Spark学习进度-实战测试
spark-shell 交互式编程
题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在 spark-shell 中通过编程来计算以下内容:
(1)该系总共有多少学生;

(2)该系共开设来多少门课程;
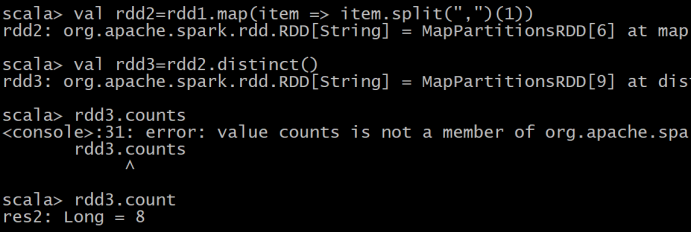
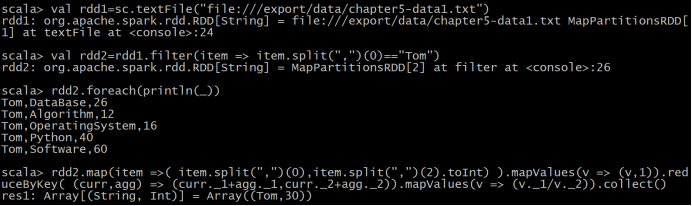
(3)Tom 同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;

共265行
(5)该系 DataBase 课程共有多少人选修;

(6)各门课程的平均分是多少;

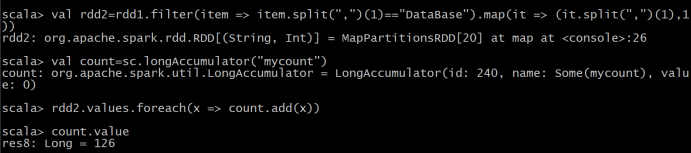
(7)使用累加器计算共有多少人选了 DataBase 这门课。
独立应用
实现数据去重,连接,排序
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其
中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
代码:
@Test
def test(): Unit ={
val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_union")
val sc=new SparkContext(conf)
val ra=sc.textFile("dataset/a.txt")
val rb=sc.textFile("dataset/b.txt")
val rc=ra.union(rb)
.distinct()
.map(item => (item.split(" ")(0),item.split(" ")(1)))
.sortBy(item =>(item._1,item._2))
.collect()
val file = "dataset/c.txt"
val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))
for(x<- rc)
{
println(x)
writer.write(x+"\n")
}
writer.close()
}
实现求平均值
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生
名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到
一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm 成绩:
小明 92
小红 87
小新 82
小丽 90
Database 成绩:
小明 95
小红 81
小新 89
小丽 85
Python 成绩:
小明 82
小红 83
小新 94
小丽 91
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
代码:
@Test
def test2(): Unit ={
val conf=new SparkConf().setMaster("local[6]").setAppName("xlf_avg")
val sc=new SparkContext(conf)
val ra=sc.textFile("dataset/Algorithm.txt")
val rb=sc.textFile("dataset/Database.txt")
val rc=sc.textFile("dataset/Python.txt")
val out=ra.union(rb)
.union(rc)
.map(item => (item.split(" ")(0),item.split(" ")(1).toDouble))
.mapValues(v => (v,1))
.reduceByKey( (x,y) =>(x._1+y._1,x._2+y._2) )
.mapValues(v => (v._1/v._2).formatted("%.2f") )
.collect()
val file = "dataset/out.txt"
val writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)))
for(x<- out)
{
println(x)
writer.write(x+"\n")
}
writer.close() }
Spark学习进度-实战测试的更多相关文章
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-Transformation算子
Transformation算子 intersection 交集 /* 交集 */ @Test def intersection(): Unit ={ val rdd1=sc.parallelize( ...
- Spark学习进度7-综合案例
综合案例 文件排序 解法: 1.读取数据 2.数据清洗,变换数据格式 3.从新分区成一个分区 4.按照key排序,返还带有位次的元组 5.输出 @Test def filesort(): Unit = ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- Spark学习入门(让人看了想吐的话题)
这是个老生常谈的话题,大家是不是看到这个文章标题就快吐了,本来想着手写一些有技术深度的东西,但是看到太多童鞋卡在入门的门槛上,所以还是打算总结一下入门经验.这种标题真的真的在哪里都可以看得到,度娘一搜 ...
- NGUI 学习笔记实战之二——商城数据绑定(Ndata)
上次笔记实现了游戏商城的UI界面,没有实现动态数据绑定,所以是远远不够的.今天采用NData来做一个商城. 如果你之前没看过,可以参考上一篇博客 NGUI 学习笔记实战——制作商城UI界面 ht ...
随机推荐
- 第15.17节 PyQt(Python+Qt)入门学习:PyQt图形界面应用程序的事件捕获方法大全及对比分析
老猿Python博文目录 老猿Python博客地址 按照老猿规划的章节安排,信号和槽之后应该介绍事件,但事件在前面的随笔<PyQt(Python+Qt)实现的GUI图形界面应用程序的事件捕获方法 ...
- buu学习记录(上)
前言:菜鸡误入buu,差点被打吐.不过学到了好多东西. 题目名称: (1)随便注 (2)高明的黑客 (3)CheckIn (4)Hack World (5)SSRF Me (6)piapiapia ( ...
- CTFHub Web题学习笔记(SQL注入题解writeup)
Web题下的SQL注入 1,整数型注入 使用burpsuite,?id=1%20and%201=1 id=1的数据依旧出现,证明存在整数型注入 常规做法,查看字段数,回显位置 ?id=1%20orde ...
- 在Linux中使用Dbeaver等GTK3界面的软件出现频繁闪烁的问题解决
问题复现 复现环境LinuxMint 19 Dbeaver: 7.3 输入法: ibus + ibus-table-wubi 如图,当光标移动到Sql Editor中会不停的闪-- 解决过程 先百度. ...
- 学习笔记:四边形不等式优化 DP
定义 & 等价形式 四边形不等式是定义在整数集上的二元函数 \(w(x, y)\). 定义:对于任意 \(a \le b \le c \le d\),满足交叉小于等于包含(即 \(w(a, c ...
- oracle 时间段查询
<select id="selectByRzrq" resultMap="BaseResultMap" parameterType="java. ...
- 解压版mysql+免破解版Navicat,好用!
解压版mysql安装流程 获取mysql压缩包 获取地址: 链接:https://pan.baidu.com/s/1HqdFDQn_6ccPM0gOftApIg 提取码:n19t 获取压缩包后可安装压 ...
- ThreadX——IPC应用之信号量
一.应用简介 在RTOS的应用开发中,信号量也是经常使用到的一种用于多任务之间信息同步.资源互斥访问的一种手段,常用于协调多个任务访问同一资源的场景.信号量又分为计数信号量和互斥信号量.计数信号量可以 ...
- 一个实现浏览器网页与本地程序之间进行双向调用的轻量级、强兼容、可扩展的插件开发平台—PluginOK中间件
通过PluginOK中间件插件平台(原名本网通WebRunLocal)可实现在网页中的JavaScript脚本无障碍访问本地电脑的硬件.调用本地系统的API及相关组件,同时可彻底解决ActiveX组件 ...
- Spring Boot 最简单的解决跨域问题
跨域问题(CORS) CORS全称Cross-Origin Resource Sharing,意为跨域资源共享.当一个资源去访问另一个不同域名或者同域名不同端口的资源时,就会发出跨域请求.如果此时另一 ...