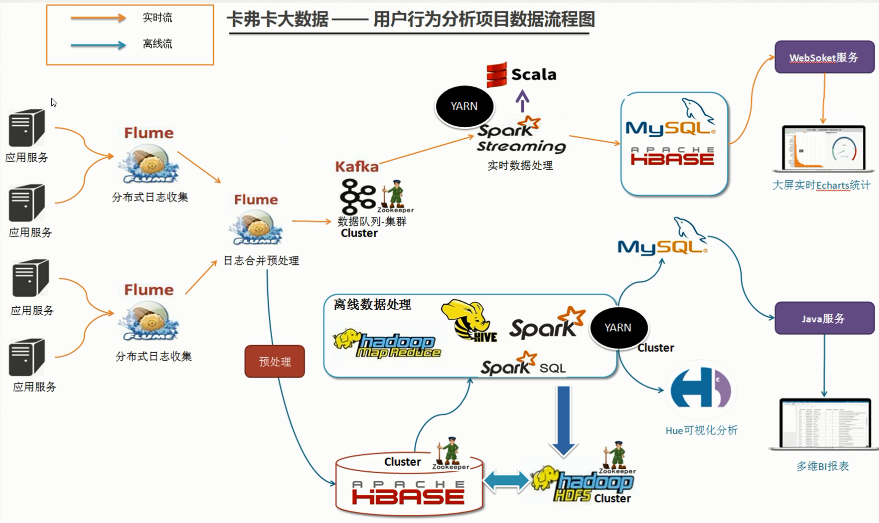
新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备
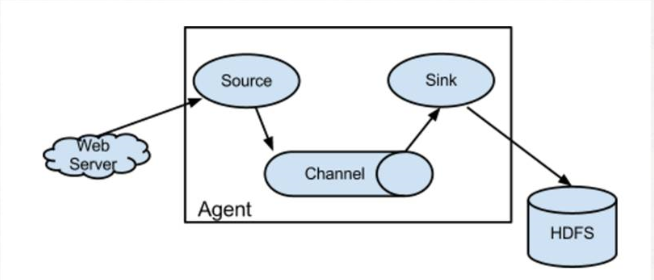
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.flume节点服务设计
2.下载Flume并安装
1)下载Apache版本的Flume。
2)下载Cloudera版本的Flume。
3)这里选择下载Apache版本的apache-flume-1.7.0-bin.tar.gz ,然后上传至bigdata-pro01.kfk.com节点/opt/softwares/目录下
4)解压Flume
tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/modules/
5)将flume分发到其他两个节点
scp -r flume-1.7.0-bin bigdata-pro02.kfk.com:/opt/modules/
scp -r flume-1.7.0-bin bigdata-pro03.kfk.com:/opt/modules/
3.flume agent-1采集节点服务配置
1)bigdata-pro02.kfk.com节点配置flume,将数据采集到bigdata-pro01.kfk.com节点
vi flume-conf.properties
agent2.sources = r1
agent2.channels = c1
agent2.sinks = k1
agent2.sources.r1.type = exec
agent2.sources.r1.command = tail -F /opt/datas/weblogs.log
agent2.sources.r1.channels = c1
agent2.channels.c1.type = memory
agent2.channels.c1.capacity = 10000
agent2.channels.c1.transactionCapacity = 10000
agent2.channels.c1.keep-alive = 5
agent2.sinks.k1.type = avro
agent2.sinks.k1.channel = c1
agent2.sinks.k1.hostname = bigdata-pro01.kfk.com
agent2.sinks.k1.port = 5555
2)bigdata-pro03.kfk.com节点配置flume,将数据采集到bigdata-pro01.kfk.com节点
vi flume-conf.properties
agent3.sources = r1
agent3.channels = c1
agent3.sinks = k1
agent3.sources.r1.type = exec
agent3.sources.r1.command = tail -F /opt/datas/weblogs.log
agent3.sources.r1.channels = c1
agent3.channels.c1.type = memory
agent3.channels.c1.capacity = 10000
agent3.channels.c1.transactionCapacity = 10000
agent3.channels.c1.keep-alive = 5
agent3.sinks.k1.type = avro
agent3.sinks.k1.channel = c1
agent3.sinks.k1.hostname = bigdata-pro01.kfk.com
agent3.sinks.k1.port = 5555
新闻网大数据实时分析可视化系统项目——8、Flume数据采集准备的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
随机推荐
- 【JavaWeb+Echarts+EL表达式】用图表形式展示数据
1. Echarts环境配置 https://www.echartsjs.com/zh/download.html 选择需要的,然后等待Build完成之后,就会自动弹出下载框啦! 把下载好的js放在w ...
- 惠普笔记本,如何选择U盘启动
开机先连续点击键盘F9按键进入选择启动盘界面,找到自己的U盘(KingstonDataTraveler G3)
- C# worksheet设置Excel样式(转载)
1.例子导出Excel的样式public void Exportdatagridviewtoexcel(string Textname) { SaveFileDialog savedialog = n ...
- 操作系统OS - 阻塞(Blocking)非阻塞(Non-Blocking)与同步(Synchronous)异步(Asynchronous)
参考: http://blog.jobbole.com/103290/ https://www.zhihu.com/question/19732473/answer/23434554 http://b ...
- 根据权限显示accordion
前端界面: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="Home.asp ...
- Protobuf协议--java实现
Protobuf协议,全称:Protocol Buffer 它跟JSON,XML一样,是一个规定好的数据传播格式.不过,它的序列化和反序列化的效率太变态了…… 来看看几张图你就知道它有多变态. pr ...
- sqlmap注入随笔记录
web7: 首先看见这道题,猜测flag在某页id上面,或者id是可以注入的. 先就是id爆破,用burpsuite抓了包,做了个0~9999的字典爆破id,发现自己猜测错了 那么就还是sql注入题了 ...
- jQuery结合CSS实现手风琴组件
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 7-10 多项式A除以B (25分)(多项式除法)
7-10 多项式A除以B (25分) 这仍然是一道关于A/B的题,只不过A和B都换成了多项式.你需要计算两个多项式相除的商Q和余R,其中R的阶数必须小于B的阶数. 输入格式: 输入分两行,每行给出 ...
- __str__()方法和__repr__()方法
有时候我们想让屏幕打印的结果不是对象的内存地址,而是它的值或者其他可以自定义的东西,以便更直观地显示对象内容,可以通过在该对象的类中创建或修改__str__()或__repr__()方法来实现(显示对 ...