32、reduceByKey和groupByKey对比
一、groupByKey
1、图解
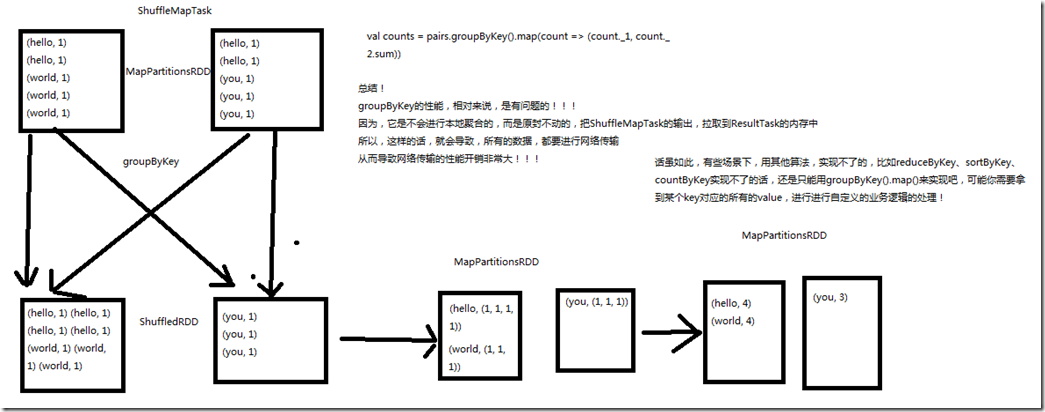
val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2.sum)) groupByKey的性能,相对来说,是有问题的; 因为,它是不会进行本地聚合的,而是原封不动的,把ShuffleMapTask的输出,拉取到ResultTask的内存中,所以这样的话,会导致,所有的数据,都要进行网络传输,
从而导致网络传输的性能开销很大; 但是,有些场景下,用其他算法实现不了的,比如reduceByKey,sortByKey,countByKey实现不了的话,还是只能用groupByKey().map()来实现,比如可能你需要拿到
某个key对应的所有的value,进行自定义的业务逻辑处理;
二、reduceByKey
1、图解
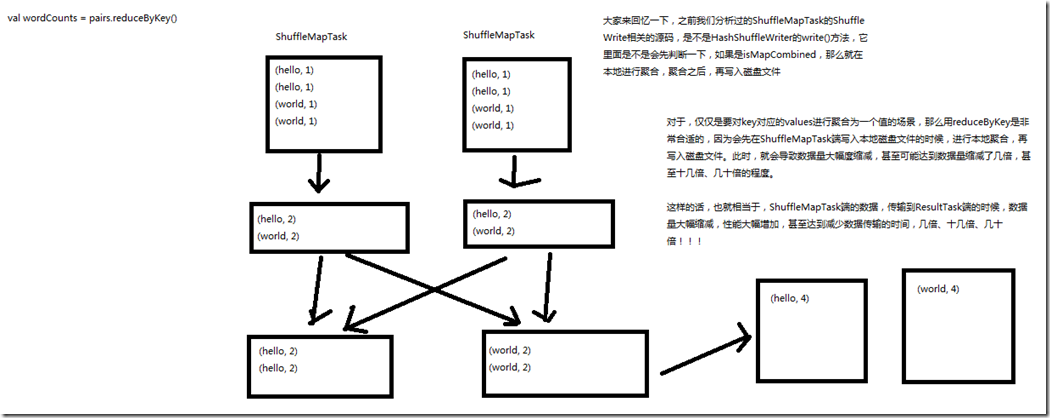
val counts = pairs.reduceByKey(_ + _) HashShuffleWriter的writer()方法,是先判断了一下,如果是isMapCombined,那么就在本地进行聚合,聚合之后,再写入磁盘文件; 对于,仅仅是要对key对应的values进行聚合为一个值的场景,用reduceByKey是非常合适的,因为会先在ShuffleMapTask端写入本地磁盘文件的时候,
进行本地聚合,再写入磁盘文件,此时,就会导致数据量大幅度缩减,甚至可能达到数据量缩减了几倍,甚至十几倍、几十倍的程度; 这样的话,也就相当于,ShuffleMapTask端的数据,传输到ReduceTasl端的数据,数据量大幅度缩减,性能大幅度增加,甚至达到减少数据量的时间,几倍、十几倍、几十倍; 如果能用reduceByKey,那就用reduceByKey,因为它会在map端,先进行本地combine,可以大大减少要传输到reduce端的数据量,减小网络传输的开销。
只有在reduceByKey处理不了时,才用groupByKey().map()来替代。
32、reduceByKey和groupByKey对比的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
- reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的.在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式.这种格式很像Pyth ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- scala flatmap、reduceByKey、groupByKey
1.test.txt文件中存放 asd sd fd gf g dkf dfd dfml dlf dff gfl pkdfp dlofkp // 创建一个Scala版本的Spark Context va ...
