Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎
在通过scrapy登录知乎之前,我们先通过requests模块登录知乎,来熟悉这个登录过程
不过在这之前需要了解的知识有:
cookie和session
关于cookie和session我之前整理了一篇博客供参考:
http://www.cnblogs.com/zhaof/p/7211253.html
requests模块的会话维持功能:
这个我在 http://www.cnblogs.com/zhaof/p/6915127.html 关于requests模块中也已经做了整理
主要内容如下,详细内容可参考上面那篇关于requests模块使用的文章
会话维持
cookie的一个作用就是可以用于模拟登陆,做会话维持
import requests
s = requests.Session()
s.get("http://httpbin.org/cookies/set/number/123456")
response = s.get("http://httpbin.org/cookies")
print(response.text)
这是正确的写法,而下面的写法则是错误的
import requests
requests.get("http://httpbin.org/cookies/set/number/123456")
response = requests.get("http://httpbin.org/cookies")
print(response.text)
因为这种方式是两次requests请求之间是独立的,而第一次则是通过创建一个session对象,两次请求都通过这个对象访问
关于爬虫常见登录的方法
这里我之前的文章 http://www.cnblogs.com/zhaof/p/7284312.html 也整理的常用的爬虫登录方法
这点是非常重要的
只有上面这些基础的内容都已经掌握,才能完成下面内容
非框架登录知乎
这里我测试的结果是通过爬虫登录知乎的时候必须携带验证码,否则会提示验证码错误,下面是关于如果没有带验证码时候提示的错误,这个错误可能刚开始写登录知乎的时候都会碰到,所以这里我把这段代码贴出来:
import json
import requests
from bs4 import BeautifulSoup headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
} #这里是非常关键的
session = requests.session() def get_index():
'''
用于获取知乎首页的html内容
:return:
'''
response = session.get("http://www.zhihu.com",headers=headers)
return response.text def get_xsrf():
'''
用于获取xsrf值
:return:
'''
html = get_index()
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"_xsrf"}).get("value")
return res def zhihu_login(account,password):
'''
知乎登录
:param account:
:param password:
:return:
'''
_xsrf = get_xsrf()
post_url = "https://www.zhihu.com/login/phone_num" post_data = {
"_xsrf":_xsrf,
"phone_num":account,
"password":password,
}
response = session.post(post_url,data=post_data,headers=headers)
res = json.loads(response.text)
print(res) zhihu_login('','********')
上述代码当你的用户名和密码都正确的时候最后结果会打印如下内容:

我猜测是可能知乎识别了这是一个爬虫,所以让每次登陆都需要验证码,其实这个时候你正常通过浏览器登陆知乎并不会让你输入验证码,所以这里我们需要获去验证码并将验证码传递到请求参数中,我们分析登录页面就可当登录页需要输入验证码的时候,我们点击验证码会生成新的验证码,抓包分析如下:
