吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import cluster
from sklearn.datasets.samples_generator import make_blobs
# 模拟数据集
X,y = make_blobs(n_samples = 2000, centers = [[-1,-2],[1,3]], cluster_std = [0.5,0.5], random_state = 1234)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.column_stack((X,y)), columns = ['x1','x2','y'])
# 设置绘图风格
plt.style.use('ggplot')
# 绘制散点图(用不同的形状代表不同的簇)
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o'],
fit_reg = False, legend = False)
# 显示图形
plt.show()

# 导入第三方模块
from sklearn import cluster
# 构建Kmeans聚类和密度聚类
kmeans = cluster.KMeans(n_clusters=2, random_state=1234)
kmeans.fit(X)
dbscan = cluster.DBSCAN(eps = 0.5, min_samples = 10)
dbscan.fit(X)
# 将Kmeans聚类和密度聚类的簇标签添加到数据框中
plot_data['kmeans_label'] = kmeans.labels_
plot_data['dbscan_label'] = dbscan.labels_
# 绘制聚类效果图
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0))
# 绘制散点图
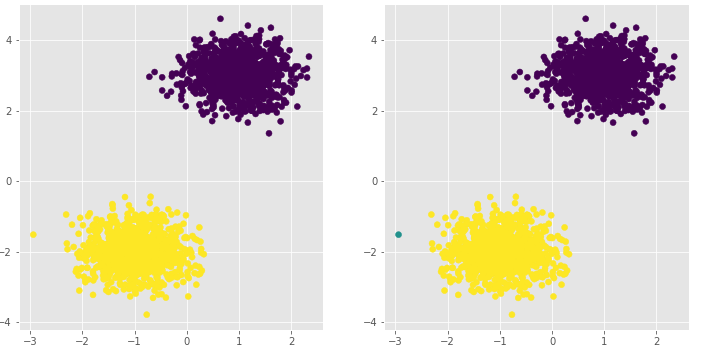
ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1))
# 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射)
ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:2,1:0}))
# 显示图形
plt.show()
# 导入第三方模块
from sklearn.datasets.samples_generator import make_moons
# 构造非球形样本点
X1,y1 = make_moons(n_samples=2000, noise = 0.05, random_state = 1234)
# 构造球形样本点
X2,y2 = make_blobs(n_samples=1000, centers = [[3,3]], cluster_std = 0.5, random_state = 1234)
# 将y2的值替换为2(为了避免与y1的值冲突,因为原始y1和y2中都有0这个值)
y2 = np.where(y2 == 0,2,0)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.row_stack([np.column_stack((X1,y1)),np.column_stack((X2,y2))]), columns = ['x1','x2','y'])
# 绘制散点图(用不同的形状代表不同的簇)
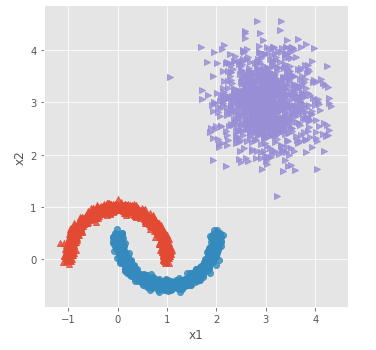
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o','>'],
fit_reg = False, legend = False)
# 显示图形
plt.show()
# 构建Kmeans聚类和密度聚类
kmeans = cluster.KMeans(n_clusters=3, random_state=1234)
kmeans.fit(plot_data[['x1','x2']])
dbscan = cluster.DBSCAN(eps = 0.3, min_samples = 5)
dbscan.fit(plot_data[['x1','x2']])
# 将Kmeans聚类和密度聚类的簇标签添加到数据框中
plot_data['kmeans_label'] = kmeans.labels_
plot_data['dbscan_label'] = dbscan.labels_
# 绘制聚类效果图
# 设置大图框的长和高
plt.figure(figsize = (12,6))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,2), loc = (0,0))
