1.记我的第一次python爬虫爬取网页视频
It is my first time to public some notes on this platform, and I just want to improve myself by recording something that I learned everyday.
Partly , I don't know much about network crawler , and that makes me just understanding something that floats on the surface.
But since I was learning three days when I got a method to craw some videos on the web.
I am very excited, I just know how to craw something from the internet to computer hard disk. It is a start, surely, this is the first step, I just got to keep moving.
Step 1: Find a video on the web page, then plays the video online, press the keyboard shortcuts F12, it occurs element-checked page
as the following pictures:
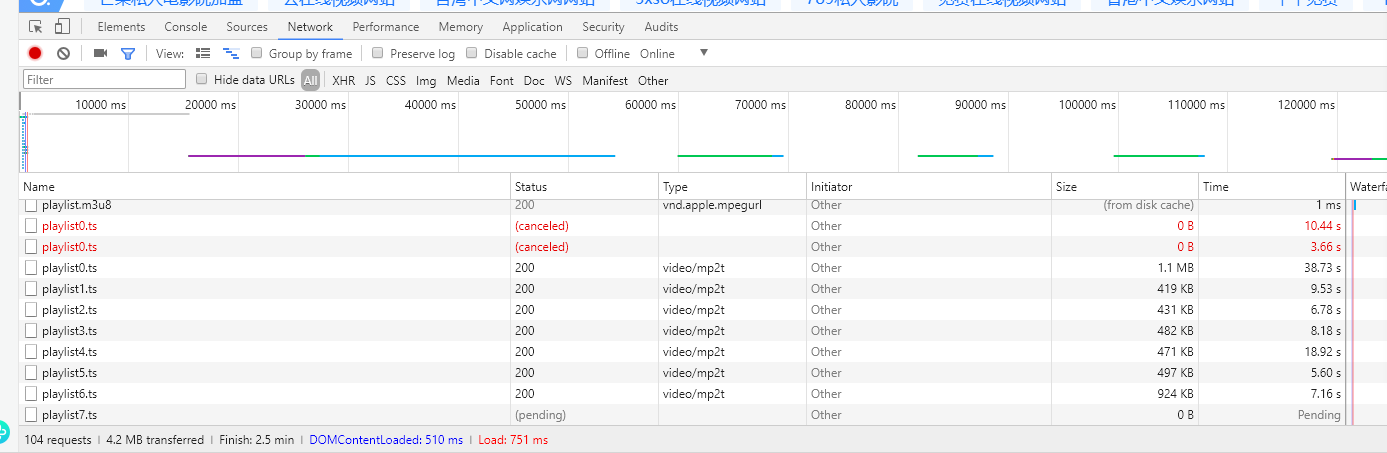
Click .ts file and then you will see the URL, that is the point.

Step 2: Writing python code, as following:
from multiprocessing import Pool
import requests def demo(i):
try:
url = "https://vip.holyshitdo.com/2019/5/8/c2417/playlist%0d.ts"%i
#simulate browser
print(url)
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36Name','Referer':'http://91.com','Content-Type': 'multipart/form-data; session_language=cn_CN'}
r = requests.get(url, headers=headers)
#print(r.content) save the video with binary format
with open('./mp4/{}'.format(url[-10:]),'wb')as f:
f.write(r.content)
except:
return "" if __name__=='__main__': # program entry
pool = Pool(10) # create a process pool
for i in range(193):
pool.apply_async(demo,(i,)) # execute pool.close()
pool.join()
Step 3:Running code
Step 4 : Last but not least, merge .ts fragments into MP4 format.
Get to the terminal interface , under the saved diretory and use command line "copy /b *.ts newfile.mp4"
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
THAT IS ALL FOR NOW, TO BE CONTINUED~( ̄▽ ̄~)~
1.记我的第一次python爬虫爬取网页视频的更多相关文章
- python爬虫——爬取网页数据和解析数据
1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序.只要浏览器能够做的事情,原则上,爬虫都能够做到. 2 ...
- Python爬虫爬取qq视频等动态网页全代码
环境:py3.4.4 32位 需要插件:selenium BeautifulSoup xlwt # coding = utf-8 from selenium import webdriverfrom ...
- Python爬虫爬取网页图片
没想到python是如此强大,令人着迷,以前看见图片总是一张一张复制粘贴,现在好了,学会python就可以用程序将一张张图片,保存下来. 今天逛贴吧看见好多美图,可是图片有点多,不想一张一张地复制粘贴 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
随机推荐
- Vue父子组件传值以及父调子方法、子调父方法
稍微总结了一下Vue中父子间传值以及相互调方法的问题,非常基础.希望可以帮到你!先来个最常用的,直接上代码: 1.父传值给子组件 父组件: <template> <div> & ...
- C# winform 学习(三)
目标 1.windows程序简介 2.窗体的常用属性和事件 3.显示消息框 4.多窗体应用 一.程序简介 1.特点:所见即所得,通过事件实现用户与界面的交互 2.程序结构 1)窗体文件(每个窗体至少有 ...
- webpack从单页面到多页面
前言 从上次更完webpack从什么都不懂到入门之后,好久没有更新过文章了,可能是因为自己懒了吧.今天看了下自己的索引量少了一半o(╥﹏╥)o,发现事态严重,赶紧更新一篇23333 也是因为最近踩了一 ...
- 解决关闭app权限弹框后无法识别页面对象问题
在使用appium进行安卓端app的自动化测试,我碰到这样下面这几个问题: 1.每次启动我的待测app时总会提示app权限 2.关闭完权限后,无法识别页面对象 第一个问题的解决,我更换不同的真机进行测 ...
- tensorflow2.0学习笔记第一章第二节
1.2常用函数 本节目标:掌握在建立和操作神经网络过程中常用的函数 # 常用函数 import tensorflow as tf import numpy as np # 强制Tensor的数据类型转 ...
- Android中Widget开发步骤
一.创建一个类,继承自 AppWidgetProvider 生命周期介绍: onEnabled():创建第一个widget时调用 onDisabled():删除最后一个widget时调用 二.在清单文 ...
- win10 设置开机启动VMware虚拟机并打开指定镜像
1.设置win10开机启动应用 把应用程序的‘快捷方式’放到“系统启动文件夹”里即可. 2.开机启动VMware虚拟机并打开指定镜像 a.右键VMware Workstation快捷方式,看属性 b. ...
- 在kubernetes中搭建harbor,并利用MinIO对象存储保存镜像文件
前言:此文档是用来在线下环境harbor利用MinIO做镜像存储的,至于那些说OSS不香吗?或者单机harbor的,不用看了.此文档对你没啥用,如果是采用单机的harbor连接集群MinIO,请看我的 ...
- 超详细实战教程丨多场景解析如何迁移Rancher Server
本文转自Rancher Labs 作者介绍 王海龙,Rancher中国社区技术经理,负责Rancher中国技术社区的维护和运营.拥有6年的云计算领域经验,经历了OpenStack到Kubernetes ...
- MySQL 性能优化细节
服务器层面优化(了解) 将数据保存在内存中,保证从内存读取数据 设置足够大的innodb_buffer_pool_size,将数据读取到内存中. 建议innodb_buffer_pool_size设置 ...