一文详解云上自动化部署集群管理工具 Nebula Operator

本文首发于 Nebula Graph 公众号:Nebula Operator 开源啦!一文详解这个云上自动化部署集群管理工具
在介绍 Nebula Operator 之前,让我们先来了解下什么是 Operator。
Operator 是一种封装、部署和管理 Kubernetes 应用的方法,通过扩展 Kubernetes API 的功能,来管理用户创建、配置和管理复杂应用的实例。它基于自定义资源 CRD 和控制器概念构建,涵盖了特定领域或应用的知识,用于实现其所管理软件的整个生命周期的自动化。
在 Kubernetes 中,控制平面的控制器实施控制循环,反复比较集群的期望状态和实际状态。如果集群的实际状态与期望状态不符,控制器将继续协调内部业务逻辑直到应用更新为期望状态。
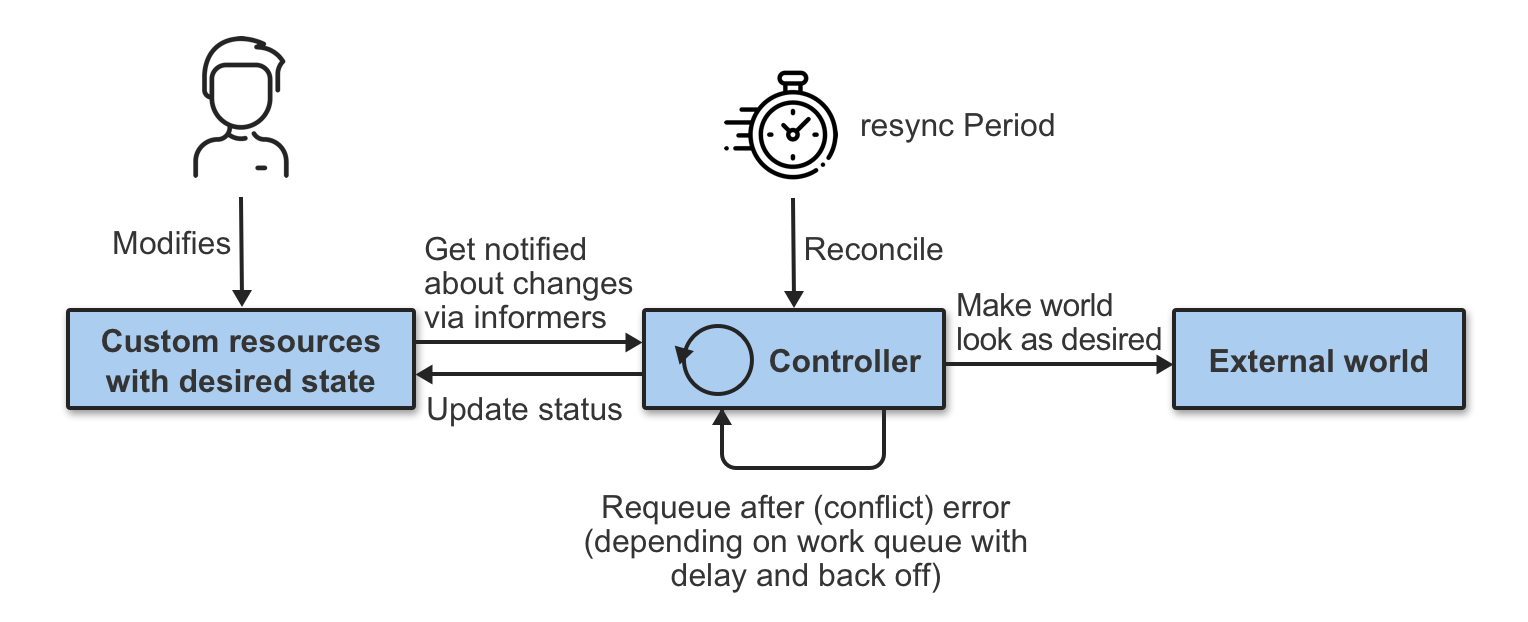
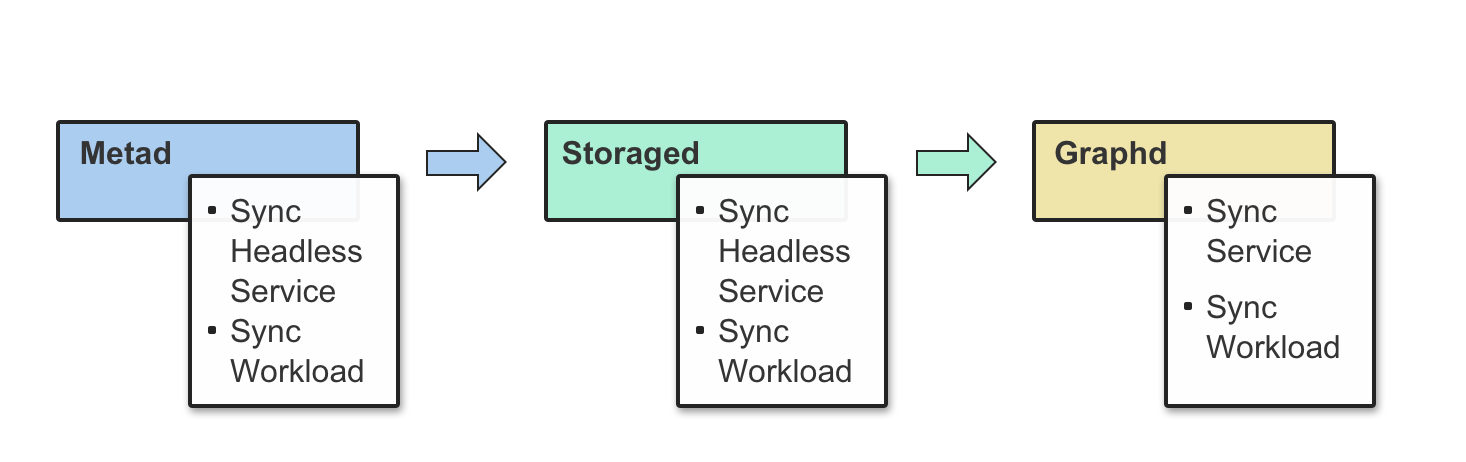
Nebula Operator 将 NebulaGraph 的部署管理抽象成自定义资源 CRD,通过 StatefulSet、Service、ConfigMap 等多个内置的 API 对象组合在一起,把日常管理维护 Nebula Graph 的流程编写成控制循环,当 CR 实例提交时,Nebula Operator 按照控制流程驱动数据库集群向终态转移。
Nebula Operator 功能介绍
CRD 定义
下面结合部署 nebula 集群的 CR 文件,来了解下 Nebula Operator 的核心功能。
