(数据科学学习手札107)在Python中利用funct实现链式风格编程
本文示例代码已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
链式编程是一种非常高效的组织代码的方式,典型如pandas与scikit-learn中的pipe(),以及R中的管道操作符%>%等,它们都可以帮助我们像连接管道一样,将计算过程中的不同步骤顺滑的连接起来,从而取代繁琐的函数嵌套以及避免多余中间变量的创建。
 图1
图1
链式编程与常规写法的比较如下例:
# 非链式写法
func4(func3(func2(func1(A))))
# 链式写法
A.func1().func2().func3().func4()
哪一种写法更简洁明了,想必大家一眼就看得出来,而今天的文章就将带大家认识如何借助funct的力量,来改造Python原生列表,赋予其链式计算的能力。
2 利用funct.Array实现链式计算
funct的设计理念就是类似Python列表但更棒,它借鉴了numpy的很多特点,配合功能丰富的各种链式计算方法,使得我们在使用它完成计算任务编写代码如丝般顺滑时~
利用pip install funct完成安装(本文演示版本为0.9.2)之后,下面我们来认识它的一些优秀特性吧~
2.1 funct.Array的创建
funct中类比列表和numpy中的数组,创造了Array这种特别的数据结构,常用的有如下几种创建方式:
- 从其他数据结构创建
最常规的方式是从现有的其他数据结构,转换到Array,常见如下面的几个例子:
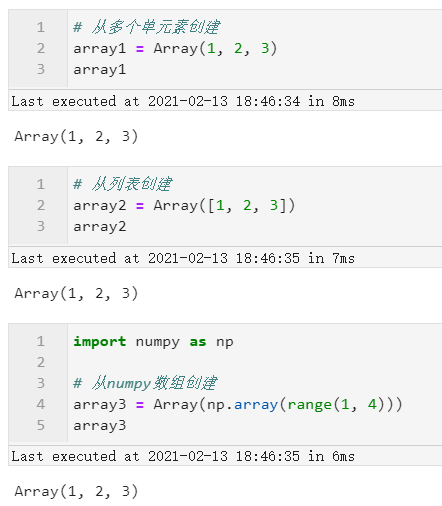 图2
图2
- 类似numpy风格的规则创建方法
除了从现成的数据中创建Array之外,我们还可以类似numpy中的linspace()等API那样,基于规则批量创建数据,常用的有如下两种方法:
 图3
图3
- 创建嵌套Array
既然是建立在列表的基础上,那么funct对嵌套Array尤其是不规则嵌套Array的支持也是很到位的:
 图4
图4
但在配合多个numpy数组构建嵌套Array时要注意,最后一定要加上toArray()方法才能彻底完成转换:
 图5
图5
2.2 funct.Array的索引
大致介绍完如何创建funct.Array之后,很重要的一点就是如何对已有Array进行索引,在funct中针对Array设计了如下几种丰富的索引方式:
- 列表式索引
既然继承自列表,自然可以使用Python原生列表的索引与切片方式:
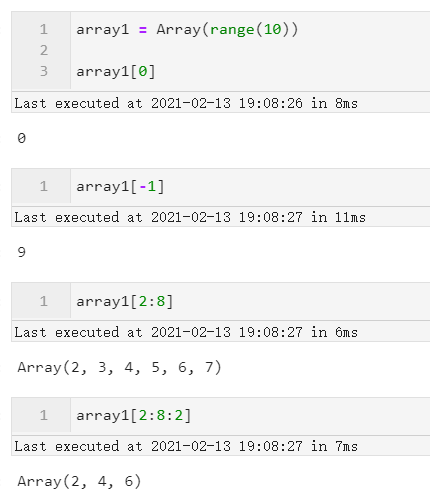 图6
图6
- 数组式索引
我们都知道Python原生列表不能传入一系列标号对应的数组来一次性索引出多个值,除非转换为numpy数组或pandas的Series,但这又会在一些应用场景下丢失灵活性,但在Array中,它可以!
