scrapy爬虫爬取小姐姐图片(不羞涩)
这个爬虫主要学习scrapy的item Pipeline
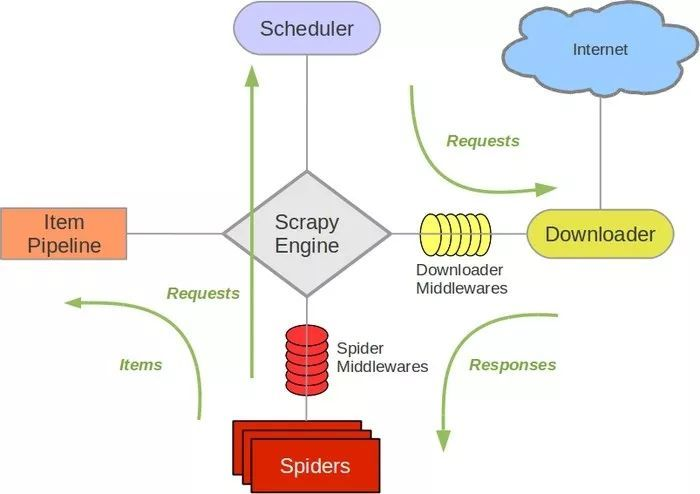
是时候搬出这张图了:
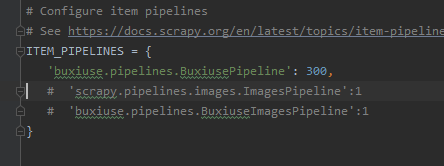
当我们要使用item Pipeline的时候,要现在settings里面取消这几行的注释
我们可以自定义Item Pipeline,只需要实现指定的方法,其中必须要实现的一个方法是: p
process_item(item,spider)
另外还有几个方法我们有时候会用到
open_spider(spider)
close_spider(spider)
from_crawler(cls,crawler)
在不羞涩的主页(https://www.buxiuse.com/)我们使用xpath进行分析可以得到每一张小姐姐图片的url,我们将每一页urls作为一个item对象返回,并且找到下一页的链接,持续爬取
class IndexSpider(scrapy.Spider):
name = 'index'
allowed_domains = ['buxiuse.com']
start_urls = ['https://www.buxiuse.com/?page=1']
base_domain="https://www.buxiuse.com" def parse(self, response):
image_urls=response.xpath('//ul[@class="thumbnails"]/li//img/@src').getall()
next_url=response.xpath('//li[@class="next next_page"]/a/@href').get()
item=BuxiuseItem(image_urls=image_urls)
yield item
if not next_url:
return
else:
yield scrapy.Request(self.base_domain+next_url)
对于yield的item对象,因为只返回了一个urls,所以我们在items进行设置
class BuxiuseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
image_urls=scrapy.Field()
这样在刚才的index文件里面,才可以新建BuxiuseItem对象,
item=BuxiuseItem(image_urls=image_urls)
当然要先在index导入BuxiuseItem这个类
接着在pipeline里面我们处理接收到的Item和下载图片
我们先创建一个image的文件夹储存爬取到的图片,使用os.mkdir(self.path)
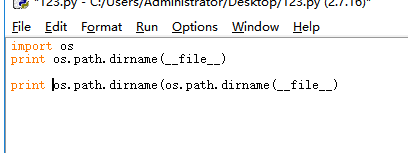
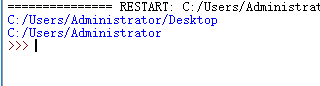
