[Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一、介绍
本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息。
给定关键字:数字;融合;电视
抓取信息内如下:
1、资讯标题
2、资讯链接
3、资讯时间
4、资讯来源
二、网站信息
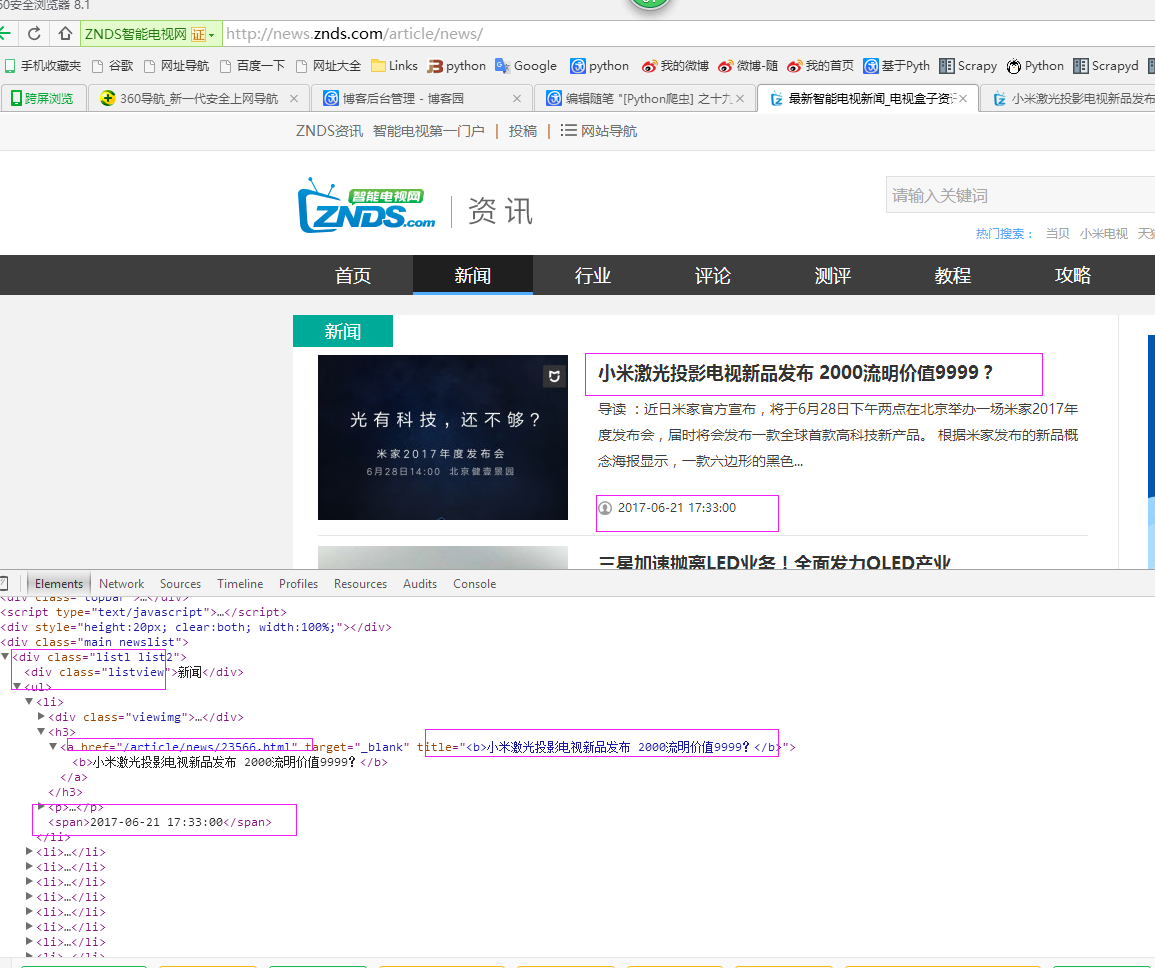
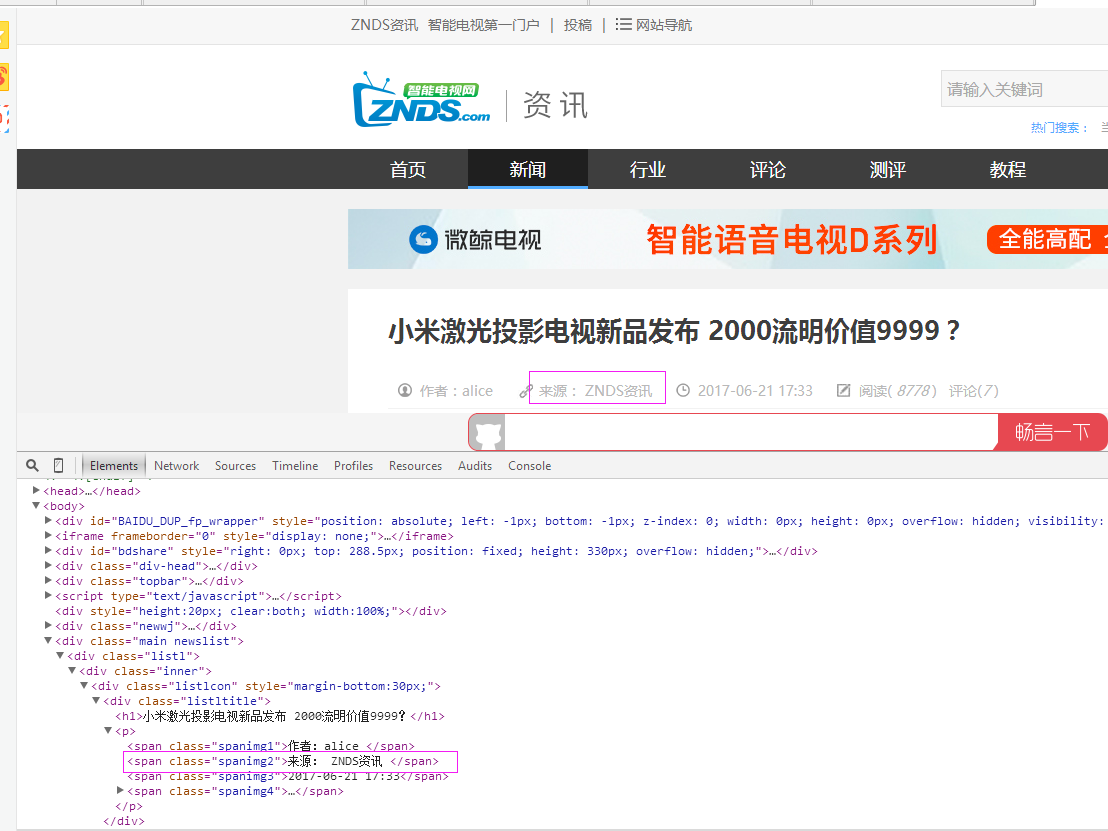
三、数据抓取
针对上面的网站信息,来进行抓取
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="listl list2"]').find('ul').find('li')
2、抓取标题
抓取代码:title = element('h3').find('a').attr('title').encode('utf8')
3、抓取链接
抓取代码:url = 'http://news.znds.com' + element('h3').find('a').attr('href')
4、抓取日期
抓取代码:date = element('span').text().encode('utf8')
5、抓取来源
抓取代码:strSource = dochtml('span[class="spanimg2"]').text().encode('utf8').strip()
四、完整代码
# coding=utf-8
import os
import re
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
import time
import datetime from pyquery import PyQuery as pq
import LogFile
import mongoDB class zndsSpider(object):
def __init__(self,driver,log,keyword_list,websearch_url,valid,filter):
''' :param driver: 驱动
:param log: 日志
:param keyword_list: 关键字列表
:param websearch_url: 搜索网址
:param valid: 采集参数 0:采集当天;1:采集昨天
:param filter: 过滤项,下面这些内容如果出现在资讯标题中,那么这些内容不要,过滤掉
'''
self.log = log
self.driver = driver
self.webSearchUrl_list = websearch_url.split(';')
self.keyword_list = keyword_list
self.db = mongoDB.mongoDbBase()
self.valid = valid
self.range =3+valid * 2 self.start_urls = []
# 过滤项
self.filter = filter
for url in self.webSearchUrl_list:
self.start_urls.append(url) def Comapre_to_days(self,leftdate, rightdate):
'''
比较连个字符串日期,左边日期大于右边日期多少天
:param leftdate: 格式:2017-04-15
:param rightdate: 格式:2017-04-15
:return: 天数
'''
l_time = time.mktime(time.strptime(leftdate, '%Y-%m-%d'))
r_time = time.mktime(time.strptime(rightdate, '%Y-%m-%d'))
result = int(l_time - r_time) / 86400
return result def date_isValid(self, strDateText):
'''
判断日期时间字符串是否合法:如果给定时间大于当前时间是合法,或者说当前时间给定的范围内
:param strDateText: '2017-06-20 10:22 '
:return: True:合法;False:不合法
'''
currentDate = time.strftime('%Y-%m-%d')
datePattern = re.compile(r'\d{4}-\d{1,2}-\d{1,2}')
strDate = re.findall(datePattern, strDateText)
if len(strDate) == 1:
if self.valid == 0 and self.Comapre_to_days(currentDate, strDate[0]) == 0:
return True, currentDate
elif self.valid == 1 and self.Comapre_to_days(currentDate, strDate[0]) == 1:
