Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler
5. 创建任务调度器TaskScheduler
TaskScheduler也是SparkContext的重要组成部分,负责任务的提交,并且请求集群管理器对任务调度。TaskScheduler也可以看作任务调度的客户端。创建TaskScheduler的代码如下:

createTaskScheduler方法会根据master的配置匹配部署模式,创建TaskSchedulerImpl,并生成不同的SchedulerBackend。为了使读者更容易理解Spark的初始化流程,故以local模式为例,master匹配local模式的代码如下:
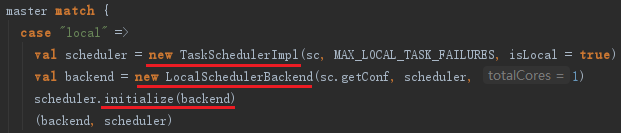
5.1 创建TaskSchedulerImpl
TaskSchedulerImpl的构造过程如下:
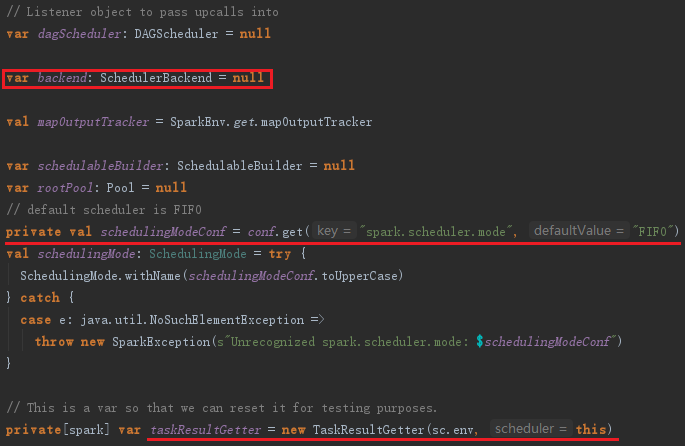
1) 从SparkConf中读取配置信息,包括每个任务分配的CPU数、调度模式(调度模式由FAIR和FIFO两种,默认为FIFO,可以修改属性spark.scheduler.mode来改变)等。
2) 创建TaskResultGetter,它的作用是通过线程池(Executors.newFixedThreadPool创建的,默认为4个线程,线程名字以task-result-getter开头,线程工厂默认是Executors.defaultThreadFactory)对Worker上的Executor发送的Task的执行结果进行处理。
TaskSchedulerImpl的实现见代码:
TaskSchedulerImpl的调度模式有FAIR和FIFO两种。任务的最终调度实际都是落实到接口SchedulerBackend的具体实现上的。为方便分析,我们先来看看local模式中SchedulerBackend的实现LocalSchedulerBackend。LocalSchedulerBackend依赖于localEndpoint与RpcEnv进行消息通信。
5.2 TaskSchedulerImpl的初始化
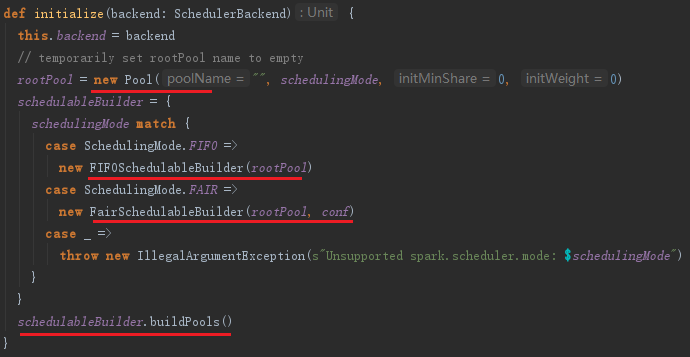
创建完TaskSchedulerImpl和LocalSchedulerBackend后,对TaskSchedulerImpl调用方法initialize进行初始化。以默认的FIFO调度为例,TaskScheduler的初始化过程如下:
1) 使TaskSchedulerImpl持有LocalSchedulerBaskend的引用。
2) 在TaskSchedulerImpl的initialize方法里创建Pool,Pool中缓存了调度队列、调度算法及TaskSetManager集合等信息。
3) 创建FIFOSchedulableBuilder或FairSchedulableBuilder,用来操作Pool中的调度队列。
initialize方法的实现如下:
Spark源码剖析 - SparkContext的初始化(五)_创建任务调度器TaskScheduler的更多相关文章
- Spark源码剖析 - SparkContext的初始化(二)_创建执行环境SparkEnv
2. 创建执行环境SparkEnv SparkEnv是Spark的执行环境对象,其中包括众多与Executor执行相关的对象.由于在local模式下Driver会创建Executor,local-cl ...
- Spark源码剖析 - SparkContext的初始化(三)_创建并初始化Spark UI
3. 创建并初始化Spark UI 任何系统都需要提供监控功能,用浏览器能访问具有样式及布局并提供丰富监控数据的页面无疑是一种简单.高效的方式.SparkUI就是这样的服务. 在大型分布式系统中,采用 ...