# 绘制散点图
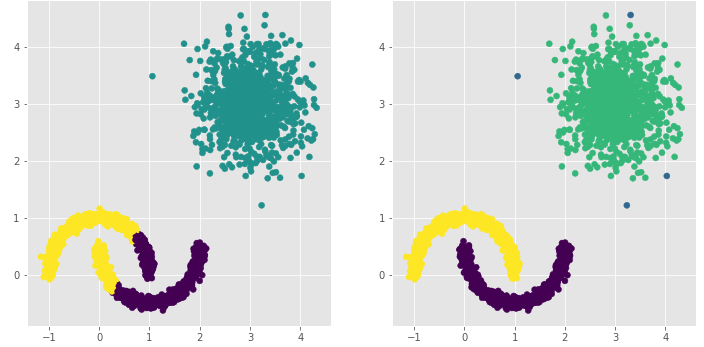
ax1.scatter(plot_data.x1, plot_data.x2, c = plot_data.kmeans_label)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,2), loc = (0,1))
# 绘制散点图(为了使Kmeans聚类和密度聚类的效果图颜色一致,通过序列的map“方法”对颜色作重映射)
ax2.scatter(plot_data.x1, plot_data.x2, c=plot_data.dbscan_label.map({-1:1,0:0,1:3,2:2}))
# 显示图形
plt.show()
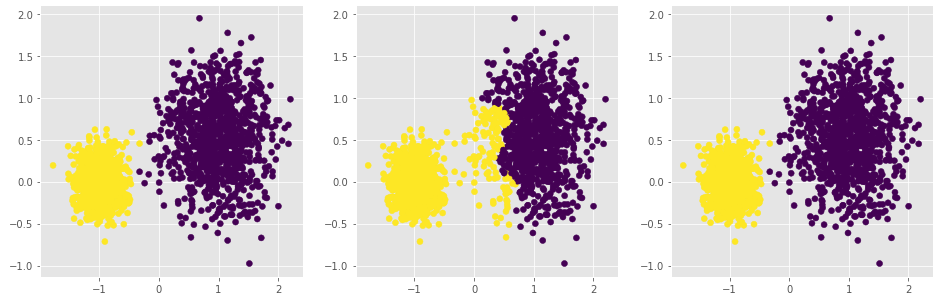
# 构造两个球形簇的数据样本点
X,y = make_blobs(n_samples = 2000, centers = [[-1,0],[1,0.5]], cluster_std = [0.2,0.45], random_state = 1234)
# 将模拟得到的数组转换为数据框,用于绘图
plot_data = pd.DataFrame(np.column_stack((X,y)), columns = ['x1','x2','y'])
# 绘制散点图(用不同的形状代表不同的簇)
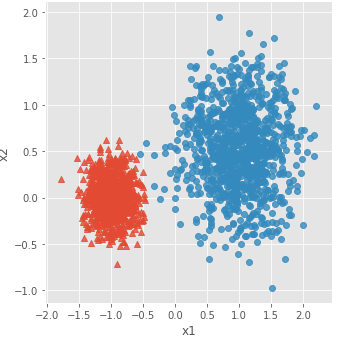
sns.lmplot('x1', 'x2', data = plot_data, hue = 'y',markers = ['^','o'],
fit_reg = False, legend = False)
# 显示图形
plt.show()
# 设置大图框的长和高
plt.figure(figsize = (16,5))
# 设置第一个子图的布局
ax1 = plt.subplot2grid(shape = (1,3), loc = (0,0))
# 层次聚类--最小距离法
agnes_min = cluster.AgglomerativeClustering(n_clusters = 2, linkage='ward')
agnes_min.fit(X)
# 绘制聚类效果图
ax1.scatter(X[:,0], X[:,1], c=agnes_min.labels_)
# 设置第二个子图的布局
ax2 = plt.subplot2grid(shape = (1,3), loc = (0,1))
# 层次聚类--最大距离法
agnes_max = cluster.AgglomerativeClustering(n_clusters = 2, linkage='complete')
agnes_max.fit(X)
ax2.scatter(X[:,0], X[:,1], c=agnes_max.labels_)
# 设置第三个子图的布局
ax2 = plt.subplot2grid(shape = (1,3), loc = (0,2))
# 层次聚类--平均距离法
agnes_avg = cluster.AgglomerativeClustering(n_clusters = 2, linkage='average')
agnes_avg.fit(X)
plt.scatter(X[:,0], X[:,1], c=agnes_avg.labels_)
plt.show()
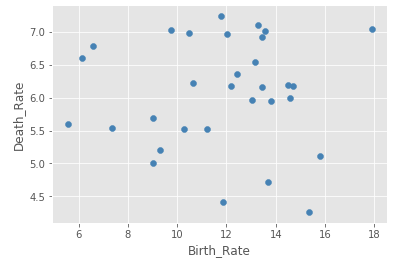
# 读取外部数据
Province = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\16\\Province.xlsx')
Province.head()
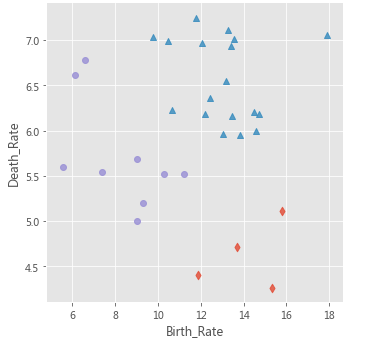
# 绘制出生率与死亡率散点图
plt.scatter(Province.Birth_Rate, Province.Death_Rate, c = 'steelblue')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
# 读入第三方包
from sklearn import preprocessing
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 选取建模的变量
predictors = ['Birth_Rate','Death_Rate']
# 变量的标准化处理
X = preprocessing.scale(Province[predictors])
X = pd.DataFrame(X)
# 构建空列表,用于保存不同参数组合下的结果
res = []
