python3爬虫-爬取新浪新闻首页所有新闻标题
准备工作:安装requests和BeautifulSoup4。打开cmd,输入如下命令
pip install requests
pip install BeautifulSoup4打开我们要爬取的页面,这里以新浪新闻为例,地址为:http://news.sina.com.cn/china/
按F12打开开发人员工具,点击左上角的图片,然后再页面中点击你想查看的元素:
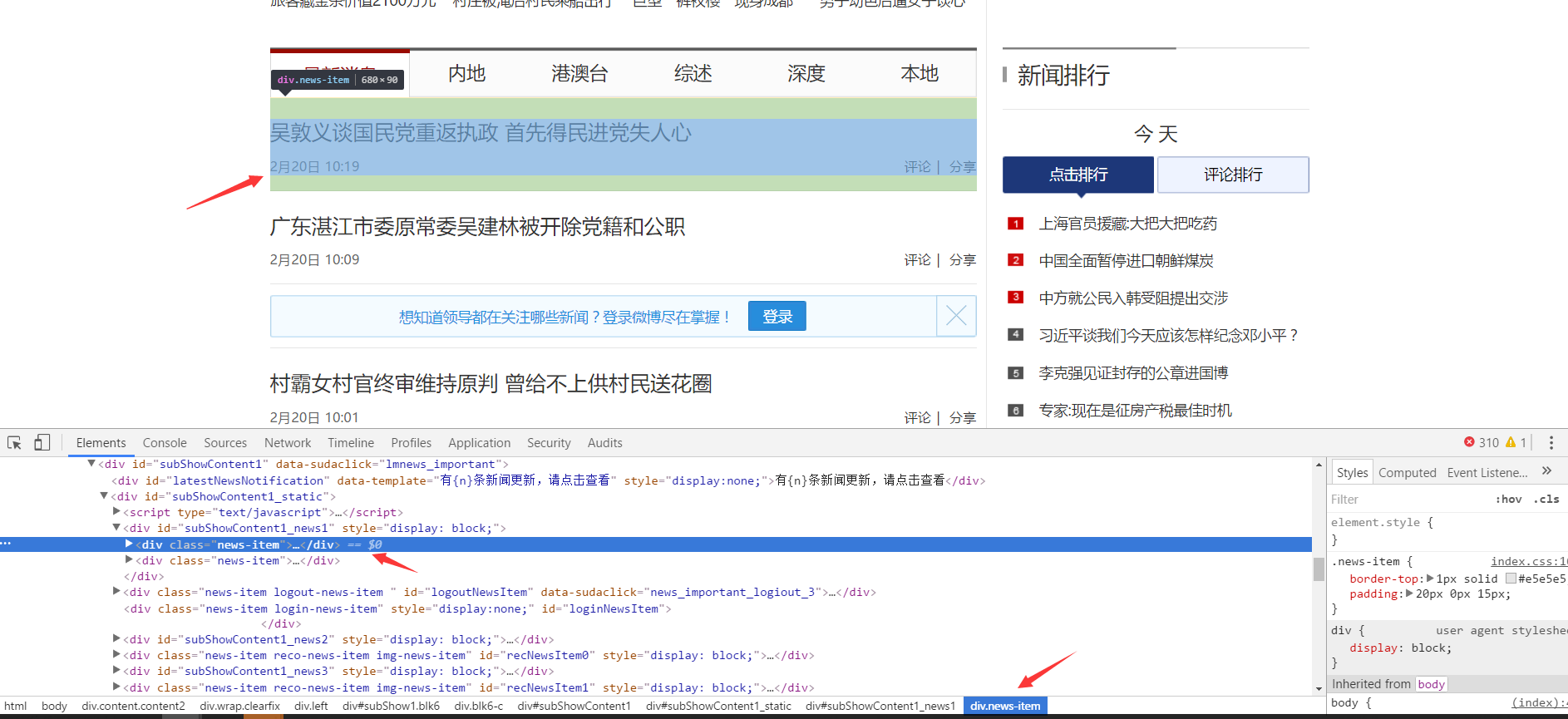
我点击了新闻标题处的元素,查看到该元素为class=news-item的元素:
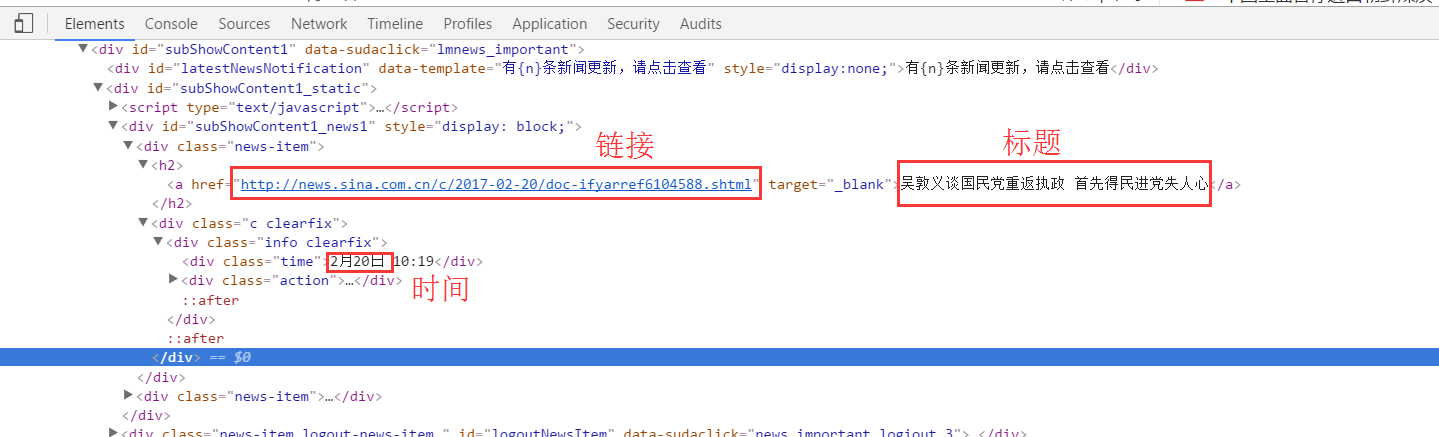
在这里,我们要获取新闻的时间,标题和链接,查看到分别在如下位置:
现在,就可以根据元素的结构编写爬虫代码了:
import requests
from bs4 import BeautifulSoup
url = 'http://news.sina.com.cn/china/'
res = requests.get(url)
# 使用UTF-8编码
res.encoding = 'UTF-8'
# 使用剖析器为html.parser
soup = BeautifulSoup(res.text, 'html.parser')
#遍历每一个class=news-item的节点
for news in soup.select('.news-item'):
h2 = news.select('h2')
#只选择长度大于0的结果
if len(h2) > 0:
#新闻时间
time = news.select('.time')[0].text
#新闻标题
title = h2[0].text
#新闻链接
href = h2[0].select('a')[0]['href']
#打印
print(time, title, href)运行程序,结果如下图所示:

python3爬虫-爬取新浪新闻首页所有新闻标题的更多相关文章
- Python3:爬取新浪、网易、今日头条、UC四大网站新闻标题及内容
Python3:爬取新浪.网易.今日头条.UC四大网站新闻标题及内容 以爬取相应网站的社会新闻内容为例: 一.新浪: 新浪网的新闻比较好爬取,我是用BeautifulSoup直接解析的,它并没有使用J ...
- 【python3】爬取新浪的栏目分类
目标地址: http://www.sina.com.cn/ 查看源代码,分析: 1 整个分类 在 div main-nav 里边包含 2 分组情况:1,4一组 . 2,3一组 . 5 一组 .6一组 ...
- selenium+BeautifulSoup+phantomjs爬取新浪新闻
一 下载phantomjs,把phantomjs.exe的文件路径加到环境变量中,也可以phantomjs.exe拷贝到一个已存在的环境变量路径中,比如我用的anaconda,我把phantomjs. ...
