Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家?
重新理解爬虫中的一些概念
爬虫:自动获取网站数据的程序
反爬虫:使用技术手段防止爬虫程序爬取数据
误伤:反爬虫技术将普通用户识别为爬虫,这种情况多出现在封ip中,例如学校网络、小区网络再或者网络网络都是共享一个公共ip,这个时候如果是封ip就会导致很多正常访问的用户也无法获取到数据。所以相对来说封ip的策略不是特别好,通常都是禁止某ip一段时间访问。
成本:反爬虫也是需要人力和机器成本
拦截:成功拦截爬虫,一般拦截率越高,误伤率也就越高
反爬虫的目的
初学者写的爬虫:简单粗暴,不管对端服务器的压力,甚至会把网站爬挂掉了
数据保护:很多的数据对某些公司网站来说是比较重要的不希望被别人爬取
商业竞争问题:这里举个例子是关于京东和天猫,假如京东内部通过程序爬取天猫所有的商品信息,从而做对应策略这样对天猫来说就造成了非常大的竞争
爬虫与反爬虫大战
上有政策下有对策,下面整理了常见的爬虫大战策略
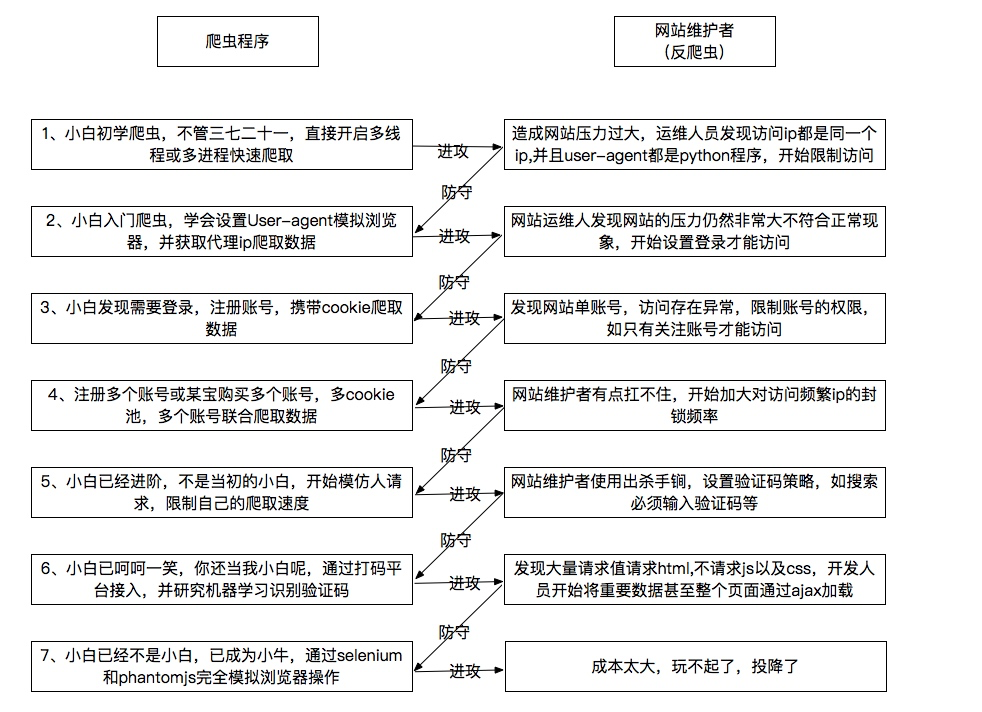
Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战的更多相关文章
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十)之 关于深度优先和广度优先
网站的树结构 深度优先算法和实现 广度优先算法和实现 网站的树结构 通过伯乐在线网站为例子: 并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Bootstrap入门(二十二)组件16:列表组
Bootstrap入门(二十二)组件16:列表组 列表组是灵活又强大的组件,不仅能用于显示一组简单的元素,还能用于复杂的定制的内容. 1.默认样式列表组 2.加入徽章 3.链接 4.禁用的列表组 5. ...
- 一天带你入门到放弃vue.js(二)
接下来我们继续学习一天带你入门到放弃系列vue.js(二),如有问题请留言讨论! v-if index.html <div id="app"> <p v-if=& ...
- 二十二. Python基础(22)--继承
二十二. Python基础(22)--继承 ● 知识框架 ● 继承关系中self的指向 当一个对象调用一个方法时,这个方法的self形参会指向这个对象 class A: def get(s ...
随机推荐
- JAVA优雅停机的实现
最近在项目中需要写一个数据转换引擎服务,每过5分钟同步一次数据.具体实现是启动engine server后会初始化一个ScheduledExecutorService和一个ThreadPoolExec ...
- php提示php_network_getaddresses: getaddrinfo failed: Name or service not known
php_network_getaddresses: getaddrinfo failed: Name or service not known 面对这个错误,已经相对熟悉了.想起来应该是服务器无法访问 ...
- svn怎么切换用户
在使用svn客户端经常会保存用户及密码,方便下次直接登录,有时需要使用别的账号登录,这时该怎么切换呢? 工具/原料 苹果6 小米4 方法/步骤 在使用svn更新或提交数据时需要输入用户名和密码,在 ...
- 用mybatis实现dao的编写或者实现mapper代理
一.mybatis和hibernate的区别和应用场景hibernate:是一个标准的ORM框架(对象关系映射).入门门槛较高的,不需要写sql,sql语句自动生成了.对sql语句进行优化.修改比较困 ...
- kotlin的一些特性介绍和与java C#的简单对比
前言 这是我之前在知乎上的一些回答的汇总,感觉还是博客园写这些东西方便一点,也算是理下我的一些思路,现将文章整理后,发布在园子里. 为何是kotlin: 很多人对kt没有一个正确的定位,可能大家第一反 ...
- Linux 下挂在ntfs 硬盘
CentOS 7 下想要挂载NTFS的文件系统该怎么办呢? 我们需要一个NTFS-3G工具,并编译它之后在mount就可以了,就这么简单. 首先要进入官网下载NTFS-3G工具 http://www. ...
- (转载)提高系统OOP抽象以应对复杂的需求
提高系统OOP抽象以应对复杂的需求, 转自:http://www.nowamagic.net/librarys/veda/detail/1373 有人问我如何构建一个比较好的类阶层次,如何使用面向对象 ...
- SPFA 算法详解
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- JavaScript一个cookie存储的类
所有输出都在浏览器的控制台中 <script type="text/javascript"> /** * cookieStorage.js * 本类实现像localSt ...
- LoadRunner压力测试之Unique Number参数类型、Random Number参数类型浅析
前几天工作需要用LoadRunner进行压力测试,期间对手机号进行参数化设置. 当时选用了<Value>137{Random_quhao}{Unique_weiyi}</Value& ...