scrapydweb的初步使用(管理分布式爬虫)
https://github.com/my8100/files/blob/master/scrapydweb/README_CN.md
一.安装配置
1、请先确保所有主机都已经安装和启动 Scrapyd,如果需要远程访问 Scrapyd,则需将 Scrapyd 配置文件中的 bind_address 修改为 bind_address = 0.0.0.0,然后重启 Scrapyd。
2、开发主机或任一台主机安装 ScrapydWeb: pip install scrapydweb
3、运行命令 scrapydweb -h,将在当前工作目录生成配置文件 scrapydweb_settings.py,可用于下文的自定义配置。
4、启用 HTTP 基本认证
ENABLE_AUTH = True
USERNAME = 'username'
PASSWORD = 'password'
- 添加 Scrapyd server,支持字符串和元组两种配置格式,支持添加认证信息和分组/标签:
SCRAPYD_SERVERS = [
#'127.0.0.1:6800',
# 'username:password@localhost:6801#group',
'106.12.112.139:6800',
]
报错情况:(在)
In order to automatically run LogParser at startup, you have to set up the SCRAPYD_LOGS_DIR option first.
Otherwise, set 'ENABLE_LOGPARSER = False' if you are not running any Scrapyd service on the current ScrapydWeb host.
Note that you can run the LogParser service separately via command 'logparser' as you like.
Check and update your settings in F:/scrapyweb/scrapydweb_settings_v8.py
如果出现这样的错误去配置文件中把
'ENABLE_LOGPARSER = True'改成False
6.通过运行命令 scrapydweb 启动 ScrapydWeb
二.页面管理
通过浏览器访问并登录 http://127.0.0.1:5000
Overview 页面自动输出所有 Scrapyd server 的运行状态
通过分组和过滤可以自由选择若干台 Scrapyd server,调用 Scrapyd 提供的所有 HTTP JSON API,实现一次操作,批量执行

三.部署项目
- 通过配置
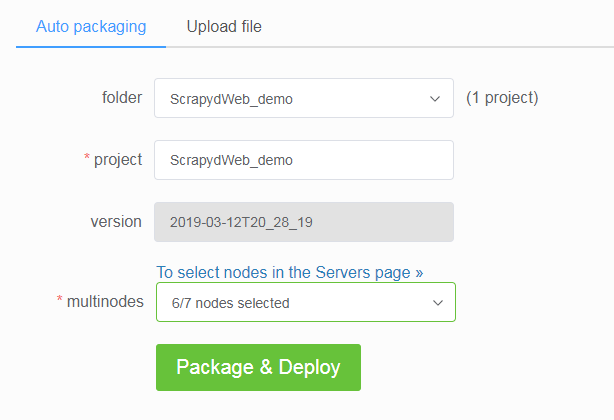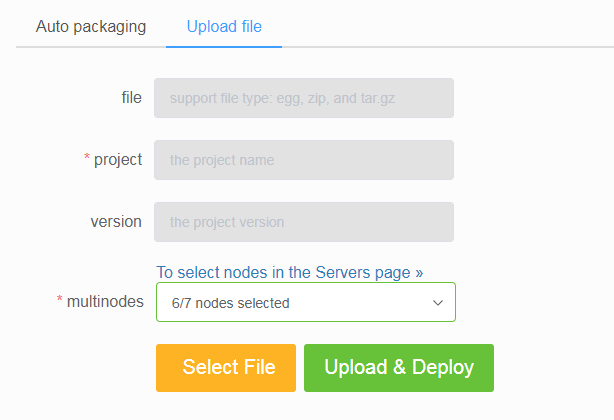
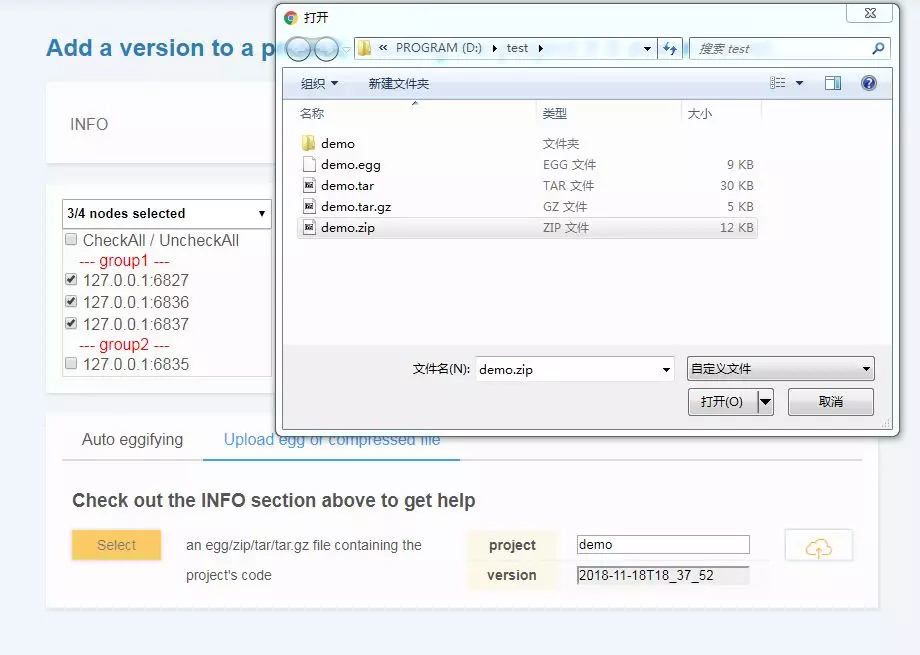
SCRAPY_PROJECTS_DIR指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,默认选定最新编辑的项目,选择项目后即可自动打包和部署指定项目。 - 如果 ScrapydWeb 运行在远程服务器上,除了通过当前开发主机上传常规的 egg 文件,也可以将整个项目文件夹添加到 zip/tar/tar.gz 压缩文件后直接上传即可,无需手动打包为 egg 文件。
- 支持一键部署项目到 Scrapyd server 集群。