apiVersion: apps.nebula-graph.io/v1alpha1
kind: NebulaCluster
metadata:
name: nebula
namespace: default
spec:
graphd:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 1
image: vesoft/nebula-graphd
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
metad:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 1
image: vesoft/nebula-metad
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
storaged:
resources:
requests:
cpu: "500m"
memory: "500Mi"
replicas: 3
image: vesoft/nebula-storaged
version: v2.0.0
storageClaim:
resources:
requests:
storage: 2Gi
storageClassName: gp2
reference:
name: statefulsets.apps
version: v1
schedulerName: default-scheduler
imagePullPolicy: IfNotPresent
spec 里需要重点关注三个描述部分:graphd、metad、storaged,他们分别表示 Graph 服务、Meta 服务、Storage 服务,控制器会在协调循环里依次检查内置的 API 对象 StatefulSet、Service、ConfigMap 是否就绪,假如某个依赖的 API 对象没有创建成功或者某个 Nebula Graph 组件服务协调异常,控制器就会结束返回,等待下一次协调,并重复这个过程。
目前 CRD 里提供的配置参数还不够丰富,只覆盖了最核心的 resource、replicas、image、schedulerName 等运行过程中必不可少的配置参数,未来 Nebula Operator 会根据使用场景进一步丰富配置参数。
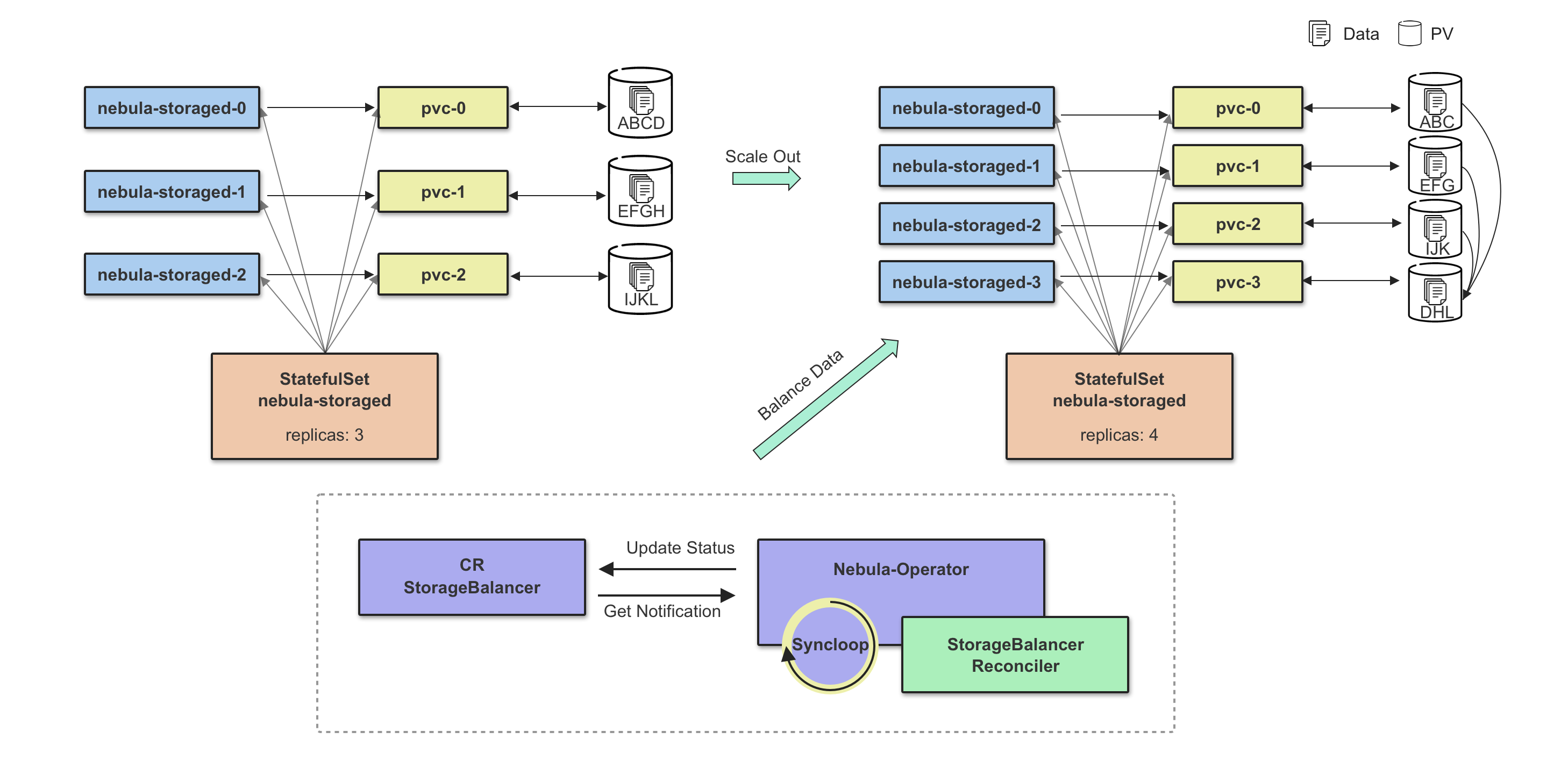
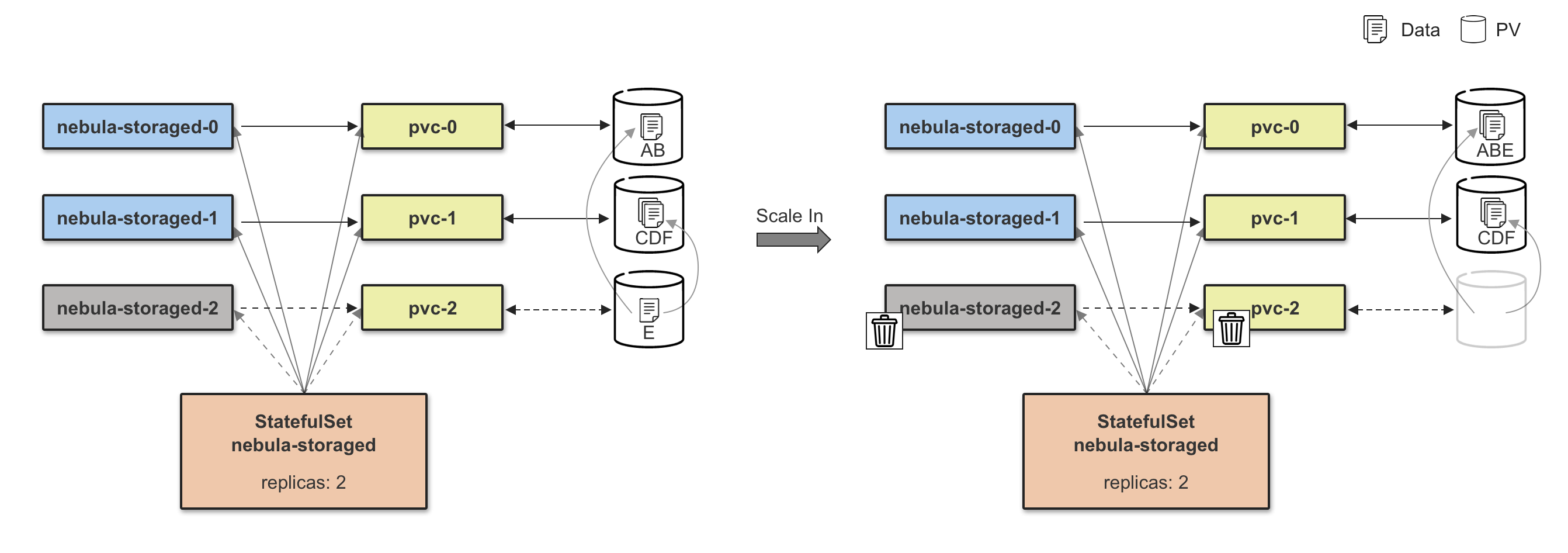
扩缩容
Storage 扩容分为两个阶段,第一个阶段需要等待所有新增扩容的 Pod 状态为 Ready,第二个阶段执行数据 Balance Data 操作,数据 Balance 的任务由 CRD StorageBalancer 定义,这里将控制器副本的扩容流程跟数据 Balance 流程解耦,可以实现数据 Balance 任务的定制化,比如:添加任务执行时间,在业务流量较低时执行,可有效减小数据迁移对于线上服务的影响,这也符合 Nebula Graph 本身的设计理念:没有采用完全自动化 Balance 方式,Balance 时机由用户自己控制。
