BIRCH聚类算法原理
在K-Means聚类算法原理中,我们讲到了K-Means和Mini Batch K-Means的聚类原理。这里我们再来看看另外一种常见的聚类算法BIRCH。BIRCH算法比较适合于数据量大,类别数K也比较多的情况。它运行速度很快,只需要单遍扫描数据集就能进行聚类,当然需要用到一些技巧,下面我们就对BIRCH算法做一个总结。
1. BIRCH概述
BIRCH的全称是利用层次方法的平衡迭代规约和聚类(Balanced Iterative Reducing and Clustering Using Hierarchies),名字实在是太长了,不过没关系,其实只要明白它是用层次方法来聚类和规约数据就可以了。刚才提到了,BIRCH只需要单遍扫描数据集就能进行聚类,那它是怎么做到的呢?
BIRCH算法利用了一个树结构来帮助我们快速的聚类,这个数结构类似于平衡B+树,一般将它称之为聚类特征树(Clustering Feature Tree,简称CF Tree)。这颗树的每一个节点是由若干个聚类特征(Clustering Feature,简称CF)组成。从下图我们可以看看聚类特征树是什么样子的:每个节点包括叶子节点都有若干个CF,而内部节点的CF有指向孩子节点的指针,所有的叶子节点用一个双向链表链接起来。
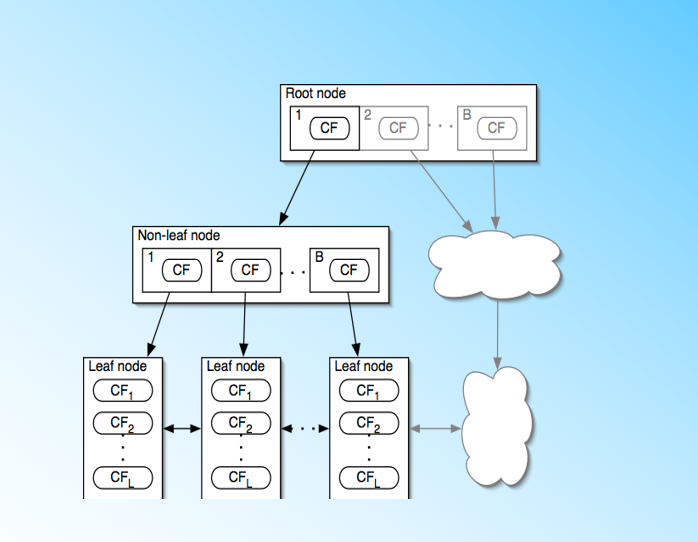
有了聚类特征树的概念,我们再对聚类特征树和其中节点的聚类特征CF做进一步的讲解。
2. 聚类特征CF与聚类特征树CF Tree
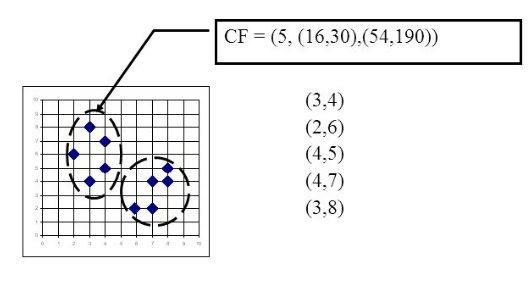
