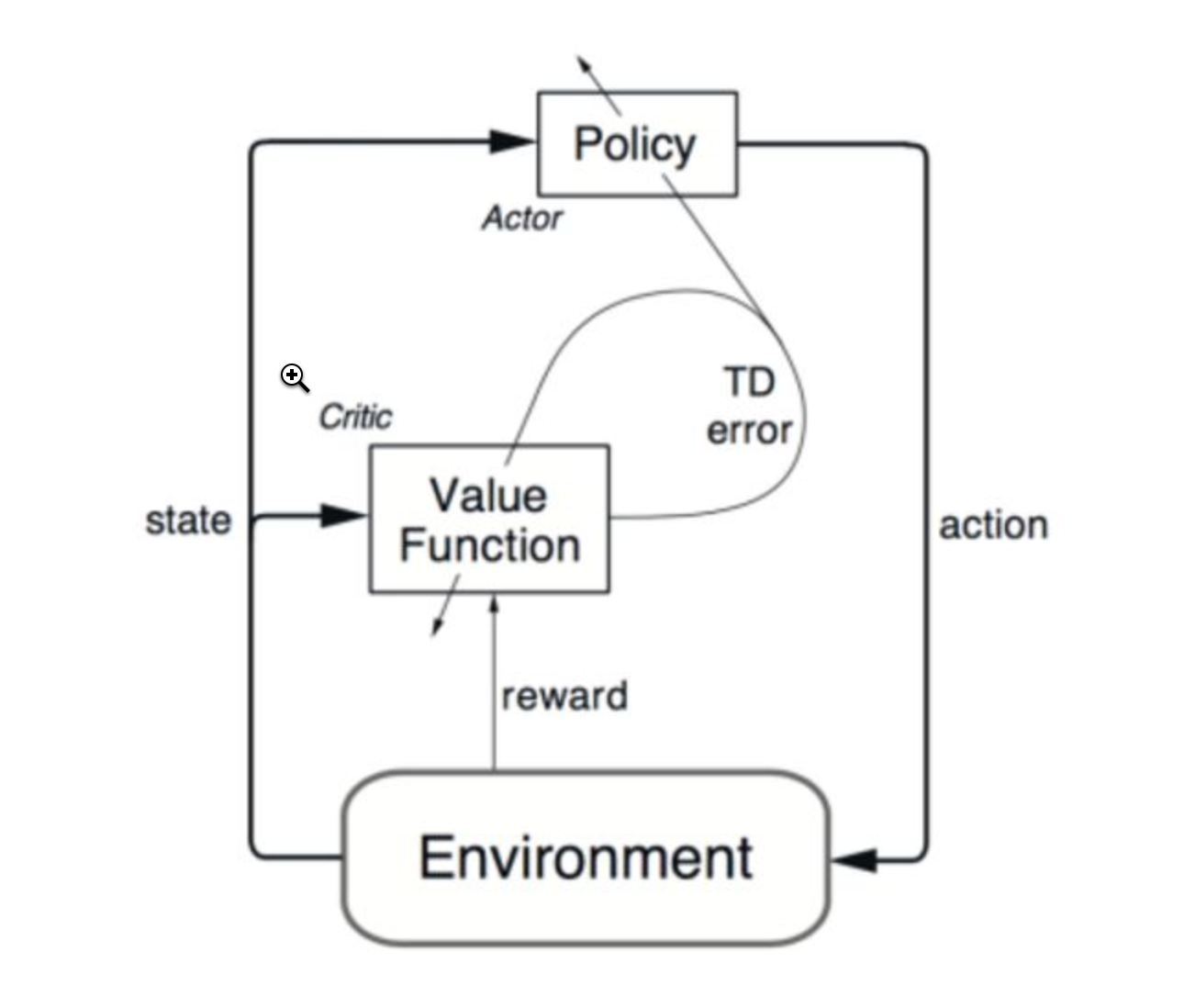
深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合
import sys
import gym
import pylab
import numpy as np
from keras.layers import Dense
from keras.models import Sequential
from keras.optimizers import Adam EPISODES = 1000 # A2C(Advantage Actor-Critic) agent for the Cartpole
# actor-critic算法结合了value-based和policy-based方法
class A2CAgent:
def __init__(self, state_size, action_size):
# if you want to see Cartpole learning, then change to True
self.render = True
self.load_model = False
# get size of state and action
self.state_size = state_size
self.action_size = action_size
self.value_size = 1 # These are hyper parameters for the Policy Gradient
self.discount_factor = 0.99
self.actor_lr = 0.001
self.critic_lr = 0.005 # create model for policy network
self.actor = self.build_actor()
self.critic = self.build_critic() if self.load_model:
self.actor.load_weights("./save_model/cartpole_actor.h5")
self.critic.load_weights("./save_model/cartpole_critic.h5") # approximate policy and value using Neural Network
# actor: state is input and probability of each action is output of model
def build_actor(self):#actor网络:state-->action
actor = Sequential()
actor.add(Dense(24, input_dim=self.state_size, activation='relu',
kernel_initializer='he_uniform'))
actor.add(Dense(self.action_size, activation='softmax',
kernel_initializer='he_uniform'))
actor.summary()
# See note regarding crossentropy in cartpole_reinforce.py
actor.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=self.actor_lr))
return actor # critic: state is input and value of state is output of model
def build_critic(self):#critic网络:state-->value,Q值
critic = Sequential()
critic.add(Dense(24, input_dim=self.state_size, activation='relu',
kernel_initializer='he_uniform'))
critic.add(Dense(self.value_size, activation='linear',
kernel_initializer='he_uniform'))
critic.summary()
critic.compile(loss="mse", optimizer=Adam(lr=self.critic_lr))
return critic # using the output of policy network, pick action stochastically
def get_action(self, state):
policy = self.actor.predict(state, batch_size=1).flatten()#根据actor网络预测下一步动作
return np.random.choice(self.action_size, 1, p=policy)[0] # update policy network every episode