# 迭代不同的eps值
for eps in np.arange(0.001,1,0.05):
# 迭代不同的min_samples值
for min_samples in range(2,10):
dbscan = cluster.DBSCAN(eps = eps, min_samples = min_samples)
# 模型拟合
dbscan.fit(X)
# 统计各参数组合下的聚类个数(-1表示异常点)
n_clusters = len([i for i in set(dbscan.labels_) if i != -1])
# 异常点的个数
outliners = np.sum(np.where(dbscan.labels_ == -1, 1,0))
# 统计每个簇的样本个数
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)
res.append({'eps':eps,'min_samples':min_samples,'n_clusters':n_clusters,'outliners':outliners,'stats':stats})
# 将迭代后的结果存储到数据框中
df = pd.DataFrame(res)
# 根据条件筛选合理的参数组合
df.loc[df.n_clusters == 3, :]
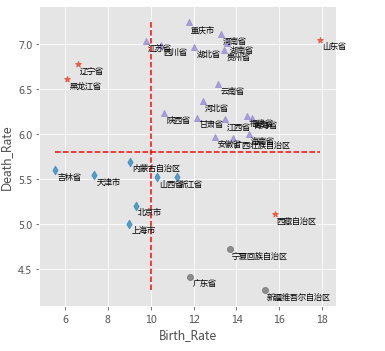
# 利用上述的参数组合值,重建密度聚类算法
dbscan = cluster.DBSCAN(eps = 0.801, min_samples = 3)
# 模型拟合
dbscan.fit(X)
Province['dbscan_label'] = dbscan.labels_
# 绘制聚类聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'dbscan_label', data = Province,
markers = ['*','d','^','o'], fit_reg = False, legend = False)
# 添加省份标签
for x,y,text in zip(Province.Birth_Rate,Province.Death_Rate, Province.Province):
plt.text(x+0.1,y-0.1,text, size = 8)
# 添加参考线
plt.hlines(y = 5.8, xmin = Province.Birth_Rate.min(), xmax = Province.Birth_Rate.max(),
linestyles = '--', colors = 'red')
plt.vlines(x = 10, ymin = Province.Death_Rate.min(), ymax = Province.Death_Rate.max(),
linestyles = '--', colors = 'red')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
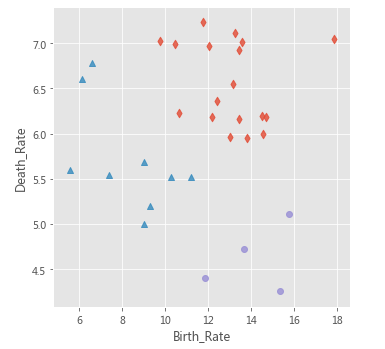
# 利用最小距离法构建层次聚类
agnes_min = cluster.AgglomerativeClustering(n_clusters = 3, linkage='ward')
# 模型拟合
agnes_min.fit(X)
Province['agnes_label'] = agnes_min.labels_
# 绘制层次聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'agnes_label', data = Province,
markers = ['d','^','o'], fit_reg = False, legend = False)
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()
# 导入第三方模块
from sklearn import metrics
# 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储个中簇数下的轮廓系数
S = []
for k in K:
kmeans = cluster.KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用字模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与轮廓系数的关系
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
# 显示图形
plt.show()
# 聚类个数的探索
k_silhouette(X, clusters = 10)
