大数据笔记(三十二)——SparkStreaming集成Kafka与Flume
三、集成:数据源
1、Apache Kafka:一种高吞吐量的分布式发布订阅消息系统
(1)
(*)消息的类型
Topic:主题(相当于:广播)
Queue:队列(相当于:点对点)
(*)常见的消息系统
Kafka、Redis -----> 只支持Topic
JMS(Java Messaging Service标准):Topic、Queue -----> Weblogic
(*)角色:生产者:产生消息
消费者:接收消息(处理消息)
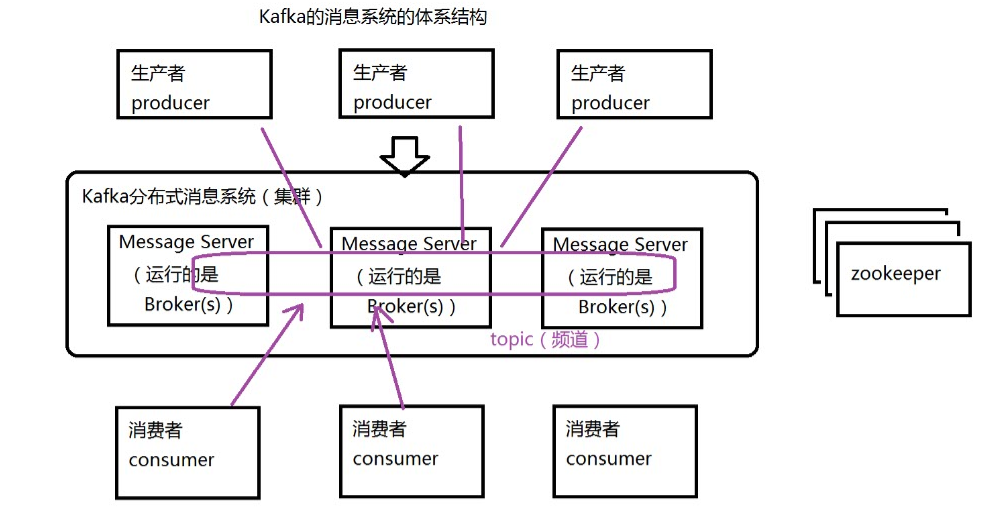
(2)Kafka的消息系统的体系结构
(3)搭建Kafka的环境:单机单Broker的模式
//启动kafka
bin/kafka-server-start.sh config/server.properties &
测试Kafka
创建Topic
bin/kafka-topics.sh --create --zookeeper bigdata11:2181 -replication-factor 1 --partitions 3 --topic mydemo1
发送消息
bin/kafka-console-producer.sh --broker-list bigdata11:9092 --topic mydemo1
接收消息: 从zookeeper中获取topic的信息
bin/kafka-console-consumer.sh --zookeeper bigdata11:2181 --topic mydemo1
(4)集成Spark Streaming:两种方式
注意:依赖的jar包很多(还有冲突),强烈建议使用Maven方式
读到数据:都是key value
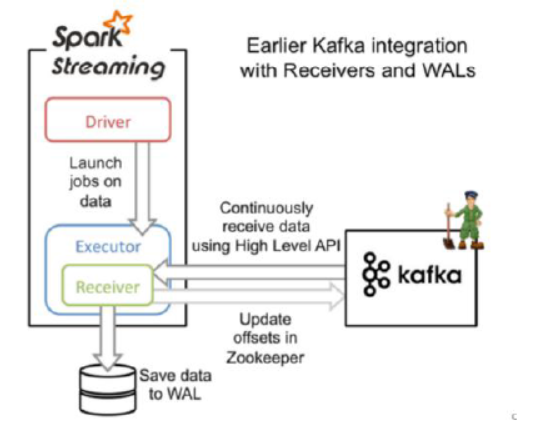
(*)基于接收器方式(receiver)
Receiver的实现使用到Kafka高层次的API.对于所有的Receivers,接收到的数据将会保存在Spark executors中,然后由Spark Streaming 启动Job来处理这些数据
package main.scala.demo import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaReceiverDemo { def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaReceiverDemo").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(10)) //指定Topic信息:从mydemo1的topic中,每次接受一条消息
val topic = Map("mydemo1" -> 1) //创建Kafka输入流(DStream),基于Receiver方式,链接到ZK
//参数:SparkStream,ZK地址,groupId,topic
val kafkaStream = KafkaUtils.createStream(ssc,"192.168.153.11:2181","mygroup",topic) //接受数据,并处理
val lines = kafkaStream.map(e=>{
//e代表是每次接受到的数据
new String(e.toString())
}
) //输出
lines.print() ssc.start()
ssc.awaitTermination()
}
}
启动Kafka,在上面发送一条消息,结果

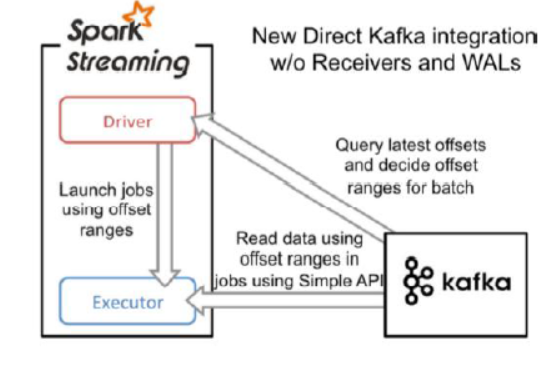
(*)直接读取方式:推荐(效率更高)
这种方式定期的从Kafka的topic+partition中查询最新的偏移量,再根据定义的偏移量在每个batch里面处理数据。当需要处理的数据来临时,spark通过调用kafka简单的消费者API读取一定范围内的数据。
package main.scala.demo import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} object KafkaDirectDemo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("KafkaReceiverDemo").setMaster("local[2]")
val ssc = new StreamingContext(conf,Seconds(10)) //指定Topic信息
val topic = Set("mydemo1") //直接读取Broker,指定就是Broker的地址
val brokerList = Map[String,String]("metadata.broker.list"->"192.168.153.11:9092") //创建一个DStream key value key的解码器 value的解码器
val lines = KafkaUtils.createDirectStream[String,String,StringDecoder,StringDecoder](ssc,brokerList,topic) //读取消息
val message = lines.map(e=>{
new String(e.toString())