def train_model(self, state, action, reward, next_state, done):
target = np.zeros((1, self.value_size))#(1,1)
advantages = np.zeros((1, self.action_size))#(1, 2) value = self.critic.predict(state)[0]#critic网络预测的当前q值
next_value = self.critic.predict(next_state)[0]#critic网络预测的下一个q值 '''
理解下面部分
'''
if done:
advantages[0][action] = reward - value
target[0][0] = reward
else:
advantages[0][action] = reward + self.discount_factor * (next_value) - value#acotr网络
target[0][0] = reward + self.discount_factor * next_value#critic网络 self.actor.fit(state, advantages, epochs=1, verbose=0)
self.critic.fit(state, target, epochs=1, verbose=0) if __name__ == "__main__":
# In case of CartPole-v1, maximum length of episode is 500
env = gym.make('CartPole-v1')
# get size of state and action from environment
state_size = env.observation_space.shape[0]
action_size = env.action_space.n # make A2C agent
agent = A2CAgent(state_size, action_size)
scores, episodes = [], [] for e in range(EPISODES):
done = False
score = 0
state = env.reset()
state = np.reshape(state, [1, state_size]) while not done:
if agent.render:
env.render() action = agent.get_action(state)
next_state, reward, done, info = env.step(action)
next_state = np.reshape(next_state, [1, state_size])
# if an action make the episode end, then gives penalty of -100
reward = reward if not done or score == 499 else -100 agent.train_model(state, action, reward, next_state, done)#每执行一次action训练一次 score += reward
state = next_state if done:
# every episode, plot the play time
score = score if score == 500.0 else score + 100
scores.append(score)
episodes.append(e)
pylab.plot(episodes, scores, 'b')
pylab.savefig("./save_graph/cartpole_a2c.png")
print("episode:", e, " score:", score) # if the mean of scores of last 10 episode is bigger than 490
# stop training
if np.mean(scores[-min(10, len(scores)):]) > 490:
sys.exit() # save the model
if e % 50 == 0:
agent.actor.save_weights("./save_model/cartpole_actor.h5")
agent.critic.save_weights("./save_model/cartpole_critic.h5")
深度增强学习--Actor Critic的更多相关文章
- 深度增强学习--DDPG
DDPG DDPG介绍2 ddpg输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测 公式推导 推导 代码实现的gym的pendulum游戏,这个游 ...
