Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
点击了解更多Python课程>>>
Python分布式爬虫开发搜索引擎 Scrapy实战视频教程
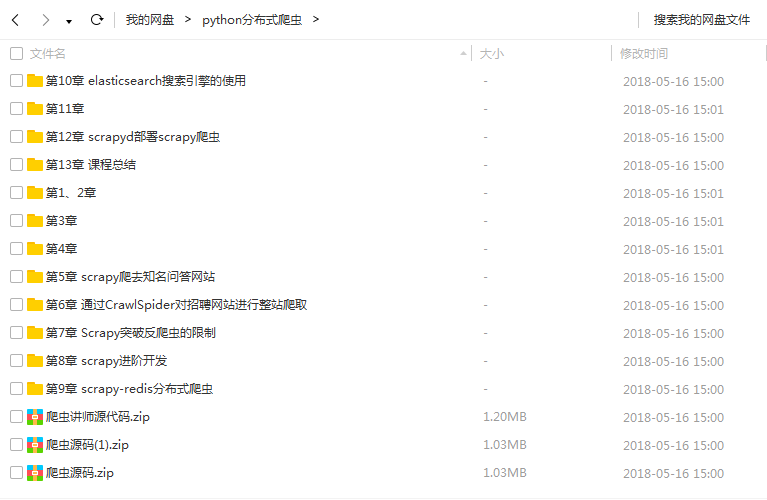
课程目录
|--第01集 教程推介 98.23MB
|--第02集 windows下搭建搭建环境 351.68MB
|--第03集 爬虫基础知识回顾 232.76MB|
|--第04集 scrapy爬取知名技术文章网站 276.26MB|
|--第05集 scrapy爬取知名问答网站 428.26MB
|--第06集 通过CrawlSpider对招聘网站进行整站爬取 332.8MB
|--第07集 Scrapy突破反爬虫的限制 84.67MB
|--第08集 scrapy进阶搭建 360.5MB
|--第09集 scrapy-redis分布式爬虫 144.1MB
|--第10集 elasticsearch搜索引擎的使用 225.76MB
|--第11集 django实现搜索网站 104.55MB
|--第12集 scrapyd布署scrapy爬虫 305.46MB
|--第13集 教程概括 376.65MB

支付后联系:QQ17028139 领取以上全部教程!
Python分布式爬虫开发搜索引擎 Scrapy实战视频教程的更多相关文章
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作、增、删、改、查
第三百六十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)基本的索引和文档CRUD操作.增.删.改.查 elasticsearch(搜索引擎)基本的索引 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目
第三百七十二节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapyd部署scrapy项目 scrapyd模块是专门用于部署scrapy项目的,可以部署和管理scrapy项目 下载地址:h ...
- 第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
随机推荐
- JavaScript进阶 - 第6章 事件响应,让网页交互
6-1什么是事件 JavaScript 创建动态页面.事件是可以被 JavaScript 侦测到的行为. 网页中的每个元素都可以产生某些可以触发 JavaScript 函数或程序的事件. 比如说,当用 ...
- C# 数据库连接字符串拼接
string connectionString = string.Format(@"Data Source={0};User ID={1};Password={2};Initial Cata ...
- GUI的最终选择 Tkinter(八):Message组件、Spinbox组件、PanedWindow组件、Toplevel组件
Message组件 Message(消息)组件是Label组件的变体,用于显示多行文本消息,Message组件能够自动执行,并调整文本的尺寸使其适应给定的尺寸. from tkinter import ...
- csu 1554: SG Value 思维题
http://acm.csu.edu.cn/csuoj/problemset/problem?pid=1554 这题在比赛的时候居然没想出来,然后发现居然是做过的题目的变种!!!! 先不考虑插入操作, ...
- Funsioncharts 线图 破解
在线示例:http://jsfiddle.net/henley/xnozyLa8/2/ 下载:http://files.cnblogs.com/files/ycdx2001/chart.zip
- mui实现图片更换(暂未上传)
页面中有默认的图片,触发type为file的input时,更换图片,这个是mui移动端的项目,算了,不多说,开码 首先,先在html页面中设置样式,样式我就不给了,贴个布局 <div class ...
- JS根据选择的日期计算年龄
本例中用的是easyUI的datebox $('#cal_birthday').datebox({ onSelect: function(date){ //根据选则的日期计算年龄 //alert(da ...
- ubuntu下irobot串口通讯
在window下以前就`有一个现成的串口代码.想移植到ubuntu下,发现都不一样了.要重新找个. 折腾了一上午之后,发现自己写这个串口通讯还是有一点难度. 于是,用了github上 Erick Co ...
- PHP中调用SVN命令更新网站方法(解决文件名包含中文更新失败的问题)
想说写一个通过网页就可以执行 SVN 升级的程序,结果并不是我想得那样简单,有一些眉角需要注意的说. 先以 Apache 的用户帐号执行 SVN checkout,这样 Apache 才有 SVN 的 ...
- 【虚拟机-远程连接】Azure Linux 虚拟机常见导致无法远程的操作
对Azure虚拟机的一些操作可能会导致无法远程连接,本文罗列了以下导致不能远程连接的场景: 场景1 - 在虚拟机配置IP地址或MAC地址 场景2 - 错误地修改服务的配置文件 场景3 - 误设置防火墙 ...