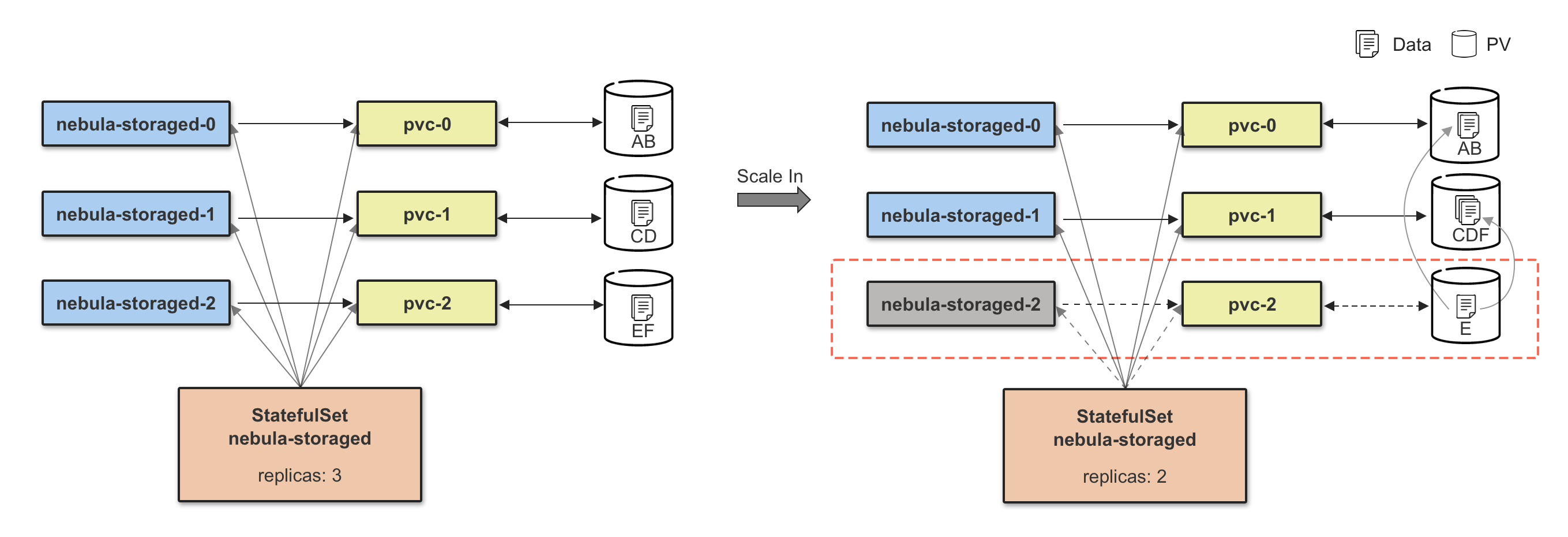
Storage 缩容和扩容是一个相反的过程,缩容前需要安全移除节点,内部对应的就是 BALANCE DATA REMOVE $host_list 指令,等待移除节点任务完成后,再执行 Storage Pod 的缩容操作。
注:下图只做解释说明,不做真实配置参考,在高可用场景下,需要保证 3 副本实例在线。
调度均衡
在调度部分,Nebula Operator 提供了两种选择,可以使用默认调度器或者基于 scheduler extender 接口的调度器。
默认调度器的拓扑分布约束可以控制 Pod 在集群拓扑域内均匀分布,Nebula Operator 提供了默认的节点标签 kubernetes.io/hostname 的均匀分布,未来会支持自定义节点标签配置。这里没有选择基于亲和性调度策略主要是因为亲和性本质上是控制 Pod 如何被堆叠或是打散,PodAffinity 是将多个 Pod 调度到特定的拓扑域,这是堆叠调度;PodAntiAffinity 则是保证特定拓扑域内只有一个 Pod,这是打散调度,但是这些调度策略无法应对尽可能均匀分布的场景,尤其是在分布式应用场景下,需要实现高可用分布在多个拓扑域。
当然,如果你使用的 Kubernetes 版本较低,无法体验拓扑分布约束的特性,还有 Nebula-Scheduler 调度器供你选择。它的核心逻辑就是保证每个组件的 Pod 可以均匀分布在指定拓扑域上。
工作负载控制器