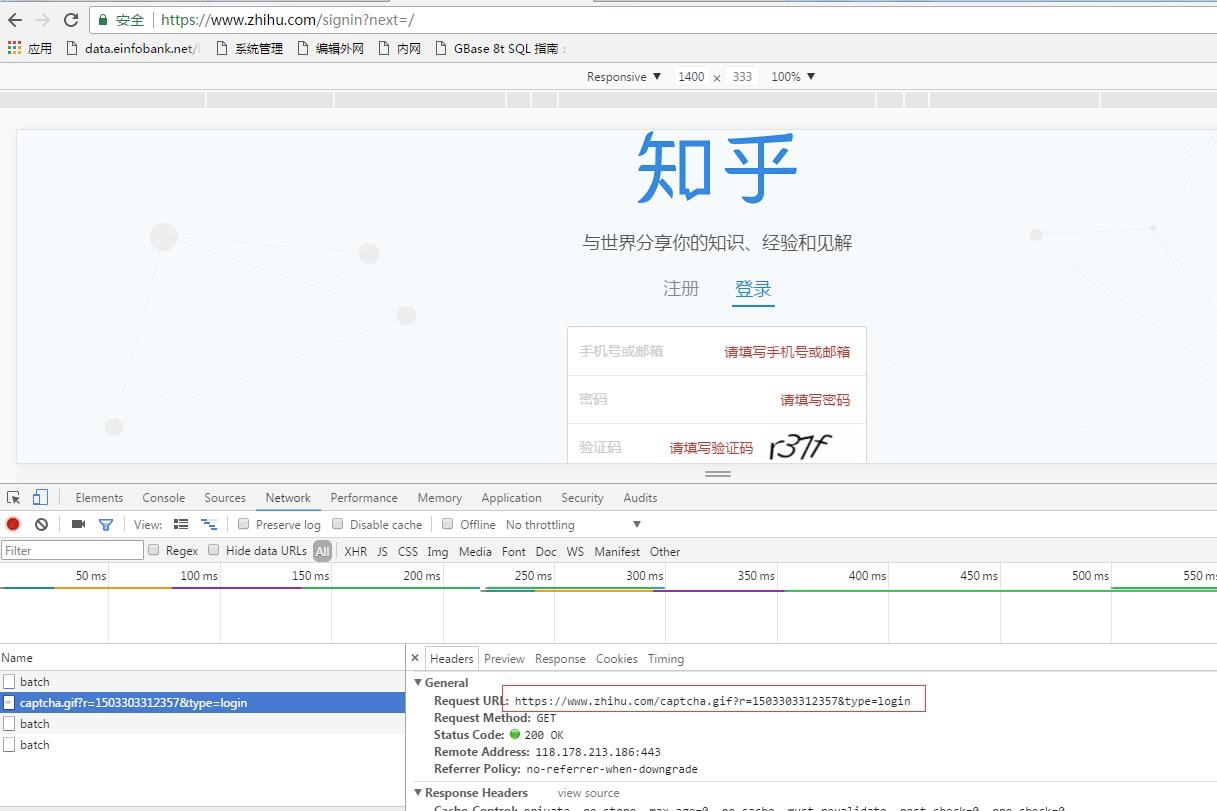
这行我们就获得了生成验证码的地址:
https://www.zhihu.com/captcha.gif?r=1503303312357&type=login
这个时候我们登录的时候传递的参数中就会增加captcha参数
{kind=link}
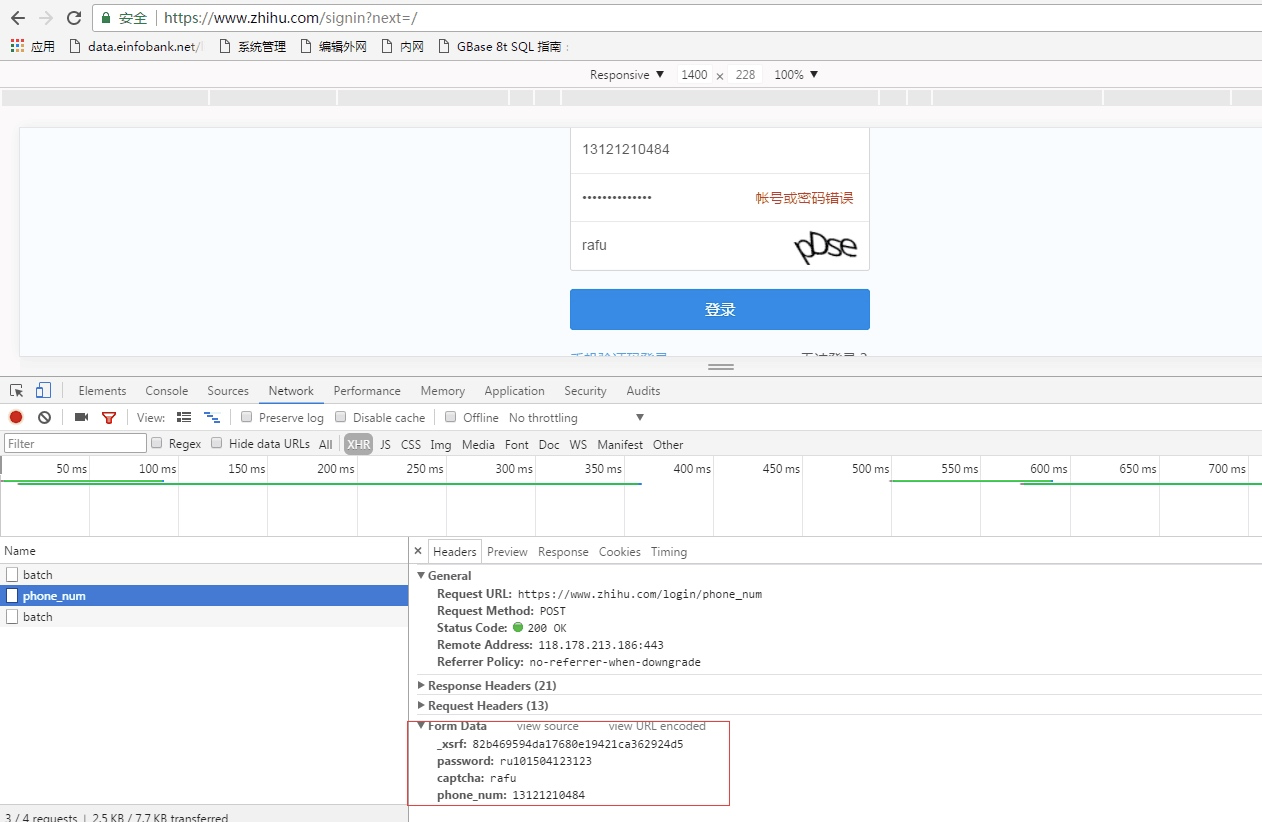
所以我们将上面的代码进行更改,添加验证码参数
import json
import requests
from bs4 import BeautifulSoup headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36",
} #这里是非常关键的
session = requests.session() def get_index():
'''
用于获取知乎首页的html内容
:return:
'''
response = session.get("http://www.zhihu.com",headers=headers)
return response.text def get_xsrf():
'''
用于获取xsrf值
:return:
'''
html = get_index()
soup = BeautifulSoup(html,'lxml')
res = soup.find("input",attrs={"name":"_xsrf"}).get("value")
return res def get_captcha():
'''
获取验证码图片
:return:
'''
import time
t = str(int(time.time()*1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
t = session.get(captcha_url,headers=headers)
with open("captcha.jpg","wb") as f:
f.write(t.content) try:
from PIL import Image
im = Image.open("captcha.jpg")
im.show()
im.close()
except:
pass captcha = input("输入验证码>")
return captcha def zhihu_login(account,password):
'''
知乎登录
:param account:
:param password:
:return:
'''
_xsrf = get_xsrf()
post_url = "https://www.zhihu.com/login/phone_num"
captcha = get_captcha() post_data = {
"_xsrf":_xsrf,
"phone_num":account,
"password":password,
'captcha':captcha,
}
response = session.post(post_url,data=post_data,headers=headers)
res = json.loads(response.text)
print(res) zhihu_login('','******')
这样我们再次登录就会发现结果如下,表示登录成功:

这里要说明的一个问题是这里的验证码并没有接打码平台,所以是手工输入的。
scrapy登录知乎
我们上面已经通过非框架的模式即requests模块的方式成功登录了知乎,现在就是把上面的代码功能在scrapy中实现,这里有一个非常重要的地方,上面的代码中为了会话维持,我们通过:
session = requests.session()
那么我们如何在scrapy中实现呢?
这里就是通过yield,完整代码如下(这里的爬虫是在scrapy项目里直接生成的一个爬虫):
import json
import re import scrapy
from urllib import parse class ZhihuSpider(scrapy.Spider):
name = "zhihu"