- 深度增强学习--A3C
A3C 它会创建多个并行的环境, 让多个拥有副结构的 agent 同时在这些并行环境上更新主结构中的参数. 并行中的 agent 们互不干扰, 而主结构的参数更新受到副结构提交更新的不连续性干扰, 所 ...
- 深度增强学习--DPPO
PPO DPPO介绍 PPO实现 代码DPPO
- 深度增强学习--DQN的变形
DQN的变形 double DQN prioritised replay dueling DQN
- 深度增强学习--Policy Gradient
前面都是value based的方法,现在看一种直接预测动作的方法 Policy Based Policy Gradient 一个介绍 karpathy的博客 一个推导 下面的例子实现的REINFOR ...
- 深度增强学习--Deep Q Network
从这里开始换个游戏演示,cartpole游戏 Deep Q Network 实例代码 import sys import gym import pylab import random import n ...
- 常用增强学习实验环境 II (ViZDoom, Roboschool, TensorFlow Agents, ELF, Coach等) (转载)
原文链接:http://blog.csdn.net/jinzhuojun/article/details/78508203 前段时间Nature上发表的升级版Alpha Go - AlphaGo Ze ...
- 马里奥AI实现方式探索 ——神经网络+增强学习
[TOC] 马里奥AI实现方式探索 --神经网络+增强学习 儿时我们都曾有过一个经典游戏的体验,就是马里奥(顶蘑菇^v^),这次里约奥运会闭幕式,日本作为2020年东京奥运会的东道主,安倍最后也已经典 ...
- 增强学习 | AlphaGo背后的秘密
"敢于尝试,才有突破" 2017年5月27日,当今世界排名第一的中国棋手柯洁与AlphaGo 2.0的三局对战落败.该事件标志着最新的人工智能技术在围棋竞技领域超越了人类智能,借此 ...
随机推荐
- Python 模拟SQL对文件进行增删改查
#!/usr/bin/env python # _*_ coding:UTF-8 _*_ # __auth__: Dalhhin # Python 3.5.2,Pycharm 2016.3.2 # 2 ...
- elasticsearch.helpers.ScanError: Scroll request has only succeeded on xx shards
# 当index=''为空时出现此错误
- 【bzoj2212&3702】二叉树
线段树合并入门题. 分别计算左子树的逆序对,右子树的逆序对,合并的时候计算贡献. #include<bits/stdc++.h> #define N 8000005 using names ...
- JS实现上下左右对称的九九乘法表
JS实现上下左右对称的九九乘法表 css样式 <style> table{ table-layout:fixed; border-collapse:collapse; } td{ padd ...
- 使用Python获取计算机名,ip地址,mac地址等等
获取计算机名 # 获取计算机名,常用的方法有三种 import os import socket # method one name = socket.gethostname() print(name ...
- [ Python - 2 ] 常见内置函数
1. abs(): 绝对值 In [1]: abs(-10) Out[1]: 10 2. all(): 当参数中任何一个值为False时,all() 都为False all(iterable) ...
- 手机端iscoll插件的使用方法
除了以前版本的iScroll的特性以外,iScroll 4还包括如下的特性: (1)缩放(Pinch/Zoom) (2)拉动刷新(Pull up/down to refresh) (3)速度和性能提升 ...
- OC学习——OC中的@protocol(@required、@optional)、代理设计模式
一.什么是协议? 1.协议声明了可以被任何类实现的方法 2.协议不是类,它是定义了一个其他对象可以实现的接口 3.如果在某个类中实现了协议中的某个方法,也就是这个类实现了那个协议. 4.协 ...
- Liquibase 快速开始
Step 1 :创建Changelog文件,所有的数据库变动都会保存在Changelog文件中 <?xml version="1.0" encoding="UTF- ...
- 《锋利的JQuery》读书要点笔记3——事件和动画
第四章 jQuery中的事件和动画 JS和HTML的交互是通过用户和浏览器操作页面时引发的事件来处理的,事件由浏览器自动生成. 4.1 jQuery中的事件 1. 加载DOM 这里主要是搞明白wind ...