这个self.path由我们自己设定,这里学到了一个知识点:os.path.dirname(__file__)可以显示当前文件所在的位置
我们先输出一下
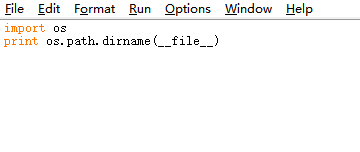
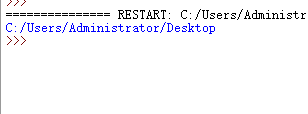
使用os.path.dirname(os.path.dirname(__file__))可以返回到上一级目录位置
我们使用这个方法控制储存的目录,如果是其他比较远的位置就使用绝对路径吧。
因为我是python2的环境,使用
urllib.urlretrieve(link,os.path.join(self.path,image_name))
将链接上的图片以指定的文件名保存在指定位置上
所以pipeline里面的代码就是
import os
import urllib
from scrapy.pipelines.images import ImagesPipeline
import settings
i=1
class BuxiusePipeline(object):
def __init__(self):
self.path=os.path.join(os.path.dirname(os.path.dirname(__file__)),'images')
if not os.path.exists(self.path):
os.mkdir(self.path) def process_item(self, item, spider):
global i
link_list=item['image_urls']
for link in link_list:
print i
image_name=str(i)+".jpg"
urllib.urlretrieve(link,os.path.join(self.path,image_name))
i=i+1
return item
输出i是为了让我能看到脚本还在正常下载,免得被网站ban掉了还不知道。
运行一下看看效果:
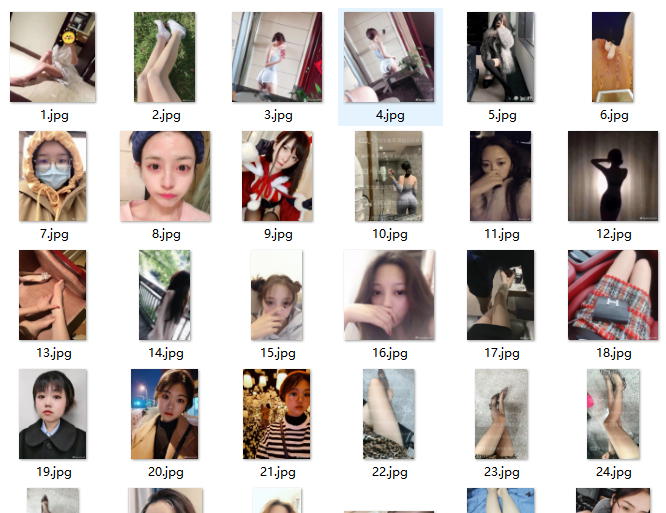
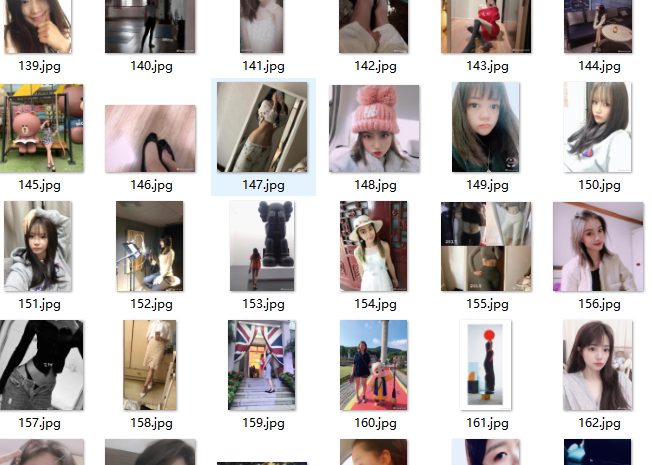
可以看到小姐姐的图片已经被下载下来了,并且按照i的编号整齐排列,完事。
github代码:
https://github.com/Cl0udG0d/scrapy_demo/tree/master/buxiuse
scrapy爬虫爬取小姐姐图片(不羞涩)的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- 使用scrapy爬虫,爬取17k小说网的案例-方法一
无意间看到17小说网里面有一些小说小故事,于是决定用爬虫爬取下来自己看着玩,下图这个页面就是要爬取的来源. a 这个页面一共有125个标题,每个标题里面对应一个内容,如下图所示 下面直接看最核心spi ...