Nebula Operator 计划支持多种工作负载控制器,通过使用 reference 配置项,可自主地选择使用哪一种工作负载控制器,当前在原生的 StatefulSet 基础上,Nebula Operator 还额外支持社区版 OpenKruise 的 AdvancedStatefulSet。用户可根据自身业务的需要,在 Nebula Operator 中使用如原地升级、指定节点下线等高级特性,当然这也需要在 Operator 内部实现相应的配置,目前只支持原地升级的参数。
reference:
name: statefulsets.apps
version: v1
其他功能
其他诸如 WebHook 提供高可用模式下的配置校验,自定义参数配置更新等功能就不额外介绍了,这些特性都是为了让你通过 Nebula Operator 管理 Nebula Graph 集群更加的安全方便,具体细节可以阅读 GitHub 上的文档,这里不过多阐述。
FAQ
Nebula Operator 是否可以在 Kubernetes 之外使用?
不可以,Operator 是依托于 Kubernetes 运行的,它是 Kubernetes API 的扩展,这是 K8s 领域内的工具。
如何保障升级、扩缩容的稳定可用,失败后能否回退?
建议提前做好数据备份,以免失败还能回退。Nebula Operator 目前还不支持操作前数据备份,后续会迭代支持上。
能否兼容 NebulaGraph v1.x 集群?
v1.x 不支持内部域名解析,Nebula Operator 需要内部域名解析的这个特性,无法兼容。
使用本地存储是否保证集群稳定?