在聚类特征树中,一个聚类特征CF是这样定义的:每一个CF是一个三元组,可以用(N,LS,SS)表示。其中N代表了这个CF中拥有的样本点的数量,这个好理解;LS代表了这个CF中拥有的样本点各特征维度的和向量,SS代表了这个CF中拥有的样本点各特征维度的平方和。举个例子如下图,在CF Tree中的某一个节点的某一个CF中,有下面5个样本(3,4), (2,6), (4,5), (4,7), (3,8)。则它对应的N=5, LS=$(3+2+4+4+3, 4+6+5+7+8) = (16,30)$, SS =$(3^2+2^2+4^2 +4^2+3^2 + 4^2+6^2+5^2 +7^2+8^2) = (54 + 190) = 244$
CF有一个很好的性质,就是满足线性关系,也就是$CF1+CF2 = (N_1+N_2, LS_1+LS_2, SS_1 +SS_2)$。这个性质从定义也很好理解。如果把这个性质放在CF Tree上,也就是说,在CF Tree中,对于每个父节点中的CF节点,它的(N,LS,SS)三元组的值等于这个CF节点所指向的所有子节点的三元组之和。如下图所示:
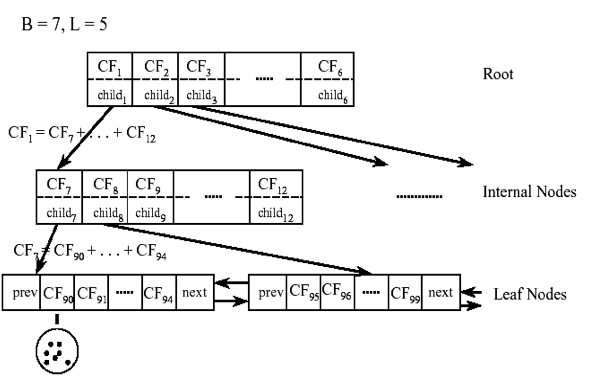
从上图中可以看出,根节点的CF1的三元组的值,可以从它指向的6个子节点(CF7 - CF12)的值相加得到。这样我们在更新CF Tree的时候,可以很高效。
对于CF Tree,我们一般有几个重要参数,第一个参数是每个内部节点的最大CF数B,第二个参数是每个叶子节点的最大CF数L,第三个参数是针对叶子节点中某个CF中的样本点来说的,它是叶节点每个CF的最大样本半径阈值T,也就是说,在这个CF中的所有样本点一定要在半径小于T的一个超球体内。对于上图中的CF Tree,限定了B=7, L=5, 也就是说内部节点最多有7个CF,而叶子节点最多有5个CF。