 图7
图7
- Bool值索引
Array同样支持传入Bool值索引,使得我们可以将某个条件判断之后的判断结果作为索引依据传入:
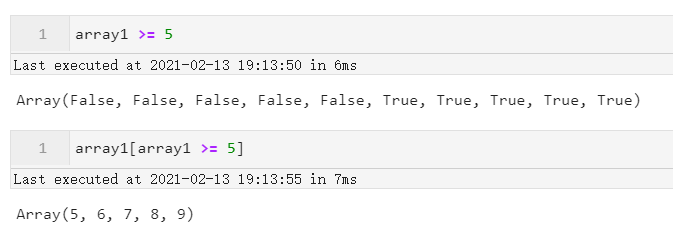 图8
图8
- 多层索引
既然Array是支持嵌套结构的,自然可以进行多层索引,但需要注意的是:
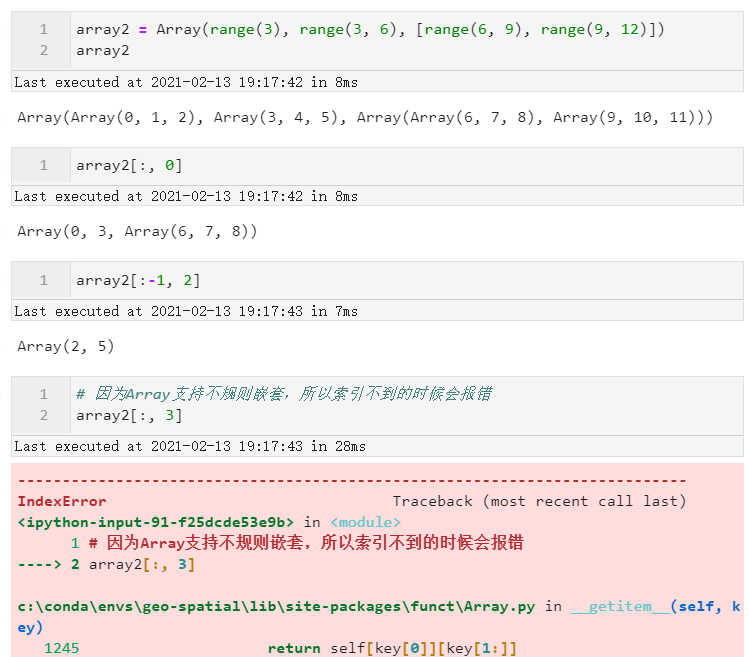 图9
图9
2.3 funct.Array的链式骚操作
讲完了如何创建与索引funct.Array之后,就来到了本文的重头戏——Array的链式运算上,在funct.Array中,几乎所有常见的数值与逻辑运算都被封装到方法中,我们来一阶一阶的来看看不同情况下如何组织代码:
- level1:基础的数值运算
首先我们来看看最基础的四则运算等操作在Array中如何链式下去:
 图10
图10
这样每一步都很清楚,且每一步都可以独立添加注释,保持了代码的可读性,譬如可用于归一化与标准化的计算上:
 图11
图11
- level2:配合map方法推广元素级别运算
除了使用内置的基础的运算方法之外,在funct.Array中还支持配合map()方法将任意函数应用到每个元素上,从而无限拓宽计算的自由性,譬如我们在前面归一化的基础上对数据进行分箱:
 图12
图12
- level3:配合zip方法引入其他Array参与运算
当我们想要在链式运算中引入其他数组对象时,就可以用到更高级的zip()方法,譬如我们想找出多个Array中相同位置最大值:
 图13
图13
- level4:条件分组
在pandas中我们可以利用groupby()进行数据分箱并衔接任意形式的运算,在funct.Array中我们也可以配合groupBy()方法实现:
 图14
图14
而除了本文介绍到的这一点API之外,funct还提供了上百种实用API,并且还具有并行执行与并发执行等高级特性,感兴趣的朋友可以前往官方文档查看( https://github.com/Lauriat/funct )。
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札107)在Python中利用funct实现链式风格编程的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札126)Python中JSON结构数据的高效增删改操作
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一期文章中我们一起学习了在Python ...