- <scrapy爬虫>爬取校花信息及图片
1.创建scrapy项目 dos窗口输入: scrapy startproject xiaohuar cd xiaohuar 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- <scrapy爬虫>爬取360妹子图存入mysql(mongoDB还没学会,学会后加上去)
1.创建scrapy项目 dos窗口输入: scrapy startproject images360 cd images360 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) ...
- <scrapy爬虫>爬取猫眼电影top100详细信息
1.创建scrapy项目 dos窗口输入: scrapy startproject maoyan cd maoyan 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # -*- ...
- 使用scrapy爬虫,爬取今日头条搜索吉林疫苗新闻(scrapy+selenium+PhantomJS)
这一阵子吉林疫苗案,备受大家关注,索性使用爬虫来爬取今日头条搜索吉林疫苗的新闻 依然使用三件套(scrapy+selenium+PhantomJS)来爬取新闻 以下是搜索页面,得到吉林疫苗的搜索信息, ...
- <scrapy爬虫>爬取quotes.toscrape.com
1.创建scrapy项目 dos窗口输入: scrapy startproject quote cd quote 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) import ...
- <scrapy爬虫>爬取腾讯社招信息
1.创建scrapy项目 dos窗口输入: scrapy startproject tencent cd tencent 2.编写item.py文件(相当于编写模板,需要爬取的数据在这里定义) # - ...
随机推荐
- TP3 根据时间区间搜索的方法
/** * 时间段查询条件获取 * @param string $star 获取开始时间的字段名 * @param string $end 获取结束时间的字段名 * @param string $zd ...
- 一键SSH连接 = SSH密钥登陆 + WindowsTerminal
本文记录如何利用SSH密钥登录和WindowsTerminal/FluentTerminal实现一键SSH连接 目录 一.在本地生成SSH密钥对 二.在远程主机安装公钥 三.在远程主机打开密钥登陆功能 ...
- Python_异常处理、调试
1.try except 机制 # 错误处理 # 一般程序都要用到错误捕获,当没有加且有错误的时候Python解释器会执行错误捕获,且是一层层向上捕获[所以问题点会在最下面] try: print(' ...
- Python_爬虫_BeautifulSoup网页解析库
BeautifulSoup网页解析库 from bs4 import BeautifulSoup 0.BeautifulSoup网页解析库包含 的 几个解析器 Python标准库[主要,系统自带;] ...
- vue实现增删改查(内附源代码)
VUE+Element实现增删改查 @ 目录 VUE+Element实现增删改查 前言 实验步骤 总结: 源代码 前言 &最近因为一些原因,没有更博客,昨天老师布置了一个作业,用vue实现增删 ...
- python笔记(1)---数据类型
数据类型 基本的五大数据类型 对python中的变量有如下的五种基本的数据类型: Number数字 list列表 Tuple元组 string字符串 Dictionary字典 1.Number [注意 ...
- 维吉尼亚密码-攻防世界(shanghai)
维吉尼亚密码 维吉尼亚密码是使用一系列 凯撒密码 组成密码字母表的加密算法,属于多表密码的一种简单形式. 加密原理 维吉尼亚密码的前身,是我们熟悉的凯撒密码. 凯撒密码的加密方式是依靠一张字母表中的每 ...
- FL Studio录制面板知识讲解
FL Studio录制面板可以设置与录制有关的选项,它还有一个用来设置音符对齐的全局吸附选择器.刚接触水果这款音乐制作软件的同学通常不是很清楚这里的知识的,下面小编就给大家讲解一下. 1.首先,我们来 ...
- guitar pro系列教程(二十四):Guitar Pro 7 中文界面的介绍
用过Guitar Pro这款软件的小伙伴们都知道,Guitar Pro这款吉他软件因为是国外开发商研发的,所以软件最初都是英文版本,对于国内的的吉他爱好者来说,在软件使用上还是很不方便的.随着Guit ...
- 工作中用到的redis操作
del exists 1.字符串 set,get 2.列表 lRange lRem lPush rPush 3.有序列表 zadd zrem zscore 4.hash hset hget hdel