3. 聚类特征树CF Tree的生成
下面我们看看怎么生成CF Tree。我们先定义好CF Tree的参数: 即内部节点的最大CF数B, 叶子节点的最大CF数L, 叶节点每个CF的最大样本半径阈值T
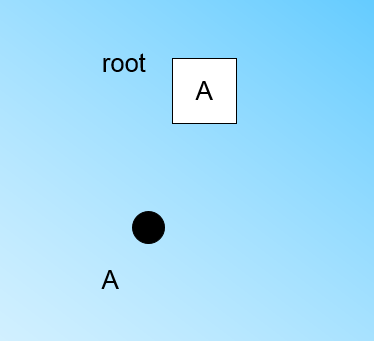
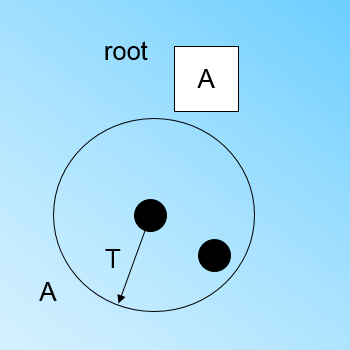
在最开始的时候,CF Tree是空的,没有任何样本,我们从训练集读入第一个样本点,将它放入一个新的CF三元组A,这个三元组的N=1,将这个新的CF放入根节点,此时的CF Tree如下图:
现在我们继续读入第二个样本点,我们发现这个样本点和第一个样本点A,在半径为T的超球体范围内,也就是说,他们属于一个CF,我们将第二个点也加入CF A,此时需要更新A的三元组的值。此时A的三元组中N=2。此时的CF Tree如下图:
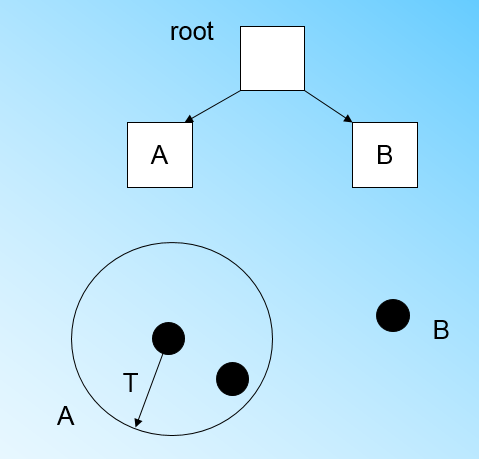
此时来了第三个节点,结果我们发现这个节点不能融入刚才前面的节点形成的超球体内,也就是说,我们需要一个新的CF三元组B,来容纳这个新的值。此时根节点有两个CF三元组A和B,此时的CF Tree如下图:
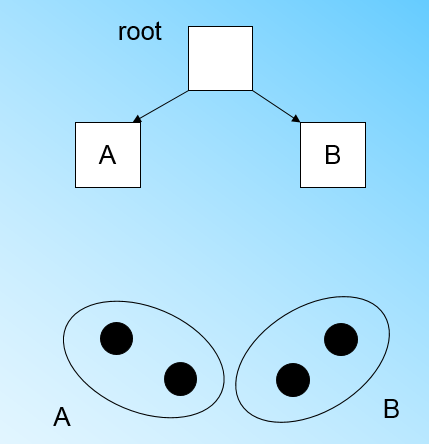
当来到第四个样本点的时候,我们发现和B在半径小于T的超球体,这样更新后的CF Tree如下图:
