新闻网大数据实时分析可视化系统项目——5、Hadoop2.X HA架构与部署
1.HDFS-HA架构原理介绍
hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解决思路和方案,示意图如下:
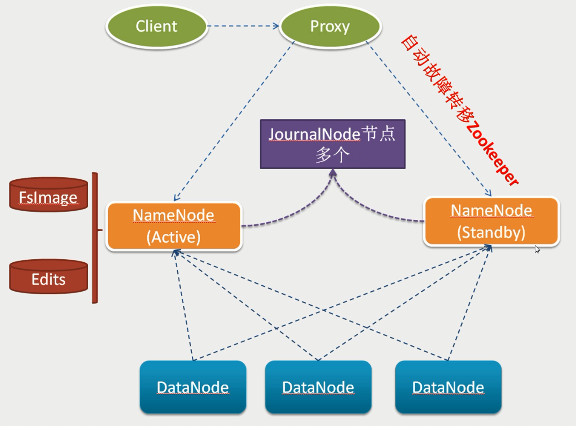
1)基本原理就是用2N+1台 JN 存储EditLog,每次写数据操作有大多数(>=N+1)返回成功时即认为该次写成功,数据不会丢失了。当然这个算法所能容忍的是最多有N台机器挂掉,如果多于N台挂掉,这个算法就失效了。这个原理是基于Paxos算法
2)在HA架构里面SecondaryNameNode这个冷备角色已经不存在了,为了保持standby NN时时的与主Active NN的元数据保持一致,他们之间交互通过一系列守护的轻量级进程JournalNode
3)任何修改操作在 Active NN上执行时,JN进程同时也会记录修改log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取 JN 里面的修改log,然后同步到自己的的目录镜像树里面,如下图:
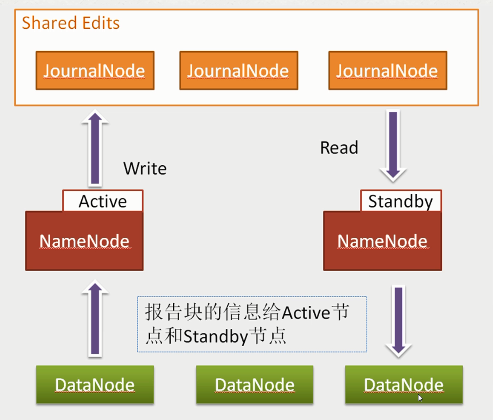
当发生故障时,Active的 NN 挂掉后,Standby NN 会在它成为Active NN 前,读取所有的JN里面的修改日志,这样就能高可靠的保证与挂掉的NN的目录镜像树一致,然后无缝的接替它的职责,维护来自客户端请求,从而达到一个高可用的目的。
2.HDFS-HA 详细配置
1)修改hdfs-site.xml配置文件
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>bigdata-pro01.kfk.com:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>bigdata-pro02.kfk.com:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>bigdata-pro01.kfk.com:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>bigdata-pro02.kfk.com:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://bigdata-pro01.kfk.com:8485;bigdata-pro02.kfk.com:8485;bigdata-pro03.kfk.com:8485/ns</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/kfk/.ssh/id_rsa</value>
</property>
</configuration>
2)修改core-site.xml配置文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<property>
<name>hadoop.http.staticuser.user</name>
<value>kfk</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.5.0/data/tmp</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,
bigdata-pro03.kfk.com:2181</value>
</property>
</configuration>
3)将修改的配置分发到其他节点
scp hdfs-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp hdfs-site.xml bigdata-pro03.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp core-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp core-site.xml bigdata-pro03.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
3.HDFS-HA 服务启动及自动故障转移测试
1)启动所有节点上面的Zookeeper进程
zkServer.sh start
2)启动所有节点上面的journalnode进程
sbin/hadoop-daemon.sh start journalnode
3)在[nn1]上,对namenode进行格式化,并启动
#namenode 格式化
bin/hdfs namenode -format
#格式化高可用
bin/hdfs zkfc -formatZK
#启动namenode
bin/hdfs namenode
4)在[nn2]上,同步nn1元数据信息
bin/hdfs namenode -bootstrapStandby
5)nn2同步完数据后,在nn1上,按下ctrl+c来结束namenode进程。然后关闭所有节点上面的journalnode进程
sbin/hadoop-daemon.sh stop journalnode
6)一键启动hdfs所有相关进程
sbin/start-dfs.sh
hdfs启动之后,kill其中Active状态的namenode,检查另外一个NameNode是否会自动切换为Active状态。同时通过命令上传文件至hdfs,检查hdfs是否可用。
4.YARN-HA架构原理及介绍

ResourceManager HA 由一对Active,Standby结点构成,通过RMStateStore存储内部数据和主要应用的数据及标记。目前支持的可替代的RMStateStore实现有:基于内存的MemoryRMStateStore,基于文件系统的FileSystemRMStateStore,及基于zookeeper的ZKRMStateStore。 ResourceManager HA的架构模式同NameNode HA的架构模式基本一致,数据共享由RMStateStore,而ZKFC成为 ResourceManager进程的一个服务,非独立存在。
