python +requests 爬虫-爬取图片并进行下载到本地
- 爬虫实现方式:
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。

- 环境 :
- python
- re
- requests
- 正则:
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
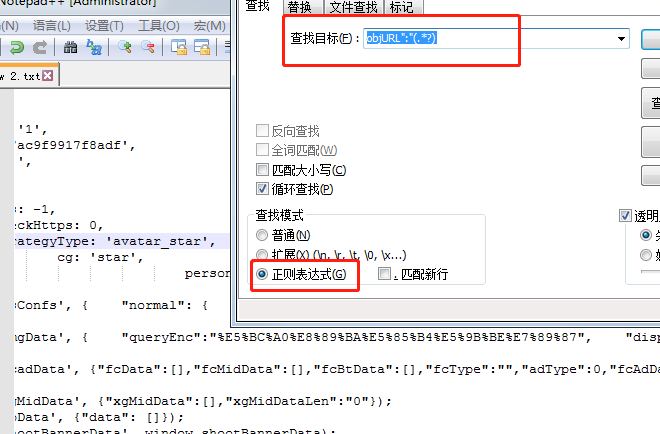
- 小技巧:这边的正则如果你不太确定有没有匹配到的话可以使用notepad++来匹配下
- 第一步查看你需要抓取网页右击查看源代码
- 第二步把代码贴入notepad++中
- 第三步f12查询选择正则进行匹配
- 也可用这个网址:http://tool.oschina.net/regex/#
- 废话不多说直接上代码
import re
import requests def download(html):
#通过正则匹配
pic_url = re.findall('"objURL":"(.*?)",',html, re.S)
i = 1
for key in pic_url:
print("开始下载图片:"+key +"\r\n")
try:
pic = requests.get(key, timeout=10)
except requests.exceptions.ConnectionError:
print('图片无法下载')
continue
#保存图片路径
dir = '保存路径' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
def main():
url = 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&sf=1&fmq=&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&fm=index&pos=history&word=lay'
result = requests.get(url)
download(result.text) if __name__ == '__main__':
main()
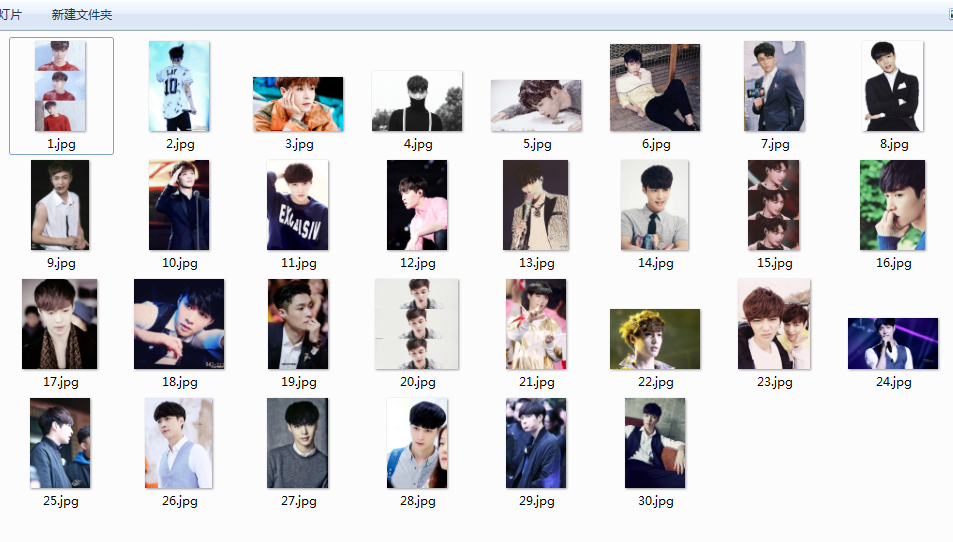
- 最后找到你下载图片的文件,然后看下小绵羊的盛世美颜
python +requests 爬虫-爬取图片并进行下载到本地的更多相关文章
- python网络爬虫&&爬取图片
爬取学院官网数据from urllib.request import * #导入所有request urllib文件夹,request只是里面的一个模块from lxml import etree # ...
- Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片
Python 实用爬虫-04-使用 BeautifulSoup 去水印下载 CSDN 博客图片 其实没太大用,就是方便一些,因为现在各个平台之间的图片都不能共享,比如说在 CSDN 不能用简书的图片, ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 使用Scrapy爬取图片入库,并保存在本地
使用Scrapy爬取图片入库,并保存在本地 上 篇博客已经简单的介绍了爬取数据流程,现在让我们继续学习scrapy 目标: 爬取爱卡汽车标题,价格以及图片存入数据库,并存图到本地 好了不多说,让我们实 ...
- [python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度.搜狗.googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨.同时 ...
- Python 爬虫 爬取图片入门
爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 用户看到的网页实质是由 HTML 代码构成的,爬 ...
- 一篇文章教会你利用Python网络爬虫获取电影天堂视频下载链接
[一.项目背景] 相信大家都有一种头疼的体验,要下载电影特别费劲,对吧?要一部一部的下载,而且不能直观的知道最近电影更新的状态. 今天小编以电影天堂为例,带大家更直观的去看自己喜欢的电影,并且下载下来 ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
随机推荐
- Leetcode Lect4 二叉树中的分治法与遍历法
在这一章节的学习中,我们将要学习一个数据结构——二叉树(Binary Tree),和基于二叉树上的搜索算法. 在二叉树的搜索中,我们主要使用了分治法(Divide Conquer)来解决大部分的问题. ...
- ASP.NET中Literal控件的使用方法(用于向网页中动态添加内容)
原文:https://www.jb51.net/article/82855.htm 可以将 Literal 控件用作网页上其他内容的容器.Literal 控件最常用于向网页中动态添加内容.简单的讲,就 ...
- echart 折线渐变 加柱形图结合图形,左右纵轴自设置格式,现行图北京渐变 ,x轴字体倾斜
app.title = '折柱混合'; option = { grid: { left: '5%', //距离左边的距离 right: '5%', //距离右边的距离 top:'8%', bottom ...
- Storm简介——实时流式计算介绍
概念 实时流式计算: 大数据环境下,流式数据将作为一种新型的数据类型,这种数据具有连续性.无限性和瞬时性.是实时数据处理所面向的数据类型,对这种流式数据的实时计算就是实时流式计算. 特征 实时流式计算 ...
- postgresql Streaming Replication监控与注意事项
一监控Streaming Replication集群 1 pg_stat_replication视图(主库端执行) pid Wal sender process的进程ID usesysid 执行流复制 ...
- rename 重命名文件
1. 使用范例 范例1: 批量修改文件名 [root@localhost data]# touch {a,b,c,d,e}.txt [root@localhost data]# ls a.txt ...
- alert(1) to win 4
function escape(s) { var url = 'javascript:console.log(' + JSON.stringify(s) + ')'; console.log(url) ...
- 学习旧岛小程序 (1) flex 布局
css : view 相当于 div 块级元素 display 默认设置 block display:inline 设置后 设置宽度高度是无效的 要设置宽度高度 又要设置为行内元素 我们设置: (1) ...
- linux文档和目录结构
Linux文件系统结构 Linux通过操作目录来实现对磁盘的读写.Linux通过使用正斜杠" / "来表示目录. Linux通过建立一个根目录,所有的目录都是通过根目录衍生出来的. ...
- struts2+jsp 遍历 <s:iterator><s:property>
直接把list用request传到jsp页面 <s:iterator var="u" value="#request.users"> <tr& ...