目前无法保证,使用本地存储就意味着 Pod 与特定的节点有绑定关系,Operator 目前不具备使用本地存储节点宕机后故障转移的能力,使用网络存储没有这个问题。
升级功能何时能支持上?
Nebula Operator 需要跟 NebulaGraph 保持一致,待数据库支持滚动升级后,Operator 会同步支持这个功能。
Nebula Operator 现已开源,欢迎访问 GitHub:https://github.com/vesoft-inc/nebula-operator 来尝鲜~
来参加 Nebula Operator 喊你提需求活动,帮它成长为你想要的样子吧:Nebula Operator 由你话事
一文详解云上自动化部署集群管理工具 Nebula Operator的更多相关文章
- ubuntu 20.04 基于kubeadm部署kubernetes 1.22.4集群及部署集群管理工具
一.环境准备: 集群版本:kubernetes 1.22.4 服务器系统 节点IP 节点类型 服务器-内存/CUP hostname Ubuntu 20.04 192.168.1.101 主节点 2G ...
- HUE配置文件hue.ini 的hdfs_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hive和beeswax模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的yarn_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的mapred_clusters模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的hbase模块详解(图文详解)(分HA集群和非HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的zookeeper模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的Spark模块详解(图文详解)(分HA集群和HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的impala模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- HUE配置文件hue.ini 的liboozie和oozie模块详解(图文详解)(分HA集群)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
随机推荐
- echarts使用transform缩放后导致图标模糊
echarts使用transform缩放后导致图标模糊 --的解决办法 当使用了transform: scale(x,y)缩放后致使echarts图表模糊.怎么解决这个问题呢? 第一种解决办法:将ca ...
- Element-UI中Drawer抽屉去除标题自带黑色边框
当点击事件drawer==true时,抽匣回打开 这时抽匣的标题会出现一个难看的蓝色边框,一会就会消失,但是好丑,所以要去掉它 解决方法 /deep/ :focus { outline: 0; } v ...
- Jmeter报错权限不够
Jmeter报错权限不够 解决办法: chmod +x jmeter
- 14.3 Socket 字符串分块传输
首先为什么要实行分块传输字符串,一般而言Socket套接字最长发送的字节数为8192字节,如果发送的字节超出了此范围则后续部分会被自动截断,此时将字符串进行分块传输将显得格外重要,分块传输的关键在于封 ...
- 从嘉手札<2024-1-2>
最近看了很多这样的文案,某音有,某扑也有很多,出于infp的被动,莫名的觉得悲伤. 悲伤的是一颗真心没有得到珍惜, 而更令我觉得悲伤的是, 人们往往会把自己炽烈如山海一样的情感倾泻给自己心仪的对象, ...
- Intel自曝未来三代酷睿!AI性能涨2倍、再涨2倍
根据最新财报数据,Intel 2023年第四季度154.1亿美元,同比增长10%,全年收入542亿美元,同比下跌14%,预计2024年第一季度收入122-132亿美元. 其中,酷睿处理器业务为主的CC ...
- 一次人脸识别ViewFaceCore使用的经验分享,看我把门店淘汰下来的POS机改成了人脸考勤机
POS软件是什么?你好意思吗,还在用老掉牙的Winform. 门店被淘汰的POS机 销售终端--POS(point of sale)是一种多功能终端,把它安装在信用卡的特约商户和受理网点中与计算机联成 ...
- 单片机 IAP 功能基础开发篇之APP升级(二)
1.前言 上一篇单片机 IAP 功能基础开发篇之APP升级(一)讲到了单片机 IAP 功能给 APP 程序升级的设计思路,这篇介绍的是具体实现方式. 下一篇单片机 IAP 功能基础开发篇之APP升级( ...
- 优化利器In-Memory开启和效果
本文主要介绍Oracle In-Memory 选件,Oracle在12.1.0.2就已经推出了In-Memory这个选件,现在通常会建议所有使用19.8及之后版本的用户,有条件都要留给In-memor ...
- HttpClientTemplate JDK11以上的版本,可以用,我写的。
package com.diandaxia.common.template; import com.fasterxml.jackson.databind.ObjectMapper; import or ...