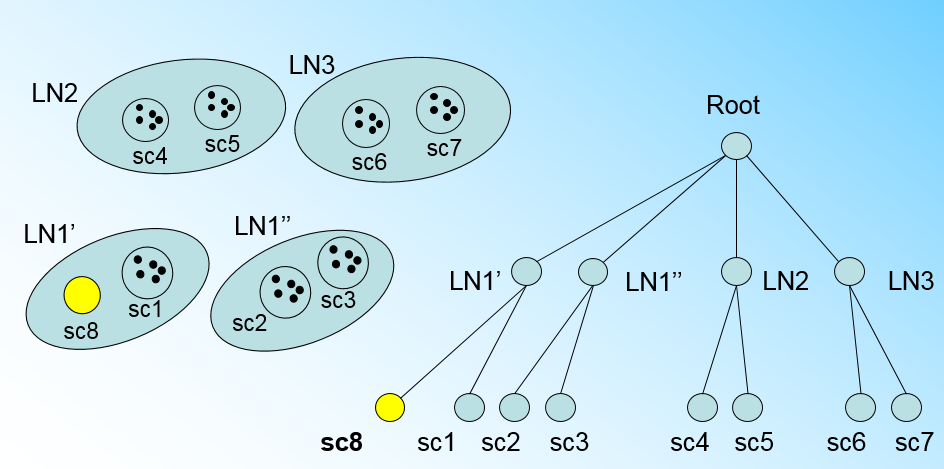
那个什么时候CF Tree的节点需要分裂呢?假设我们现在的CF Tree 如下图, 叶子节点LN1有三个CF, LN2和LN3各有两个CF。我们的叶子节点的最大CF数L=3。此时一个新的样本点来了,我们发现它离LN1节点最近,因此开始判断它是否在sc1,sc2,sc3这3个CF对应的超球体之内,但是很不幸,它不在,因此它需要建立一个新的CF,即sc8来容纳它。问题是我们的L=3,也就是说LN1的CF个数已经达到最大值了,不能再创建新的CF了,怎么办?此时就要将LN1叶子节点一分为二了。
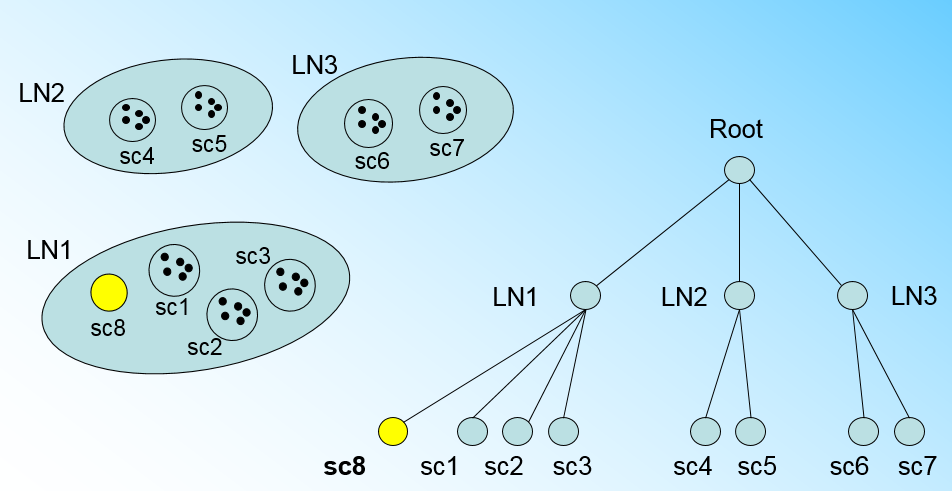
我们将LN1里所有CF元组中,找到两个最远的CF做这两个新叶子节点的种子CF,然后将LN1节点里所有CF sc1, sc2, sc3,以及新样本点的新元组sc8划分到两个新的叶子节点上。将LN1节点划分后的CF Tree如下图:
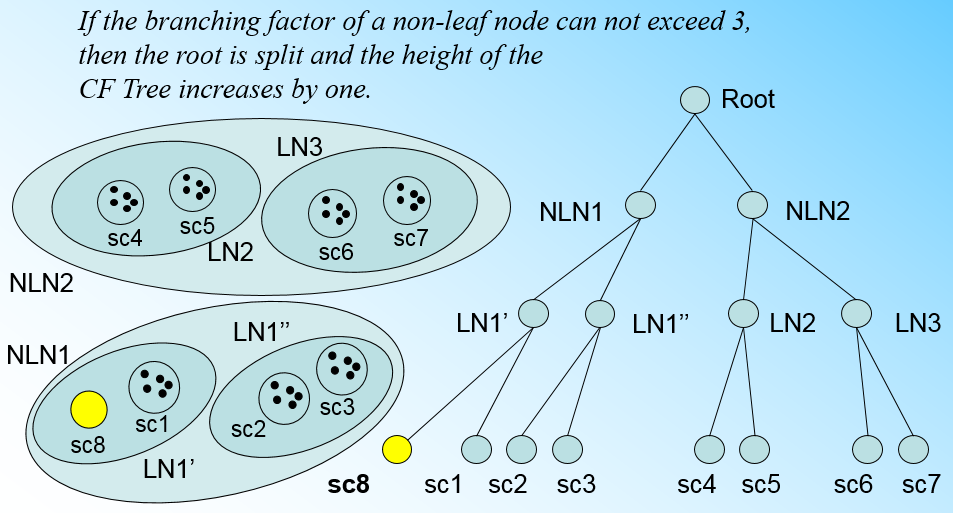
如果我们的内部节点的最大CF数B=3,则此时叶子节点一分为二会导致根节点的最大CF数超了,也就是说,我们的根节点现在也要分裂,分裂的方法和叶子节点分裂一样,分裂后的CF Tree如下图:
有了上面这一系列的图,相信大家对于CF Tree的插入就没有什么问题了,总结下CF Tree的插入:
1. 从根节点向下寻找和新样本距离最近的叶子节点和叶子节点里最近的CF节点
2. 如果新样本加入后,这个CF节点对应的超球体半径仍然满足小于阈值T,则更新路径上所有的CF三元组,插入结束。否则转入3.
