【python】使用爬虫爬取动漫之家漫画全部更新信息
本篇仅在于交流学习
网站名称为:
https://manhua.dmzj.com/
1.首先将相应的库导入:
import requests
from lxml import etree
2.确定漫画更新页面上限:

 第一页
第一页
 第二页
第二页
可以确定页面转换是通过修改数字改变网页的
3.使用for循环遍历页面:
for page in range(1,11):
url = 'https://manhua.dmzj.com/update_%s.shtml' % (page * 1)
print(url)
得到漫画更新全网页链接
4.截取网站信息进行分析:
heads = {}
heads['User-Agent'] = '用自己的网页头部'
html = requests.get(url=url, headers=heads).text
list = etree.HTML(html)
5.截取信息:
分析网页内容:
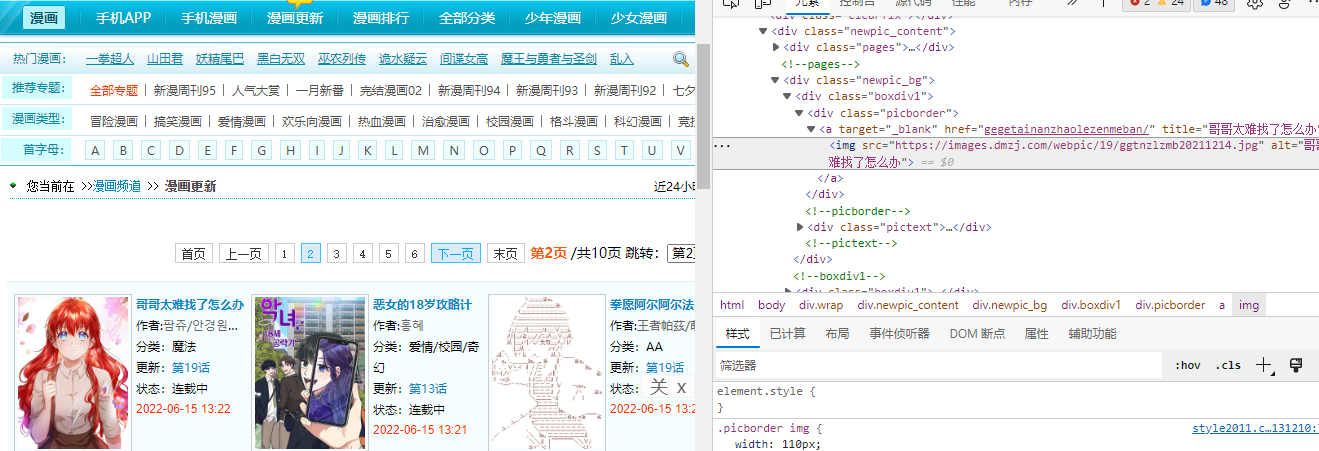
l = list.xpath("//div[@class='boxdiv1']")
for info in l:
title = info.xpath('div/ul/li/a/@title')[0] # 作品名
doc = info.xpath('div/ul/li/text()')[1] # '作者:'
name = info.xpath('div/ul/li/span/text()')[0] # 作者名·-
type = info.xpath('div/ul/li/text()')[2] # 类型
link = info.xpath('div/ul/li/a/@href')[0] # 作品链接
link = 'https://manhua.dmzj.com/' + link
newlink = info.xpath('div/ul/li/a/@href')[1] # 最新作品链接
newlink = 'https://manhua.dmzj.com/' + newlink
buff = info.xpath('div/ul/li/text()')[5] # 作品状态
print(title + " " + doc + name + " " + type + " " + link + " " + buff + " " + newlink + " ")x
效果:

6.完整代码:
import requests
from lxml import etree for page in range(1,11):
url = 'https://manhua.dmzj.com/update_%s.shtml' % (page * 1)
print(url)
heads = {}
heads['User-Agent'] = '用自己的头部'
html = requests.get(url=url, headers=heads).text
list = etree.HTML(html)
l = list.xpath("//div[@class='boxdiv1']")
for info in l:
title = info.xpath('div/ul/li/a/@title')[0] # 作品名 doc = info.xpath('div/ul/li/text()')[1] # '作者:' name = info.xpath('div/ul/li/span/text()')[0] # 作者名·- type = info.xpath('div/ul/li/text()')[2] # 类型 link = info.xpath('div/ul/li/a/@href')[0] # 作品链接
link = 'https://manhua.dmzj.com/' + link newlink = info.xpath('div/ul/li/a/@href')[1] # 最新作品链接
newlink = 'https://manhua.dmzj.com/' + newlink buff = info.xpath('div/ul/li/text()')[5] # 作品状态 print(title + " " + doc + name + " " + type + " " + link + " " + buff + " " + newlink + " ")
【python】使用爬虫爬取动漫之家漫画全部更新信息的更多相关文章
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- 通过爬虫爬取四川省公共资源交易平台上最近的招标信息 --- URLConnection
通过爬虫爬取公共资源交易平台(四川省)最近的招标信息 一:引入JSON的相关的依赖 <dependency> <groupId>net.sf.json-lib< ...