- spark新能优化之reduceBykey和groupBykey的使用
val counts = pairs.reduceByKey(_ + _) val counts = pairs.groupByKey().map(wordCounts => (wordCoun ...
- 【spark】常用转换操作:reduceByKey和groupByKey
1.reduceByKey(func) 功能: 使用 func 函数合并具有相同键的值. 示例: val list = List("hadoop","spark" ...
随机推荐
- UOJ348 WC2018 州区划分 状压DP、欧拉回路、子集卷积
传送门 应该都会判欧拉回路吧(雾 考虑状压DP:设\(W_i\)表示集合\(i\)的点的权值和,\(route_i\)表示点集\(i\)的导出子图中是否存在欧拉回路,\(f_i\)表示前若干个城市包含 ...
- [winfrom]C#中使用SendMessage
在C#中,程序采用了的驱动采用了事件驱动而不是原来的消息驱动,虽然.net框架提供的事件已经十分丰富,但是在以前的系统中定义了丰富的消息对系统的编程提供了方便的实现方法,因此在C#中使用消息有时候还是 ...
- 转 Json数据格式化
/// <summary> /// JSON字符串格式化 /// </summary> /// <param name="json"></ ...
- winform实现图片的滑动效果
使用winform实现图片的滑动效果(类似网站首页图片滑动切换效果),结果实现了,但是效果其实不是很理想.也许有更好的方法. Timer timerSlide = null; //当前 ...
- java容易混淆的概念
容易混淆的内容 1.JVM内存模型 2.Java内存模型 3.Java对象模型 JVM内存模型 1.堆 2.虚拟机栈 3.本地方法栈 4.程序计数器 5.方法区 Java内存模型 Java堆和方法区的 ...
- PHP/Python---百钱百鸡简单实现及优化
公鸡5块钱一只,母鸡3块钱一只,小鸡一块钱3只,用100块钱买一百只鸡,问公鸡,母鸡,小鸡各要买多少只? 今天看到这题很简单 ,但是随手写出来后发现不是最优的
- HDFS读流程
客户端先与NameNode通信,获取block位置信息,之后线性地先取第一个块,然后接二连三地获取,取回一个块时会进行MD5验证,验证通过后会使read顺利进行完,当最终读完所有的block块之后,拼 ...
- MySQL Backup--xtrabackup与Bulk Load for Create Index
场景描述:主从使用MySQL 5.7.19 1.从库上使用xtrabackup进行热备. 2.主库行执行DDL创建索引: ALTER TABLE `tb_xxx` ADD INDEX idx_good ...
- Flask之DButils
一.简介 在使用pymysql时遇到一些问题,就是当用户访问过多时,pymysql它同一时间只能处理一个线程.大大的降低了效率,对此我们基于DBUtils实现数据链接池. 二.安装与使用 创建数据库连 ...
- windows IIS安装php服务及配置
windows IIS安装php服务及配置 启动IIS服务 打开 "控制面板" => "程序" => "启用或关闭Window功能&quo ...