allowed_domains = ["www.zhihu.com"]
start_urls = ['https://www.zhihu.com/']
headers = {
'User-Agent':"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36", } def start_requests(self):
'''
重写start_requests,请求登录页面
:return:
'''
return [scrapy.Request('https://www.zhihu.com/#signin',headers=self.headers,callback=self.login)] def login(self,response):
'''
先通过正则获取xsrf值,然后通过scrapy.Request请求验证页面获取验证码
:param response:
:return:
'''
response_text = response.text
match_obj = re.match('.*name="_xsrf" value="(.*?)"',response_text,re.DOTALL)
print(match_obj.group(1))
xsrf=''
if match_obj:
xsrf = match_obj.group(1)
if xsrf:
post_data = {
"_xsrf":xsrf,
"phone_num":"",
"password":"********",
'captcha':'',
}
import time
t = str(int(time.time() * 1000))
captcha_url = "https://www.zhihu.com/captcha.gif?r={0}&type=login".format(t)
#这里利用meta讲post_data传递到后面的response中
yield scrapy.Request(captcha_url,headers=self.headers,meta={"post_data":post_data} ,callback=self.login_after_captcha) def login_after_captcha(self,response):
'''
将验证码写入到文件中,然后登录
:param response:
:return:
'''
with open("captcha.jpg",'wb') as f:
f.write(response.body)
try:
from PIL import Image
im = Image.open("captcha.jpg")
im.show() except:
pass
#提示用户输入验证码
captcha = input("请输入验证码>:").strip()
#从response中的meta中获取post_data并赋值验证码信息
post_data = response.meta.get("post_data")
post_data["captcha"] = captcha
post_url = "https://www.zhihu.com/login/phone_num"
# 这里是通过scrapy.FormRequest提交form表单
return [scrapy.FormRequest(
url=post_url,
formdata=post_data,
headers=self.headers,
callback=self.check_login,
)] def check_login(self,response):
'''
验证服务器的返回数据判断是否成功,我们使用scrapy会自动携带我们登录后的cookie
:param response:
:return:
'''
text_json = json.loads(response.text)
print(text_json)
for url in self.start_urls:
yield self.make_requests_from_url(url,dont_filter=True,header=self.headers)
上述代码中:
yield scrapy.Request(captcha_url,headers=self.headers,meta={"post_data":post_data} ,callback=self.login_after_captcha)
