爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据
为了入门scrapy框架,昨天写了一个爬取静态小说网站的小程序
下面我们尝试爬取全书网中网游动漫类小说的书籍信息。
一、准备阶段
明确一下爬虫页面分析的思路:
对于书籍列表页:我们需要知道打开单本书籍的地址、以及获取点开下一页书籍列表页的链接
对于书籍信息页面,我们需要找到提取:(书名、作者、书本简介、书本连载状态)这四点信息
爬虫流程:书籍列表页中点开一本书→提取每一本书的书籍信息;当一页书籍列表页的书籍全部被采集以后,按照获取的下一页链接打开新的商户及列表页→点开一本书的信息→提取每一本书的信息……
二、页面分析
首先,我们先对爬取数据要打开的第一页页面进行分析。
除了使用开发者工具以外,我们还可以使用scrapy shell <url>命令,可以进行前期的爬取实验,从而提高开发的效率。
首先打开cmd(前提必须是安装好了scrapy~,这里就不说怎么按照scrapy了)
输入scrapy shell +<要分析的网址>
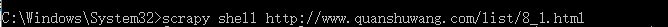
可以得到一个这样的结果
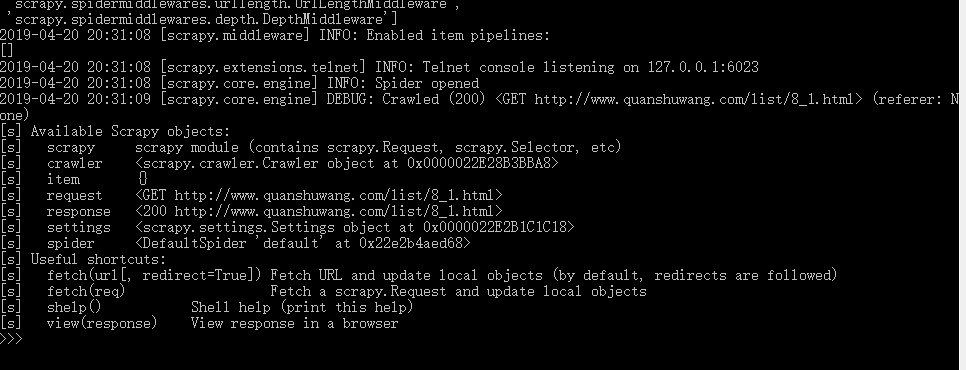
运行完这条命令以后,scrapy shell 会用url参数构造一个request对象,并且提交给scrapy引擎,页面下载完以后程序进入一个pyhon shell中,我们可以调用view函数使用浏览器显示response所包含的页面

*进行页面分析的时候view函数解析的页更加可靠。
弹出页面如下:

通过观察源代码,可以发现所有书籍link信息前缀为"http://www.quanshuwang.com/book_"
此时我们可以尝试在scrapy shell中提取这些信息
这里使用LinkExtractor提取这些链接
在scrapy shell 输入信息与展示信息如下:

随后我们寻找下一页标签的链接,查看源代码可以发现在一个class 为next的a标签中

在scrapy shell中尝试提取,发现可以成功提取到目的link

接下来分析单页书籍信息
处理思路和分析书籍页面信息一样,获取网页
在shell中通过fetch函数下载书籍信息页面,然后再通过view函数在浏览器中查看该页面

通过查看网页源代码,发现所有数据包含在class为detail的div模块中。
接下来使用response.css或者response.xpath对数据进行提取
在scrapy shell中尝试如下:(这里只举一个例子,其他的可以自己类似尝试)

逐一确定其他目的提取元素的方式以后,可以开始进行正式的编码实现
三、编码实现
首先,我们在cmd中进到目的python目录中,创建一个scrapy项目
代码如下:

而后进入到创建的新scrapy项目目录下,新建spider文件

运行以后,scrapy genspider命令创建了文件fiction/spiders/fictions.py,并且创建了相应的spider类
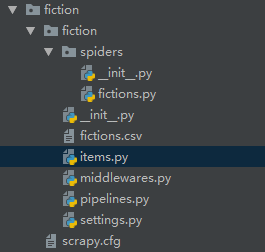
总体文件项如图:(其中,fictions.csv是后面进行爬虫的时候生成的)
接下来我们可以对“框架”按照我们前面的需求进行改写
①首先改写Item项目
在fiction/items.py中修改代码如下
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class FictionItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field() bookname = scrapy.Field()
statement = scrapy.Field()
author = scrapy.Field()
simple_content = scrapy.Field() pass
②实现页面解析函数
修改fiction/spiders/fictions.py代码如下(具体分析前面已经讨论,注释见详细代码)
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from ..items import FictionItem class FictionsSpider(scrapy.Spider):
name = 'fictions'
allowed_domains = ['quanshuwang.com']
start_urls = ['http://www.quanshuwang.com/list/8_1.html'] # 书籍列表的页面解析函数
def parse(self,response):
# 提取书籍列表页面每一本书的链接
pattern = 'http://www.quanshuwang.com/book_'
le = LinkExtractor(restrict_xpaths='//*[@class="seeWell cf"]',allow=pattern)
for link in le.extract_links(response):
yield scrapy.Request(link.url,callback=self.parse_book) # 提取下一页链接
le = LinkExtractor(restrict_xpaths='//*[@id="pagelink"]/a[@class="next"]')
links = le.extract_links(response)
if links:
next_url = links[0].url
yield scrapy.Request(next_url,callback=self.parse) pass # 书籍界面的解析函数
def parse_book(self, response):
book=FictionItem()
sel = response.css('div.detail')
book['bookname']=sel.xpath('./div[1]/h1/text()').extract_first()
book['statement']=sel.xpath('//*[@id="container"]/div[2]/section/div/div[4]/div[1]/dl[1]/dd/text()').extract_first()
book['author']=sel.xpath('//*[@id="container"]/div[2]/section/div/div[4]/div[1]/dl[2]/dd/text()').extract_first()
book['simple_content']=sel.xpath('string(//*[@id="waa"])').extract() yield book
③设置参数防止存储数据乱码
在setting.py中加上这个代码
FEED_EXPORT_ENCODING = 'utf-8'
④命令行中调用(要进入到/fiction/fiction中(与setting.py同级目录)才能调用)
在cmd输入代码如下
scrapy crawl books -o fiction.csv
就可以调用我们写的爬虫程序进行数据爬取啦!!!
最后贴个爬下来的数据的图

爬虫入门(四)——Scrapy框架入门:使用Scrapy框架爬取全书网小说数据的更多相关文章
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- 使用scrapy框架爬取全书网书籍信息。
爬取的内容:书籍名称,作者名称,书籍简介,全书网5041页,写入mysql数据库和.txt文件 1,创建scrapy项目 scrapy startproject numberone 2,创建爬虫主程序 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫(5)爬取当当网图书畅销榜
本次将会使用Scrapy来爬取当当网的图书畅销榜,其网页截图如下: 我们的爬虫将会把每本书的排名,书名,作者,出版社,价格以及评论数爬取出来,并保存为csv格式的文件.项目的具体创建就不再多讲 ...
- Python爬虫入门——使用requests爬取python岗位招聘数据
爬虫目的 使用requests库和BeautifulSoup4库来爬取拉勾网Python相关岗位数据 爬虫工具 使用Requests库发送http请求,然后用BeautifulSoup库解析HTML文 ...
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- 如何用python爬虫从爬取一章小说到爬取全站小说
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取http ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
随机推荐
- <转载>Vim的寄存器(复制黏贴要用)
https://blog.csdn.net/hk2291976/article/details/42196559 消除高亮 :noh
- spring ref &history&design philosophy
Spring Framework Overview Spring是开发java application的通用框架,分为多个模块(modules),核心是core container,包括configu ...
- mysql 语法积累
1.把一个表中的某一列赋值到另一个表中的某一列 update sfa_token,sfa_member set sfa_token.mainid = sfa_member.mainid where s ...
- jquery项目中一些常用方法
1.获取url中的参数 function getUrlParam(name) { var reg = new RegExp("(^|&)" + name + &quo ...
- spark streaming中维护kafka偏移量到外部介质
spark streaming中维护kafka偏移量到外部介质 以kafka偏移量维护到redis为例. redis存储格式 使用的数据结构为string,其中key为topic:partition, ...
- History of program
第一阶段:1950与1960年代 1.三个现代编程语言: (1)Fortran (1955),名称取自"FORmula TRANslator"(公式翻译器),由约翰·巴科斯等人所发 ...
- CSS Sprite雪碧图
为了减少http请求数量,加速网页内容显示,很多网站的导航栏图标.登录框图片等,使用的并不是<image>标签,而是CSS Sprite雪碧图. 两个小例子: 淘宝首页的侧栏图 代码 &l ...
- H5混合开发问题总结
1.This application is modifying the autolayout engine from a background thread, which can lead to en ...
- Ubuntu 16.04下安装搜狗输入法
在确保更新了国内镜像源的前提下: 安装sogou输入法步骤 一.安装fcitx键盘输入法系统(系统已安装的可忽略此步骤) 1.添加以下源 sudo add-apt-repository ppa:fci ...
- SUSE12Sp3-MongoDB安装
1.解压 sudo mkdir /usr/local/mongodb # 创建mongodb目录 将mongodb-linux-x86_64-suse12-4.0.6.tgz复制到/usr/local ...