3. 如果当前叶子节点的CF节点个数小于阈值L,则创建一个新的CF节点,放入新样本,将新的CF节点放入这个叶子节点,更新路径上所有的CF三元组,插入结束。否则转入4。
4.将当前叶子节点划分为两个新叶子节点,选择旧叶子节点中所有CF元组里超球体距离最远的两个CF元组,分布作为两个新叶子节点的第一个CF节点。将其他元组和新样本元组按照距离远近原则放入对应的叶子节点。依次向上检查父节点是否也要分裂,如果需要按和叶子节点分裂方式相同。
4. BIRCH算法
上面讲了半天的CF Tree,终于我们可以步入正题BIRCH算法,其实将所有的训练集样本建立了CF Tree,一个基本的BIRCH算法就完成了,对应的输出就是若干个CF节点,每个节点里的样本点就是一个聚类的簇。也就是说BIRCH算法的主要过程,就是建立CF Tree的过程。
当然,真实的BIRCH算法除了建立CF Tree来聚类,其实还有一些可选的算法步骤的,现在我们就来看看 BIRCH算法的流程。
1) 将所有的样本依次读入,在内存中建立一颗CF Tree, 建立的方法参考上一节。
2)(可选)将第一步建立的CF Tree进行筛选,去除一些异常CF节点,这些节点一般里面的样本点很少。对于一些超球体距离非常近的元组进行合并
3)(可选)利用其它的一些聚类算法比如K-Means对所有的CF元组进行聚类,得到一颗比较好的CF Tree.这一步的主要目的是消除由于样本读入顺序导致的不合理的树结构,以及一些由于节点CF个数限制导致的树结构分裂。
4)(可选)利用第三步生成的CF Tree的所有CF节点的质心,作为初始质心点,对所有的样本点按距离远近进行聚类。这样进一步减少了由于CF Tree的一些限制导致的聚类不合理的情况。
从上面可以看出,BIRCH算法的关键就是步骤1,也就是CF Tree的生成,其他步骤都是为了优化最后的聚类结果。
5. BIRCH算法小结
BIRCH算法可以不用输入类别数K值,这点和K-Means,Mini Batch K-Means不同。如果不输入K值,则最后的CF元组的组数即为最终的K,否则会按照输入的K值对CF元组按距离大小进行合并。
一般来说,BIRCH算法适用于样本量较大的情况,这点和Mini Batch K-Means类似,但是BIRCH适用于类别数比较大的情况,而Mini Batch K-Means一般用于类别数适中或者较少的时候。BIRCH除了聚类还可以额外做一些异常点检测和数据初步按类别规约的预处理。但是如果数据特征的维度非常大,比如大于20,则BIRCH不太适合,此时Mini Batch K-Means的表现较好。
对于调参,BIRCH要比K-Means,Mini Batch K-Means复杂,因为它需要对CF Tree的几个关键的参数进行调参,这几个参数对CF Tree的最终形式影响很大。
最后总结下BIRCH算法的优缺点:
BIRCH算法的主要优点有:
1) 节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
2) 聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
3) 可以识别噪音点,还可以对数据集进行初步分类的预处理
BIRCH算法的主要缺点有:
1) 由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同.
2) 对高维特征的数据聚类效果不好。此时可以选择Mini Batch K-Means
3) 如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
BIRCH聚类算法原理的更多相关文章
- Kmeans聚类算法原理与实现
Kmeans聚类算法 1 Kmeans聚类算法的基本原理 K-means算法是最为经典的基于划分的聚类方法,是十大经典数据挖掘算法之一.K-means算法的基本思想是:以空间中k个点为中心进行聚类,对 ...
- 【转】K-Means聚类算法原理及实现
k-means 聚类算法原理: 1.从包含多个数据点的数据集 D 中随机取 k 个点,作为 k 个簇的各自的中心. 2.分别计算剩下的点到 k 个簇中心的相异度,将这些元素分别划归到相异度最低的簇.两 ...
- OPTICS聚类算法原理
OPTICS聚类算法原理 基础 OPTICS聚类算法是基于密度的聚类算法,全称是Ordering points to identify the clustering structure,目标是将空间中 ...