5.YARN-HA详细配置
1)修改mapred-site.xml配置文件
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
2)修改yarn-site.xml配置文件
<configuration>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rs</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>bigdata-pro01.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>bigdata-pro02.kfk.com</value>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,
bigdata-pro03.kfk.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,
bigdata-pro03.kfk.com:2181</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3)将修改的配置分发到其他节点
scp yarn-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp yarn-site.xml bigdata-pro03.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp mapred-site.xml bigdata-pro02.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
scp mapred-site.xml bigdata-pro03.kfk.com:/opt/modules/hadoop-2.5.0/etc/hadoop/
6.YARN-HA服务启动及自动故障转移测试
1)在rm1节点上启动yarn服务
sbin/start-yarn.sh
2)在rm2节点上启动ResourceManager服务
sbin/yarn-daemon.sh start resourcemanager
3)查看yarn的web界面
http://bigdata-pro01.kfk.com:8088
http://bigdata-pro02.kfk.com:8088
4)查看ResourceManager主备节点状态
#bigdata-pro01.kfk.com节点上执行
bin/yarn rmadmin -getServiceState rm1
#bigdata-pro02.kfk.com节点上执行
bin/yarn rmadmin -getServiceState rm2
5)hadoop集群测试WordCount运行
bin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/kfk/data/wc.input
新闻网大数据实时分析可视化系统项目——5、Hadoop2.X HA架构与部署的更多相关文章
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
随机推荐
- TCP 连接建立分析
tcp 三次握手与四次挥手 tcp 报文结构 tcp 是全双工的,即 client 向 server 发送信息的同时,server 也可以向 client 发送信息. 在同主机的两个 session ...
- map的使用-Hdu 2648
Shopping Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total S ...
- 基于Tesseract实现图片文字识别
一.简介 Tesseract是一个开源的文本识别[OCR]引擎,可通过Apache 2.0许可获得.它可以直接使用,或者使用API从图像中提取打印的文本,支持多种语言.该软件包包含一个ORC引擎[l ...
- 2020年python学习进阶方向
相信很多友人在学习python过程都会遇到很多 虽然python入门很容易 但是难免会遇到瓶颈 遇到问题没人交流 很难提升 对此 给你们简单指点学习方向 1.认识python linux基本 ...
- 2_2 3n+1问题
猜想:对于任意大于1的自然数n,若n为奇数,则将n变为3n+1,否则变为n的一半.经过若干次这样的变换,一定会使n变为1.例如:3→10→5→16→8→4→2→1. 输入n,输出变换的次数.n< ...
- CAN总线学习笔记
1.CAN总线信息包的格式 问题: 1.CAN总线的初始化要初始化哪些东西? 2.处理器如何与CAN总线之间进行连接? 硬件连接 关于CC2底盘CAN通信的协议格式 备注: 设备地址为01 功能码
- jmh 微基准测试
选择依据:对某段代码的性能测试. 1.运行方法 mvn clean install java -jar target/benchmarks.jar JMHSample_02 -f 1 2.maven ...
- Springboot学习:SpringMVC自动配置
Spring MVC auto-configuration Spring Boot 自动配置好了SpringMVC 以下是SpringBoot对SpringMVC的默认配置:==(WebMvcAuto ...
- CN109241772A发票区块链记录方法、装置、区块链网关服务器和介质(腾讯)
学习笔记-2 CN109241772A发票区块链记录方法.装置.区块链网关服务器和介质(腾讯) 解决什么问题? 让发票信息记录到区块链的情况下减少发票信息泄露 链上有什么数据? 发行发票事件信息(发票 ...
- C++11特性中基于范围的for循环
本文摘录柳神笔记: 除了像C语⾔的for语句 for (i = 0; i < arr.size(); i++) 这样,C++11标准还为C++添加了⼀种新的 for 循环⽅ 式,叫做基于范围 ...