return True, str(datetime.datetime.now() - datetime.timedelta(days=1))[0:10]
elif self.valid == 2 and self.Comapre_to_days(currentDate, strDate[0]) == 2:
return True, str(datetime.datetime.now() - datetime.timedelta(days=2))[0:10]
return False, '' def log_print(self, msg):
'''
# 日志函数
# :param msg: 日志信息
# :return:
# '''
print '%s: %s' % (time.strftime('%Y-%m-%d %H-%M-%S'), msg) def scrapy_date(self):
try:
strsplit = '------------------------------------------------------------------------------------'
for link in self.start_urls:
try:
self.driver.get(link)
except TimeoutException:
self.log.WriteLog('time out after %d seconds when loading page' % 10)
self.driver.execute_script('window.stop()')
continue
move_element = self.driver.find_element_by_xpath("//div[@class='button-footer']/span")
for i in xrange(self.range):
move_element.click()
time.sleep(0.2)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
infoList = [] self.log.WriteLog(strsplit)
self.log_print(strsplit)
Elements = doc('div[class="hotbox "]')
for element in Elements.items():
date = element('span').text().encode('utf8') flag, strDate = self.date_isValid(date)
if flag:
title = element('h3').find('a').text().encode('utf8')
if title.find(self.filter)>-1:
continue
for keyword in self.keyword_list:
if title.find(keyword) > -1:
url = 'http://news.znds.com' + element('h3').find('a').attr('href')
dictM = {'title': title, 'date': strDate,
'url': url, 'keyword': keyword, 'introduction': title, 'source': ''}
infoList.append(dictM)
break
if len(infoList) > 0:
for item in infoList:
item['sourceType'] = 1
url = item['url']
try:
self.driver.get(url)
except TimeoutException:
self.log.WriteLog('time out after %d seconds when loading page' % 10)
self.driver.execute_script('window.stop()')
continue
htext = self.driver.execute_script("return document.documentElement.outerHTML")
dochtml = pq(htext)
strSource = dochtml('span[class="spanimg2"]').text().encode('utf8').strip()
item['source'] = strSource
self.log.WriteLog('title:%s' % item['title'])
self.log.WriteLog('url:%s' % item['url'])
self.log.WriteLog('date:%s' % item['date'])
self.log.WriteLog('source:%s' % item['source'])
self.log.WriteLog('kword:%s' % item['keyword'])
self.log.WriteLog(strsplit) self.log_print('title:%s' % item['title'])