原本scrapy中的scrapy.Request会保存访问过程中的cookie信息其实这里面也是用也是cookiejar,这里通过yield 的方式实现了与会话的维持
我们通过调试登录,如下,同样也登录成功:

Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎的更多相关文章
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- Python之爬虫(二十六) Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十)之 关于深度优先和广度优先
网站的树结构 深度优先算法和实现 广度优先算法和实现 网站的树结构 通过伯乐在线网站为例子: 并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十三)之 Scrapy框架的命令行详解
这篇文章主要是对的scrapy命令行使用的一个介绍 创建爬虫项目 scrapy startproject 项目名例子如下: localhost:spider zhaofan$ scrapy start ...
随机推荐
- readSerializableObj
package JBJADV003;import java.io.*;public class readSerializableObj { public static void main(String ...
- Machine Learning and Data Mining Lecture 1
Machine Learning and Data Mining Lecture 1 1. The learning problem - Outline 1.1 Example of mach ...
- java 线程 理解 解析
1 线程的概述 进程:正在运行的程序,负责了这个程序的内存分配,代表了内存中的执行区域. 线程:就是在一个进程中负者一个执行路径. 多线程:就是在一个进程中多个执行路径同时执行. 假象: 电脑上的程序 ...
- IIS 反向代理 golang web开发
一. beego 开发编译 bee run 后会编译成 exe文件 编译生成后发布文件结构为 cmd 运行 cd D:/run beegoDemo.exe run 默认配置端口 不能为 80 跟iis ...
- RabbitMQ系列教程之七:RabbitMQ的 C# 客户端 API 的简介
今天这篇博文是我翻译的RabbitMQ的最后一篇文章了,介绍一下RabbitMQ的C#开发的接口.好了,言归正传吧. Net/C# 客户端 API简介1.主要的命名空间,接口和类 定义核心的API的 ...
- 3,Spring Boot热部署
问题的提出: 在编写代码的时候,你会发现我们只是简单把打印信息改变了,就需要重新部署,如果是这样的编码方式,那么我们估计一天下来就真的是打几个Hello World就下班了.那么如何解决热部署的问题呢 ...
- linux下查看jdk路径
jdk安装后 centos中: 执行 rpm -ql java-1.7.0-openjdk-devel | grep '/bin/javac' 命令确定, 执行后会输出一个路径,除去路径末尾的 &qu ...
- 【科普】什么是TLS1.3
TLS1.3是一种新的加密协议,它既能提高各地互联网用户的访问速度,又能增强安全性. 我们在访问许多网页的时候,常常会在浏览器的地址栏上看到一个锁的图标,并使用"https"代替传 ...
- 浅谈lvs和nginx的一些优点和缺点
借鉴一些网上资料整理了简单的比较: LVS的负载能力强,因为其工作方式逻辑非常简单,仅进行请求分发,而且工作在网络的第4层,没有流量,所以其效率不需要有过多的忧虑. LVS基本能支持所有应用,因为工作 ...
- Spring源码情操陶冶-AbstractApplicationContext#initApplicationEventMulticaster
承接前文Spring源码情操陶冶-AbstractApplicationContext#initMessageSource 约定web.xml配置的contextClass为默认值XmlWebAppl ...