- python3爬虫爬取网页思路及常见问题(原创)
学习爬虫有一段时间了,对遇到的一些问题进行一下总结. 爬虫流程可大致分为:请求网页(request),获取响应(response),解析(parse),保存(save). 下面分别说下这几个过程中可以 ...
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- Python 爬虫实例(7)—— 爬取 新浪军事新闻
我们打开新浪新闻,看到页面如下,首先去爬取一级 url,图片中蓝色圆圈部分 第二zh张图片,显示需要分页, 源代码: # coding:utf-8 import json import redis i ...
- python2.7 爬虫初体验爬取新浪国内新闻_20161130
python2.7 爬虫初学习 模块:BeautifulSoup requests 1.获取新浪国内新闻标题 2.获取新闻url 3.还没想好,想法是把第2步的url 获取到下载网页源代码 再去分析源 ...
- python3使用requests爬取新浪热门微博
微博登录的实现代码来源:https://gist.github.com/mrluanma/3621775 相关环境 使用的python3.4,发现配置好环境后可以直接使用pip easy_instal ...
- python3 爬虫---爬取糗事百科
这次爬取的网站是糗事百科,网址是:http://www.qiushibaike.com/hot/page/1 分析网址,参数''指的是页数,第二页就是'/page/2',以此类推... 一.分析网页 ...
随机推荐
- [JS] 如何自定义字符串格式化输出
在其他语言中十分常见的字符串格式化输出,居然在 Javascript 中不见踪影,于是决定自己实现该方法,以下就是个人编写的最简洁实现: String.prototype.format = funct ...
- js for循环与for in循环的区别
for循环可一遍历数组,而for in循环可以遍历数组和对象 使用for in循环会将Array当成对象遍历,而Array的存取速度明显比Object要快.所以使用for循环遍历数组比for in循环 ...
- SVN的基本原理 配置自动更新WEB服务器
SVN的基本原理 配置自动更新WEB服务器 最近有个小项目,需要用SVN来进行版本控制.项目组的同僚有8个人,大家都在本地开发,然后提交到服务器——服务器就是其中一台机器.专门安排一个测试员来进行项目 ...
- WP8.1学习系列(第四章)——交互UX之导航模式
交互模式和指南 这部分包括三部分内容,分别是导航模式.命令模式和输入模式. 导航模式 虽然 Windows 导航模式提供了框架,但它提倡创新.激发你的创造力并在已建立的模式上构建. 命令模式 使用应用 ...
- 【Linux】python 2.x 升级 python3.x 之后 yum命令出现except OSError, e: ^ SyntaxError: invalid syntax
python2.7升级到python3.6.4 文章链接 : https://zhuanlan.zhihu.com/p/33660059 我在服务器上.把linux默认安装的python2.7 升级 ...
- python错误 ImportError: No module named setuptools 解决方法[转]
在python运行过程中出现如下错误: python错误:ImportError: No module named setuptools这句错误提示的表面意思是:没有setuptools的模块,说明p ...
- c++ 纯虚析构函数
; 这就是一个纯虚析构函数,这种定义是允许的. 一般纯虚函数都不允许有实体,但是因为析构一个类的过程中会把所有的父类全析构了,所以每个类必有一个析构函数. 所以.纯虚析构函数需要提供函数的实现,而一般 ...
- 遍历json数组实现树
今天小颖在工作中遇到要遍历树得问题了,实现后,怕后期遇到又忘记啦,所以记录下嘻嘻,其实这个和小颖之前写过得一篇文章 json的那些事 中第4点有关json的面试题有些类似. 数组格式: v ...
- python nose测试框架全面介绍八---接口测试中非法参数的断言
在测接口时,会有这样的场景,输入非法的参数,校验返回的错误码及错误内容 通常做法为发请求,将错误的返回结果拿出,再进行对比匹配:但存在一个问题,需要再写错误返回分析函数,不能与之前正常发请求的函数共用 ...
- CentOS 6 安装python3.6
参考博客:https://www.cnblogs.com/xiaodangshan/p/7197563.html 安装过程比较简单,需要注意,安装之后,为了不影响系统自带的python2.6版本,需要 ...