self.log_print('url:%s' % item['url'])
self.log_print('date:%s' % item['date'])
self.log_print('source:%s' % item['source'])
self.log_print('kword:%s' % item['keyword'])
self.log_print(strsplit)
self.db.SaveInformations(infoList)
except Exception, e:
self.log.WriteLog('zndsSpider:' + e.message)
finally:
pass # obj = zndsSpider()
# obj.scrapy_date()
[Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据的更多相关文章
- [Python爬虫] 之十七:Selenium +phantomjs 利用 pyquery抓取梅花网数据
一.介绍 本例子用Selenium +phantomjs爬取梅花网(http://www.meihua.info/a/list/today)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字: ...
- [Python爬虫] 之二十二:Selenium +phantomjs 利用 pyquery抓取界面网站数据
一.介绍 本例子用Selenium +phantomjs爬取界面(https://a.jiemian.com/index.php?m=search&a=index&type=news& ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之十六:Selenium +phantomjs 利用 pyquery抓取一点咨询数据
本篇主要是利用 pyquery来定位抓取数据,而不用xpath,通过和xpath比较,pyquery效率要高. 主要代码: # coding=utf-8 import os import re fro ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
随机推荐
- python-自定义分页组件
使用方法 """ 自定义分页组件的使用方法: pager_obj = Pagination(request.GET.get('page',1),len(HOST_LIST ...
- (十二)进一步掌握STVD/COSMIC
如何分配变量到指定的地址 举例:unsigned char temp_A@0x00; //定义无符号变量temp_A,强制其地址为0x00unsigned char temp_B@0x100; //定 ...
- iOS设计模式 —— KV0
刨根问底KVO KVO 全称 Key-Value Observing.中文叫键值观察.KVO其实是一种观察者模式,观察者在键值改变时会得到通知,利用它可以很容易实现视图组件和数据模型的分离,当数据模型 ...
- 2.kafka单节点broker的安装与启动
下载kafka,http://kafka.apache.org/downloads kafka下面的文件结构如下: 进入bin目录,启动kafka之前要先启动zookeeper ./zookeeper ...
- [ Python - 6 ] 正则表达式实现计算器功能
要求:禁止使用eval函数.参考网上代码如下: #!_*_coding:utf-8_*_ """用户输入计算表达式,显示计算结果""" im ...
- C# 正则表达式判断IP,URL等及其解释
C# 正则表达式判断IP,URL等及其解释 判断IP格式方法: public static bool ValidateIPAddress(string ipAddress) { Regex valid ...
- C# for Hbase 实现详解
一共两种方式访问 通过Thrift访问 目前hbase src.tar.gz压缩包中包含thrift he thrift2; 根据官方文档,thrift可能被抛弃,但是网上基本上都是介绍thrift的 ...
- docker从零开始 存储(四)tmpfs挂载
使用tmpfs挂载 volume和bind mounts允许您在主机和容器之间共享文件,以便即使在容器停止后也可以保留数据. 如果你在Linux上运行Docker,你有第三个选择:tmpfs moun ...
- [BZOJ2730][HNOI2012]矿场搭建 点双 割点
2730: [HNOI2012]矿场搭建 Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 2852 Solved: 1344[Submit][Stat ...
- 使用httpclient异步调用WebAPI接口
最近的工作需要使用Bot Framework调用原有的WebAPI查询数据,查找了一些方法,大部分都是使用HttpClient调用的,现时贴出代码供参考 using System; using Sys ...