scrapy CrawlSpider解析
CrawlSpider继承自Spider, CrawlSpider主要用于有规则的url进行爬取。
先来说说它们的设计区别:
SpiderSpider 类的设计原则是只爬取 start_urls 中的url,而 CrawlSpider 类定义了一些规则 rules 来提供跟进链接 link 的方便机制,从爬取的网页中获取link并继续跟进的工作。
先来看看刚创建一个crawlSpider的爬虫 -t 指定模板为crawlSpider
scrapy genspider -t crawl cf circ.gov.cn
LinkExtractor 的源码:
from scrapy.linkextractors import LinkExtractor

allow :满足括号中”正则表达式”的值会被提取,如果为空,则全部匹配。
deny :与这个正则表达式(或正则表达式列表)不匹配的url一定不提取
allow_domain:会被提取的连接的domains
deny_domains :一定不会被提取链接的domains。
restrict_xpaths :使用xpath表达式,和allow共同作用过滤链接。
restrict_css :使用css选择器
在CrawlSpider源码中最先定义的是类Rule:Rule对象是一个爬取规则的类
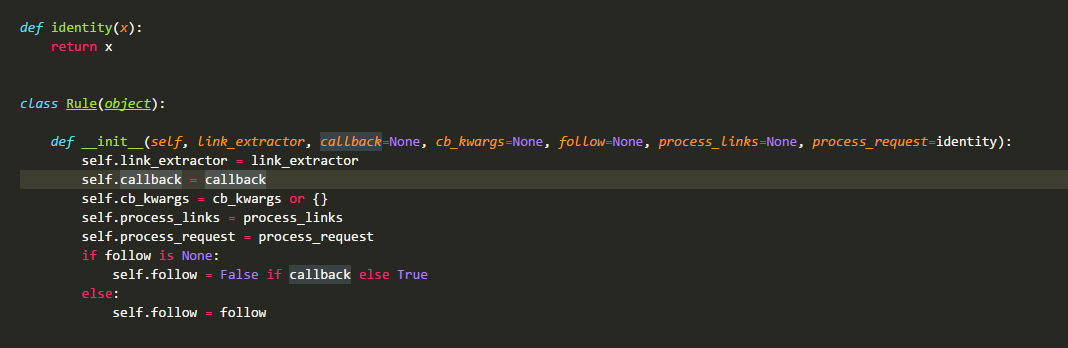
link_extractor :是一个Link Extractor对象。其定义了如何从爬取到的页面提取链接。
callback :是一个callable或string(该Spider中同名的函数将会被调用)。从link_extractor中每获取到链接时将会调用该函数。该回调函数接收一个response作为其第一个参数,并返回一个包含Item以及Request对象(或者这两者的子类)的列表。
cb_kwargs :包含传递给回调函数的参数(keyword argument)的字典。
follow :是一个boolean值,指定了根据该规则从response提取的链接是否需要跟进。如果callback为None,follow默认设置True,否则默认False。
process_links :是一个callable或string(该Spider中同名的函数将会被调用)。从link_extrator中获取到链接列表时将会调用该函数。该方法主要是用来过滤。
process_request :是一个callable或string(该spider中同名的函数都将会被调用)。该规则提取到的每个request时都会调用该函数。该函数必须返回一个request或者None。用来过滤request
CrawlSpider类的源码:
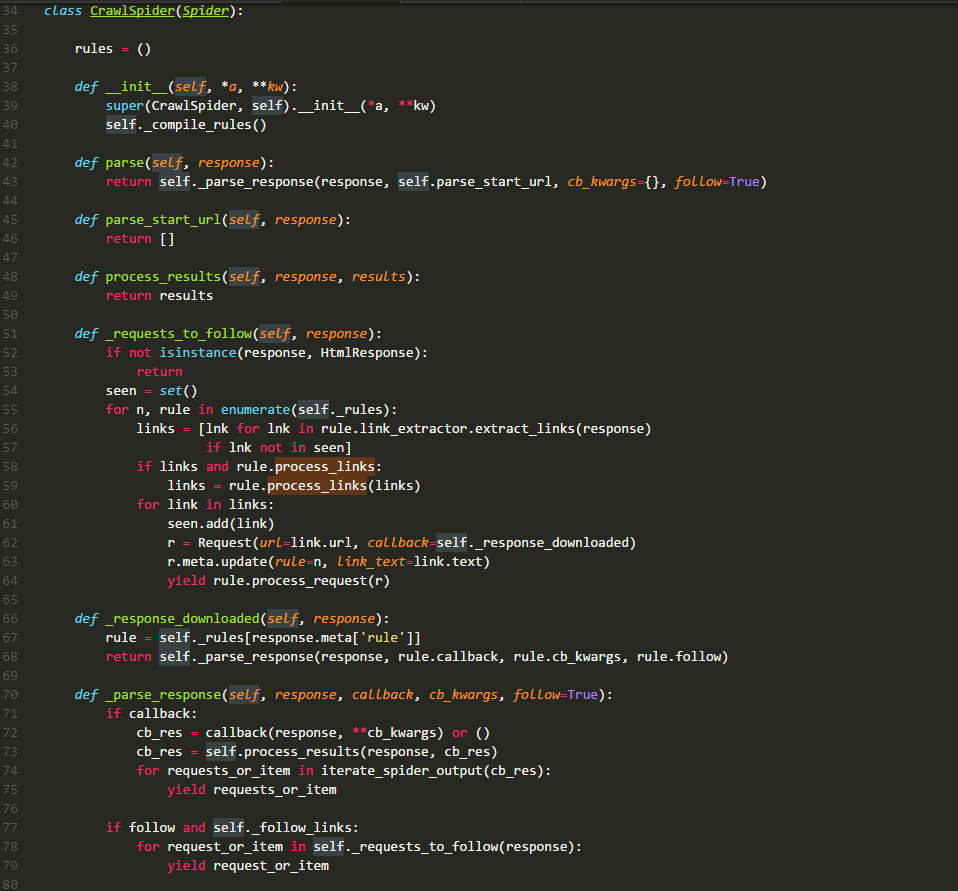

rules :
是一个列表,存储的元素是Rule类的实例,其中每一个实例都定义了一种采集站点的行为。如果有多个rule都匹配同一个链接,那么位置下标最小的一个rule将会被使用。
__init__ :
它主要就是执行了_compile_rules方法
parse :
默认回调方法。源码进行了重写,所以我们自定义的函数,不可以使用这个名,这里直接调用方法 _parse_response ,并把 parse_start_url 方法作为处理response的方法。
parse_start_url :
它的主要作用就是处理parse返回的response,比如提取出需要的数据等,该方法也需要返回item、request或者他们的可迭代对象。它就是一个回调方法,和rule.callback用法一样。
_requests_to_follow :
