四十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。带有倒排索引的文件我们称为倒排索引文件,简称倒排文件(inverted file)。
倒排索引原理
就是将一句话进行分词并记录分词所存在的文章,当用户搜索词时可以直接查找到当前词所存在的文章
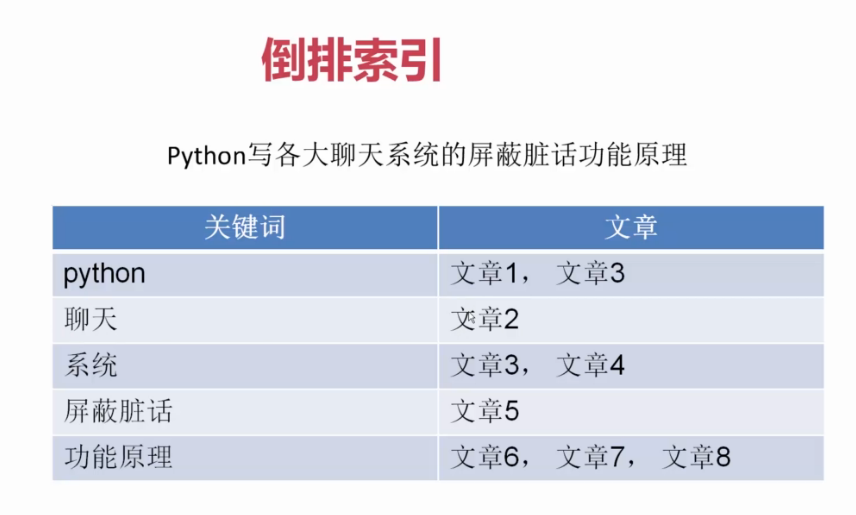
倒排索引分词权重记录(词瓶)

分词权重记录,是通过(TF-IDF)来实现的,详情https://baike.so.com/doc/433640-459181.html
倒排索引待解决的问题
这些问题elasticsearch(搜索引擎)已经解决

四十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)倒排索引的更多相关文章
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页
第三百七十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索结果分页 逻辑处理函数 计算搜索耗时 在开始搜索前:start_time ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 五十 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门搜索
第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门 我的搜素简单实现原理我们可以用js来实现,首先用js获取到 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- 剑指Offer——替换空格
题目描述: 请实现一个函数,将一个字符串中的空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. 分析: 如果从前往后替换空格,那 ...
- python2 一些错误处理
python2各种问题 pip安装django出错:python2 -m pip install django 编码问题:Unicode Decode Error ascii codec can't ...
- Java 连接池的工作原理(转)
原文:Java 连接池的工作原理 什么是连接? 连接,是我们的编程语言与数据库交互的一种方式.我们经常会听到这么一句话“数据库连接很昂贵“. 有人接受这种说法,却不知道它的真正含义.因此,下面我将解释 ...
- Drawable.Callback
一.介绍 public abstract void invalidateDrawable (Drawable who) Called when the drawable needs to be re ...
- R中的data.table 快速上手入门
data.table包提供了一个非常简洁的通用格式:DT[i,j,by]. 可以理解为:对于数据集DT,选取子集行i,通过by分组计算j. 对比与dplyr等包,data.table的运行速度更快. ...
- input和raw_input的区别
input会假设用户输入的是合法的Python表达式raw_input会把所有的输入当作原始数据,然后将其放入字符串中. 在最新的版本之中,input可以直接使用,替代了raw_input. 在2.7 ...
- Java集合(5):HashSet
存入Set的每个元素必须是惟一的,因为Set不保存重复元素.加入Set的元素必须定义equals()方法以确保对象的唯一性.Set不保证维护元素的次序.Set与Collection有完全一样的接口. ...
- MapReduce:输入是两个文件,file1代表工厂表,包含工厂名列和地址编号列;file2代表地址表,包含地址名列和地址编号列。要求从输入数据中找出工厂名和地址名的对应关系,输出"工厂名----地址名"表
文件如下: file1: Beijing Red Star Shenzhen Thunder Guangzhou Honda Beijing Rising Guangzhou Development ...
- COS-7设备管理
操作系统(Operating System,简称OS)是管理和控制计算机硬件与软件资源的计算机程序,是直接运行在“裸机”上的最基本的系统软件,任何其他软件都必须在操作系统的支持下才能运行. 操作系 ...
- 简单介绍java Enumeration(转)
Enumeration接口 Enumeration接口本身不是一个数据结构.但是,对其他数据结构非常重要. Enumeration接口定义了从一个数据结构得到连续数据的手段.例如,Enumeratio ...