- (数据科学学习手札136)Python中基于joblib实现极简并行计算加速
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在日常使用Python进行各种数据计算 ...
- (数据科学学习手札53)Python中tqdm模块的用法
一.简介 tqdm是Python中专门用于进度条美化的模块,通过在非while的循环体内嵌入tqdm,可以得到一个能更好展现程序运行过程的提示进度条,本文就将针对tqdm的基本用法进行介绍. 二.基本 ...
- (数据科学学习手札54)Python中retry的简单用法
一.简介 retry是一个用于错误处理的模块,功能类似try-except,但更加快捷方便,本文就将简单地介绍一下retry的基本用法. 二.基本用法 retry: 作为装饰器进行使用,不传入参数时功 ...
- (数据科学学习手札90)Python+Kepler.gl轻松制作时间轮播图
本文示例代码及数据已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 Kepler.gl作为一款强大的开源地理信 ...
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札109)Python+Dash快速web应用开发——静态部件篇(中)
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
随机推荐
- 微服务网关2-搭建Gateway服务
一.创建父模块infrastructure 1.创建模块 在guli_parent下创建普通maven模块 Artifact:infrastructure 2.删除src目录 二.创建模块api_ga ...
- mysql半同步复制跟无损半同步区别
mysql半同步复制跟无损半同步复制的区别: 无损复制其实就是对semi sync增加了rpl_semi_sync_master_wait_point参数,来控制半同步模式下主库在返回给会话事务成功之 ...
- 提示框,对话框,路由跳转页面,跑马灯,幻灯片及list组件的应用
目录: 主页面的js业务逻辑层 主页面视图层 主页面css属性设置 跳转页面一的js业务逻辑层 跳转页面一的视图层 跳转页面二的视图层 跳转页面三的js业务逻辑层 跳转页面三的视图层 跳转页面三的cs ...
- 翻页bug 在接口文档中应规范参数的取值区间 接口规范
<?php$a=array("red","green","blue","yellow","brown&q ...
- 【rz】【sz】参数详解
参数 SYNOPSIS sz [-+8abdefkLlNnopqTtuvyY] file ... b:以二进制方式,默认为文本方式 e:对所有控制字符转义 待续 常见问题: 1.xshell 使用rz ...
- Spark JDBC系列--取数的四种方式
Spark JDBC系列--取数的四种方式 一.单分区模式 二.指定Long型column字段的分区模式 三.高自由度的分区模式 四.自定义option参数模式 五.JDBC To Other Dat ...
- NoSQL:一个帝国的崛起
01关系数据库帝国 现在是公元2009年,关系帝国已经统治了我们30多年,实在是太久了. 1970年,科德提出关系模型,1974年张伯伦和博伊斯制造出了SQL ,帝国迅速建立起了统治. 从北美到欧洲, ...
- idea--忽略隐藏文件、文件夹的设置操作
文章由来 公司同事在群里问了个问题,如下: 为了大家看清,将图特意贴出来: 这人还删除idae重装了下,哈哈,才到群里问的. 解决思路(按顺序) 1.我让他直接拉会,共享桌面我给看了下,首先是open ...
- 从ReentrantLock实现非公平锁的源码理解AQS中的CLH队列
虽然前面也看过AQS的文章,并且转载过一篇大佬的分析,但是我觉得他们对于AQS和ReentrantLock部分的源码的分析并不详细,自己理解期来还是有问题,于是自己准备花时间重新梳理下,好了,进入正题 ...
- jvm系列二内存结构
二.内存结构 整体架构 1.程序计数器 作用 用于保存JVM中下一条所要执行的指令的地址 特点 线程私有 CPU会为每个线程分配时间片,当当前线程的时间片使用完以后,CPU就会去执行另一个线程中的代码 ...