它的作用就是从response中解析出目标url,并将其包装成request请求。该请求的回调方法是_response_downloaded,这里为request的meta值添加了rule参数,该参数的值是这个url对应rule在rules中的下标。
_response_downloaded :
该方法是方法 _requests_to_follow 的回调方法,作用就是调用 _parse_response 方法,处理下载器返回的 response ,设置 response 的处理方法为 rule.callback 方法。
_parse_response :
该方法将 resposne 交给参数callback代表的方法去处理,然后处理callback方法的requests_or_item。再根据rule.follow and spider._follow_links来判断是否继续采集,如果继续那么就将response交给_requests_to_follow方法,根据规则提取相关的链接。spider._follow_links的值是从settings的CRAWLSPIDER_FOLLOW_LINKS值获取到的。
_compile_rules :
作用就是将rule中的字符串表示的方法改成实际的方法,方便以后使用。
from_crawler :
用于创建,在scrapy源码中这种创建方式比较多
整个数据的流向如下图所示:

示例:
1.创建项目
scrapy startproject circ
2. 创建crawl爬虫
cd circ
scrapy genspider -t crawl cf circ.gov.cn
3.编写cf.py
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
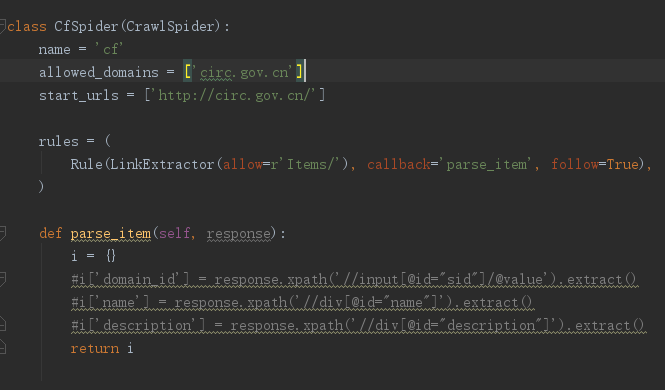
import re class CfSpider(CrawlSpider):
name = 'cf'
allowed_domains = ['circ.gov.cn']
start_urls = ['http://www.circ.gov.cn/web/site0/tab5240/module14430/page1.htm'] #定义提取url地址规则
rules = (
#LinkExtractor 连接提取器,提取url地址
#callback 提取出来的url地址的response会交给callback处理
#follow 当前url地址的响应是够重新进过rules来提取url地址,
Rule(LinkExtractor(allow=r'/web/site0/tab5240/info\d+\.htm'), callback='parse_item'),
Rule(LinkExtractor(allow=r'/web/site0/tab5240/module14430/page\d+\.htm'),follow=True),
) #parse函数有特殊功能,不能定义
def parse_item(self, response):
item = {}
item["title"] = re.findall("<!--TitleStart-->(.*?)<!--TitleEnd-->",response.body.decode())[0]
item["publish_date"] = re.findall("发布时间:(20\d{2}-\d{2}-\d{2})",response.body.decode())[0]
print(item)
scrapy CrawlSpider解析的更多相关文章
- scrapy -->CrawlSpider 介绍
scrapy -->CrawlSpider 介绍 1.首先,通过crawl 模板新建爬虫: scrapy genspider -t crawl lagou www.lagou.com 创建出来的 ...