- Spark源码剖析 - SparkContext的初始化(六)_创建和启动DAGScheduler
6.创建和启动DAGScheduler DAGScheduler主要用于在任务正式交给TaskSchedulerImpl提交之前做一些准备工作,包括:创建Job,将DAG中的RDD划分到不同的Stag ...
- Spark源码剖析 - SparkContext的初始化(八)_初始化管理器BlockManager
8.初始化管理器BlockManager 无论是Spark的初始化阶段还是任务提交.执行阶段,始终离不开存储体系.Spark为了避免Hadoop读写磁盘的I/O操作成为性能瓶颈,优先将配置信息.计算结 ...
- Spark源码剖析 - SparkContext的初始化(九)_启动测量系统MetricsSystem
9. 启动测量系统MetricsSystem MetricsSystem使用codahale提供的第三方测量仓库Metrics.MetricsSystem中有三个概念: Instance:指定了谁在使 ...
- Spark源码剖析 - SparkContext的初始化(一)
1. SparkContext概述 注意:SparkContext的初始化剖析是基于Spark2.1.0版本的 Spark Driver用于提交用户应用程序,实际可以看作Spark的客户端.了解Spa ...
- Spark源码剖析 - SparkContext的初始化(十)_Spark环境更新
12. Spark环境更新 在SparkContext的初始化过程中,可能对其环境造成影响,所以需要更新环境,代码如下: SparkContext初始化过程中,如果设置了spark.jars属性,sp ...
- Spark源码剖析 - SparkContext的初始化(七)_TaskScheduler的启动
7. TaskScheduler的启动 第五节介绍了TaskScheduler的创建,要想TaskScheduler发挥作用,必须要启动它,代码: TaskScheduler在启动的时候,实际调用了b ...
- Spark源码剖析 - SparkContext的初始化(四)_Hadoop相关配置及Executor环境变量
4. Hadoop相关配置及Executor环境变量的设置 4.1 Hadoop相关配置信息 默认情况下,Spark使用HDFS作为分布式文件系统,所以需要获取Hadoop相关配置信息的代码如下: 获 ...
随机推荐
- luogu3621 城池攻占 (倍增)
好像所有人都写的左偏树 但我不会啊233 首先发现乘的时候 系数不会为负,所以能得到一个关键条件:变化后的战斗力随变化前的战斗力大小单调 所以我们考虑倍增 设hp[x][i]是从x开始一路攻克$2^i ...
- DNA Evolution CodeForces - 828E(树状数组)
题中有两种操作,第一种把某个位置的字母修改,第二种操作查询与[L, R]内与给出字符串循环起来以后对应位置的字母相同的个数.给出的字符串最大长度是10. 用一个四维树状数组表示 cnt[ATCG的编号 ...
- 单片机的外围功能电路 LET′S TRY“嵌入式编程”: 2 of 6
单片机的外围功能电路 LET′S TRY“嵌入式编程”: 2 of 6 本连载讲解作为嵌入式系统开发技术人员所必需具备的基础知识.这些基础知识是硬件和软件技术人员都应该掌握的共通技术知识. 上期在&l ...
- Ocean的游戏(前缀和)
题目链接:http://oj.ismdeep.com/contest/Problem?id=1284&pid=1 B: Ocean的游戏 Time Limit: 1 s Memory ...
- Java线程池中submit()和execute之间的区别?
一: submit()方法,可以提供Future < T > 类型的返回值. executor()方法,无返回值. execute无返回值 public void execute(Runn ...
- 【模板】多项式乘法(FFT)
题目描述 给定一个n次多项式F(x),和一个m次多项式G(x). 请求出F(x)和G(x)的卷积. 输入输出格式 输入格式: 第一行2个正整数n,m. 接下来一行n+1个数字,从低到高表示F(x)的系 ...
- JAVA版本8u171与8u172的区别
用了java 7好几年了,今天闲来无事,想升级到 java 8,到官网下载的时候发现JAVA放出了8u171与8u172两个版本. 什么情况? 百度一下找到答案:https://blog.csdn.n ...
- react-native中的setNativeProps
如果你通过React.createClass方法自定义了一个组件,直接给它设置样式 prop 是不会生效的,你得把样式 props 层层向下传递给子组件 ,直到子组件是一个能够直接定义样式的原生组件. ...
- JMeter关联(正则表达式提取器)
正则表达式总结 关联:与系统交互过程中,系统返回的内容,需要在接下来的交互中用到,如防止csrf攻击而生成的token. 从前一个请求中取,用Regular Expression Extractor ...
- snpeff注释变异(variants)
1.进入网站http://snpeff.sourceforge.net/,下载snpeff: wget http://sourceforge.net/projects/snpeff/files/snp ...