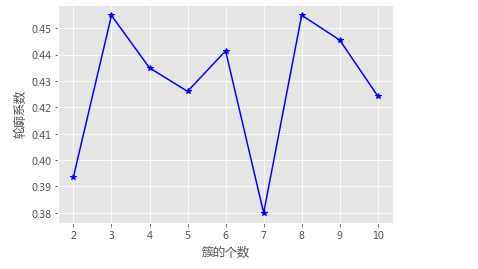
# 利用Kmeans聚类
kmeans = cluster.KMeans(n_clusters = 3)
# 模型拟合
kmeans.fit(X)
Province['kmeans_label'] = kmeans.labels_
# 绘制Kmeans聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'kmeans_label', data = Province,
markers = ['d','^','o'], fit_reg = False, legend = False)
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
plt.show()
吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
- 吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn import mod ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(4)——python数据处理工具:Pandas
# 导入模块import pandas as pdimport numpy as np # 构造序列gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])print(g ...
随机推荐
- SQL Server Reporting Service 报错:报表服务器无法解密用于访问报表服务器数据库中的敏感数据或加密数据的对称密钥,必须还原备份密钥或删除所有加密的内容。
出现这个问题,可以通过reporting services 配置管理工具来处理 首先,打开配置管理工具,连接. 在左侧的导航选项中选择Encryption Keys,将出现如图所示的界面,在右侧点击d ...
- 大快DKhadoop安装教程与常见问题汇总
上周分别就DKHadoop的安装准备工作以及服务器操作系统配置写了两篇分享的文章,这是个人第一次尝试写一个系统性的分享文章,必然会有很多疏漏的地方,还望见谅吧.今天分享的是DKHadoop安装以及常见 ...
- Android getprop setprop watchprops用法
转载请注明出处:https://www.cnblogs.com/lialong1st/p/10172973.html 在安卓系统中,当你写了一个脚本,已经添加到开机启动 init.rc 中,即使脚本中 ...
- android datepicker monthOfYear getMonth(): 获取当前月(注意:返回数值为0..11,需要自己+1来显示).....
关键点: 1. getMonth(): 获取当前月(注意:返回数值为0..11,需要自己+1来显示) 2. 初始年(译者注:注意使用new Date()初始化年时,需要+1900,如下:dat ...
- 【Spring学习笔记-MVC-12】Spring MVC视图解析器之ResourceBundleViewResolver
场景 当我们设计程序界面的时候,中国人希望界面是中文,而美国人希望界面是英文. 我们当然希望后台代码不需改变,系统能够通过配置文件配置,来自己觉得是显示中文界面还是英文界面. 这是,Spring mv ...
- ansible的安装过程 和基本使用
之前安装了一遍,到最后安装成功的时候出现了这种问题: [root@localhost ~]# ansible webserver -m command -a 'uptime' ............ ...
- js区分大小写
JavaScript 区分大小写 区分大小写 JavaScript 语言是区分大小写的,不管是命名变量还是使用关键字的时候. 如前面 alert弹出提示框 的例子,如果将 alert 命令改为 ALE ...
- red hat官方的rhel操作系统版本号与内核版本号的对应关系
原文在如下网址:https://access.redhat.com/articles/3078 The tables below list the major and minor Red Hat En ...
- 1005 Spell It Right (20 分)
1005 Spell It Right (20 分) Given a non-negative integer N, your task is to compute the sum of all th ...
- 关于input=file的用法
<input type="file"/>这个东西是用来上传图片用的. 1,但是存在一下问题但是在在各个浏览器下的显示是不一样的 IE下: IE之外的浏览器: 2.如果不 ...