}
) message.print() ssc.start()
ssc.awaitTermination() }
}
2、集成Apache Flume:两种方式
注意:依赖jar包Flume lib下面的Jar包,以及
(1)基于Flume Push模式: 推模式。Flume被用于在Flume agents 之间推送数据。在这种方式下,Spark Streaming可以建立一个receiver,起到一个avro receiver的作用。Flume可以直接将数据推送到该receiver。
a4.conf配置。
#bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
#定义agent名, source、channel、sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1 #具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /root/training/logs #具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100 #具体定义sink
a4.sinks = k1
a4.sinks.k1.type = avro
a4.sinks.k1.channel = c1
a4.sinks.k1.hostname = 192.168.153.1
a4.sinks.k1.port = 1234 #组装source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channel = c1
package flume import org.apache.spark.SparkConf
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} object MyFlumeStream {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(5)) //创建FlumeEvent的DStream
val flumeEvent = FlumeUtils.createStream(ssc,"192.168.153.1",1234) //将FlumeEvent中的事件转成字符串
val lineDStream = flumeEvent.map( e => {
new String(e.event.getBody.array)
}) //输出结果
lineDStream.print() ssc.start()
ssc.awaitTermination();
}
}
测试:
1.启动Spark streaming程序MyFlumeStream
2.启动Flume:bin/flume-ng agent -n a4 -f myagent/a4.conf -c conf -Dflume.root.logger=INFO,console
3.拷贝日志文件到/root/training/logs目录
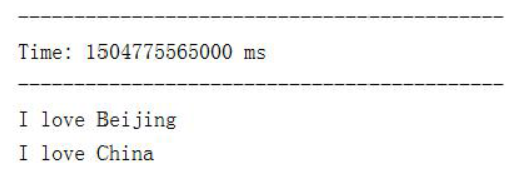
4.观察输出,采集到数据:
(2)自定义sink方式(Pull模式): 拉模式。Flume将数据推送到sink中,并且保持数据buffered状态。Spark Streaming使用一个可靠的Flume接收器从sink拉取数据。这种模式更加健壮和可靠,需要为Flume配置一个正常的sink
(*)将Spark的jar包拷贝到Flume的lib目录下
(*)下面的这个jar包也需要拷贝到Flume的lib目录下
(*)同时加入IDEA工程的classpath
#bin/flume-ng agent -n a1 -f myagent/a1.conf -c conf -Dflume.root.logger=INFO,console
a1.channels = c1
a1.sinks = k1
a1.sources = r1 a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /root/training/logs a1.channels.c1.type = memory
a1.channels.c1.capacity = 100000
a1.channels.c1.transactionCapacity = 100000 a1.sinks.k1.type = org.apache.spark.streaming.flume.sink.SparkSink
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 192.168.153.11
a1.sinks.k1.port = 1234 #组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
package flume import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.flume.FlumeUtils
import org.apache.spark.streaming.{Seconds, StreamingContext} object FlumeLogPull {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("SparkFlumeNGWordCount").setMaster("local[2]")