- Python多线程爬虫爬取电影天堂资源
最近花些时间学习了一下Python,并写了一个多线程的爬虫程序来获取电影天堂上资源的迅雷下载地址,代码已经上传到GitHub上了,需要的同学可以自行下载.刚开始学习python希望可以获得宝贵的意见. ...
- Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- python制作爬虫爬取京东商品评论教程
作者:蓝鲸 类型:转载 本文是继前2篇Python爬虫系列文章的后续篇,给大家介绍的是如何使用Python爬取京东商品评论信息的方法,并根据数据绘制成各种统计图表,非常的细致,有需要的小伙伴可以参考下 ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
- python 小爬虫爬取博客文章初体验
最近学习 python 走火入魔,趁着热情继续初级体验一下下爬虫,以前用 java也写过,这里还是最初级的爬取html,都没有用html解析器,正则等...而且一直在循环效率肯定### 很低下 imp ...
- 【Python】Python简易爬虫爬取百度贴吧图片
通过python 来实现这样一个简单的爬虫功能,把我们想要的图片爬取到本地.(Python版本为3.6.0) 一.获取整个页面数据 def getHtml(url): page=urllib.requ ...
- python简单爬虫爬取百度百科python词条网页
目标分析:目标:百度百科python词条相关词条网页 - 标题和简介 入口页:https://baike.baidu.com/item/Python/407313 URL格式: - 词条页面URL:/ ...
随机推荐
- clion环境配置
如果是学生:直接使用学校的邮箱,可以直接注册使用 环境配置:下载:https://sourceforge.net/projects/mingw-w64/
- webpack之性能优化(webpack4)
在讲解性能优化的方案之前,我们需要了解一下webpack的整个工作流程, 方案一:减少模块解析 也就是省略了构建chunk依赖模块的这几个步骤 如果没有loader对该模块进行处理,该模块的源码就是最 ...
- beta冲刺:汇总博客
这个作业属于哪个课程 <班级的链接> 这个作业要求在哪里 <作业要求的链接> 这个作业的目标 汇总博客 作业正文 .... 其他参考文献 ... 博客 beta冲刺(1/5) ...
- 【Mybatis-Plus】使用updateById()、update()将字段更新为null或者空
参考 https://blog.csdn.net/weixin_41544866/article/details/119738605
- python内置函数range()—对象创建函数
range()函数 介绍 range()函数实际上表示一个不可变的数字序列类型,通常用于在for循环中指定特定的次数. range()的格式: range(stop) range(start, sto ...
- [极客大挑战 2019]BuyFlag 1
好吧,又是一道违背我思想的题目,哦不哦不不对,是本人操作太傻了 首先进入主页面 没有发现什么奇怪的东西,查看源代码,搜索.php 可以看到有一个pay.php,访问查看 给我们了一些提示 FLAG N ...
- 如何基于 React Native 快速实现一个视频通话应用
今天,我们将会一起开发一个包含 RTE (实时互动)场景的 Flutter 应用. 项目介绍 靠自研开发包含实时互动功能的应用非常繁琐,你要解决维护服务器.负载均衡等难题,同时还要保证稳定的低延迟. ...
- 基于.Net开发的、支持多平台、多语言餐厅点餐系统
今天给大家推荐一套支持多平台.多语言版本的订单系统,适合餐厅.酒店等场景. 项目简介 这是基于.Net Framework开发的,支持手机.平板.PC等平台.多语言版本开源的点餐系统,非常适合餐厅.便 ...
- Hadoop 安装及目录结构
一.准备工作 [1]创建用户:useradd 用户名[2]配置创建的用户具有 root权限,修改 /etc/sudoers 文件,找到下面一行,在root下面添加一行,如下所示:(注意:需要先给sud ...
- 可靠消息最终一致性【本地消息表、RocketMQ 事务消息方案】
更多内容,前往IT-BLOG 一.可靠消息最终一致性事务概述 可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能够接收消息并处理事务成功,此方案强调 ...