- scrapy初步解析源码即深度使用
scrapy深度爬虫 ——编辑:大牧莫邪 本章内容 深度爬虫概述 scrapy Spider实现的深度爬虫 scrapy CrawlSpdier实现的深度爬虫 案例操作 课程内容 1. 深度爬虫概述 ...
- scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的. 参与过网站后台开发的应该会知道,网站的url都是有一定规则的.像dj ...
- Scrapy - CrawlSpider爬虫
crawlSpider 爬虫 思路: 从response中提取满足某个条件的url地址,发送给引擎,同时能够指定callback函数. 1. 创建项目 scrapy startproject mysp ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- scrapy递归解析和post请求
递归解析 递归爬取解析多页页面数据 每一个页面对应一个url,则scrapy工程需要对每一个页码对应的url依次发起请求,然后通过对应的解析方法进行作者和段子内容的解析. 实现方案: 1.将每一个页码 ...
- Scrapy CrawlSpider源码分析
crawl.py中主要包含两个类: 1. CrawlSpider 2. Rule link_extractor:传LinkExtractor实例对象 callback:传”func_name“ cb_ ...
- 别再滥用scrapy CrawlSpider中的follow=True
对于刚接触scrapy的同学来说, crawlspider中的rule是比较难理解的, 很可能驾驭不住. 而且笔者在YouTube中看到许多公开的演讲都都错用了follow这一选项, 所以今天就来仔细 ...
- scrapy架构解析
随机推荐
- cmd 执行Dcpromo错误:在该 SKU 上不支持 Active Directory 域服务安装向导,Windows Server 2008 R2 Enterprise 配置AD(Active Directory)域控制器
今天,要安装AD域控制器,运行dcpromo结果提示:在该 SKU 上不支持 Active Directory 域服务安装向导. 以前弄的时候直接就通过了,这次咋回事?终于搞了大半天搞定了. 主要原因 ...
- 使用 whistle 替代本地 nginx/webpack 服务
加入鹅厂之后,我发现团队都在用一款叫做 Whistle 的工具,起初我以为这只是一款类似 Fiddler/Charles 的普通货色.然鹅,发现下面这两种用法之后,我把自己的膝盖摘下来献给了制作这款工 ...
- iOS可视化动态绘制八种排序过程(Swift版)
前面几篇博客都是关于排序的,在之前陆陆续续发布的博客中,我们先后介绍了冒泡排序.选择排序.插入排序.希尔排序.堆排序.归并排序以及快速排序.俗话说的好,做事儿要善始善终,本篇博客就算是对之前那几篇博客 ...
- Markdown 插入图片技巧
在使用Markdown编写博客或文件的时候,经常会需要插入图片.如果使用Markdown语法,我们会发现调整图片的大小会是个问题. 所以推荐使用另一种办法插入图片,使用HTML语法,示例如下: < ...
- Struts自动装配和四种放入Session作用域的方式
---恢复内容开始--- Struts三种自动装配的方式 第一种在Action类中定义和表单name相同的成员变量. 首先你定义一个Action类 页面: 第二种把成员变量提取到一个类中, 在Act ...
- mysql的学习笔记(三)
1.外键约束(保持数据一致,完整.实现一对多或一对一) 父表(参照的表)和子表(有外键列的表)必须使用相同的存储引擎InnoDB,禁止使用临时表. 外键列和参照列必须具有相似的数据类型.其中数字的长度 ...
- 用消息队列和socket实现聊天系统
前言:最近在学进程间通信,所以做了一个小项目练习一下.主要用消息队列和socket(UDP)实现这个系统,并数据库存储数据,对C语言操作不熟悉的可以参照我的这篇博客:https://www.cnblo ...
- HttpClient在.NET Core中的正确打开方式
问题来源 长期以来,.NET开发者都通过下面的方式发送http请求: using (var httpClient = new HttpClient()) { var response = await ...
- C#语法——await与async的正确打开方式
C#5.0推出了新语法,await与async,但相信大家还是很少使用它们.关于await与async有很多文章讲解,但有没有这样一种感觉,你看完后,总感觉这东西很不错,但用的时候,总是想不起来,或者 ...
- 在嵌入式设备中使用 JavaScript 的前景
by Conmajia PC上的JavaScript已经发展到ECMAScript 6(ES6),马上ES10都快出来了(虽然还是草案),但是硬件上的JS却很少听说.这几年手持设备/可穿戴设备的发展非 ...