val ssc = new StreamingContext(conf, Seconds(10)) //创建FlumeEvent的DStream
val flumeEvent = FlumeUtils.createPollingStream(ssc,"192.168.153.11",1234,StorageLevel.MEMORY_ONLY_SER_2) //将FlumeEvent中的事件转成字符串
val lineDStream = flumeEvent.map( e => {
new String(e.event.getBody.array)
}) //输出结果
lineDStream.print() ssc.start()
ssc.awaitTermination();
}
}
开启flume:
bin/flume-ng agent -n a1 -f myagent/a1.conf -c conf -Dflume.root.logger=INFO,console
测试步骤和推模式类似。
大数据笔记(三十二)——SparkStreaming集成Kafka与Flume的更多相关文章
- 大数据笔记(十二)——使用MRUnit进行单元测试
package demo.wc; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntW ...
- 论文阅读笔记三十二:YOLOv3: An Incremental Improvement
论文源址:https://pjreddie.com/media/files/papers/YOLOv3.pdf 代码:https://github.com/qqwweee/keras-yolo3 摘要 ...
- 大数据笔记(十八)——Pig的自定义函数
Pig的自定义函数有三种: 1.自定义过滤函数:相当于where条件 2.自定义运算函数: 3.自定义加载函数:使用load语句加载数据,生成一个bag 默认:一行解析成一个Tuple 需要MR的ja ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- 大数据笔记(十四)——HBase的过滤器与Mapreduce
一. HBase过滤器 1.列值过滤器 2.列名前缀过滤器 3.多个列名前缀过滤器 4.行键过滤器5.组合过滤器 package demo; import javax.swing.RowFilter; ...
- 大数据笔记(十六)——Hive的客户端及自定义函数
一.Hive的Java客户端 JDBC工具类:JDBCUtils.java package demo.jdbc; import java.sql.DriverManager; import java. ...
- PHP学习笔记三十二【Exception】
<?php // $fp=fopen("a.txt","r"); // echo "ok"; if(!file_exists(&quo ...
随机推荐
- 使用iwebshop開發實現QQ第三方登錄
$appid = "101353491"; $appkey = "df4e46ba7da52f787c6e3336d30526e4"; $redirect_ur ...
- linux复习3:linux字符界面的操作
一.前言 1.对linux服务器进行管理的时候,经常要进入字符界面进行操作,使用命令需要记住该命令的相关选项和参数.vi编辑器可以用于编辑任何ASCII文本,功能非常的强大,可以对文本进行创建.查找. ...
- Fliter设置字符编码,解决中文问题
class EncodingFilter implements FileFilter{ private String encoding; @Override public boolean accept ...
- 关于hstack和Svstack
关于hstack和Svstack import numpy as np>>> a = np.array((1,2,3))>>> aarray([1, 2, 3])& ...
- Git命令之:git push
保护版权:转自,http://www.yiibai.com/git/git_push.html
- Python基础——函数进阶
等待更新…………………… 后面再写
- openapi
https://www.breakyizhan.com/swagger/2810.html https://www.cnblogs.com/serious1529/p/9318115.html htt ...
- C++质因数分解
// CPP.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include<iostream> #include<cs ...
- info - 阅读 info 文档
SYNOPSIS 总览 info [OPTION]... [MENU-ITEM...] DESCRIPTION 描述 阅读 info 格式的文档. OPTIONS 选项 --apropos=STRIN ...
- visual studio密钥
企业版:NJVYC-BMHX2-G77MM-4XJMR-6Q8QF 专业版:KBJFW-NXHK6-W4WJM-CRMQB-G3CDH