- K-Means聚类算法原理
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛.K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体 ...
- K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 第十三篇:K-Means 聚类算法原理分析与代码实现
前言 在前面的文章中,涉及到的机器学习算法均为监督学习算法. 所谓监督学习,就是有训练过程的学习.再确切点,就是有 "分类标签集" 的学习. 现在开始,将进入到非监督学习领域.从经 ...
- 机器学习中K-means聚类算法原理及C语言实现
本人以前主要focus在传统音频的软件开发,接触到的算法主要是音频信号处理相关的,如各种编解码算法和回声消除算法等.最近切到语音识别上,接触到的算法就变成了各种机器学习算法,如GMM等.K-means ...
- 【机器学习】:Kmeans均值聚类算法原理(附带Python代码实现)
这个算法中文名为k均值聚类算法,首先我们在二维的特殊条件下讨论其实现的过程,方便大家理解. 第一步.随机生成质心 由于这是一个无监督学习的算法,因此我们首先在一个二维的坐标轴下随机给定一堆点,并随即给 ...
- 密度峰值聚类算法原理+python实现
密度峰值聚类(Density peaks clustering, DPC)来自Science上Clustering by fast search and find of density peaks ...
随机推荐
- alias导致virtualenv异常的分析和解法
title: alias导致virtualenv异常的分析和解法 toc: true comments: true date: 2016-06-27 23:40:56 tags: [OS X, ZSH ...
- NodeJs之调试
关于调试 当我们只专注于前端的时候,我们习惯性F12,这会给我们带来安全与舒心的感觉. 但是当我们使用NodeJs来开发后台的时候,我想噩梦来了. 但是也别泰国担心,NodeJs的调试是很不方便!这是 ...
- JavaScript权威指南 - 函数
函数本身就是一段JavaScript代码,定义一次但可能被调用任意次.如果函数挂载在一个对象上,作为对象的一个属性,通常这种函数被称作对象的方法.用于初始化一个新创建的对象的函数被称作构造函数. 相对 ...
- JavaScript自定义浏览器滚动条兼容IE、 火狐和chrome
今天为大家分享一下我自己制作的浏览器滚动条,我们知道用css来自定义滚动条也是挺好的方式,css虽然能够改变chrome浏览器的滚动条样式可以自定义,css也能够改变IE浏览器滚动条的颜色.但是css ...
- Python列表去重
标题有语病,其实是这样的: 假设有两个列表 : L1 = [1,2,3,4] ; L2 = [1,2,5,6] 然后去掉L1中包含的L2的元素 直接这样当然是不行的: def removeExists ...
- 谱聚类(spectral clustering)原理总结
谱聚类(spectral clustering)是广泛使用的聚类算法,比起传统的K-Means算法,谱聚类对数据分布的适应性更强,聚类效果也很优秀,同时聚类的计算量也小很多,更加难能可贵的是实现起来也 ...
- CentOS下mysql数据库常用命令总结
mysql数据库使用总结 本文主要记录一些mysql日常使用的命令,供以后查询. 1.更改root密码 mysqladmin -uroot password 'yourpassword' 2.远程登陆 ...
- 深入浅出Redis-redis哨兵集群
1.Sentinel 哨兵 Sentinel(哨兵)是Redis 的高可用性解决方案:由一个或多个Sentinel 实例 组成的Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所 ...
- required
required,这是HTML5中的一个新属性:这是HTML5中input元素中的一个属性. required译为必须的,在input元素中应用这一属性,就表示这一input元素节点是必填的或者必选的 ...
- IT雇员及外包商选择:人品第一
最近,苹果iOS操作系统和智能手机爆出了一个奇葩故障,在播放特定一段五秒钟的视频时能导致手机死机.唯一的解决办法是按住电源键和Home按键进行手机的重启. 第十八届中国国际高新技术成果交易会在深圳举办 ...