四.运行爬虫
通过下拉框直接选择 project,version 和 spider
支持传入 Scrapy settings 和 spider arguments
同样支持指定若干台 Scrapyd server 运行爬虫

五.定时爬虫任务
- 支持查看爬虫任务的参数信息,追溯历史记录
- 支持暂停,恢复,触发,停止,编辑和删除任务等操

六.日志可视化
默认情况下,ScrapydWeb 将在后台定时自动读取和分析 Scrapy log 文件并生成 Stats 页面


七.邮件通知
基于后台定时读取和分析 Scrapy log 文件,ScrapydWeb 将在满足特定触发器时发送通知邮件,邮件正文包含当前运行任务的统计信息。
1、添加邮箱帐号:
SMTP_SERVER = 'smtp.qq.com'
SMTP_PORT = 465
SMTP_OVER_SSL = True
SMTP_CONNECTION_TIMEOUT = 10 FROM_ADDR = 'username@qq.com'
EMAIL_PASSWORD = 'password'
TO_ADDRS = ['username@qq.com']
2、设置邮件工作时间和基本触发器,以下示例代表:每隔1小时或某一任务完成时,并且当前时间是工作日的9点,12点和17点,ScrapydWeb 将会发送通知邮件。
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5]
EMAIL_WORKING_HOURS = [9, 12, 17]
ON_JOB_RUNNING_INTERVAL = 3600
ON_JOB_FINISHED = True
3、除了基本触发器,ScrapydWeb 还提供了多种触发器用于处理不同类型的 log,包括 'CRITICAL', 'ERROR', 'WARNING', 'REDIRECT', 'RETRY' 和 'IGNORE'等。
LOG_CRITICAL_THRESHOLD = 3
LOG_CRITICAL_TRIGGER_STOP = True
LOG_CRITICAL_TRIGGER_FORCESTOP = False
#...
LOG_IGNORE_TRIGGER_FORCESTOP = False
以上示例代表:当发现3条或3条以上的 critical 级别的 log 时,ScrapydWeb 自动停止当前任务,如果当前时间在邮件工作时间内,则同时发送通知邮件。
scrapydweb的初步使用(管理分布式爬虫)的更多相关文章
- gerapy的初步使用(管理分布式爬虫)
一.简介与安装 Gerapy 是一款分布式爬虫管理框架,支持 Python 3,基于 Scrapy.Scrapyd.Scrapyd-Client.Scrapy-Redis.Scrapyd-API.Sc ...
- gerapy+scrapyd组合管理分布式爬虫
Scrapyd是一款用于管理scrapy爬虫的部署和运行的服务,提供了HTTP JSON形式的API来完成爬虫调度涉及的各项指令.Scrapyd是一款开源软件,代码托管于Github上. 点击此链接h ...
- 第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理 1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字 ...
- 四十三 Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1.映射(mapping)介绍 映射:创建索引的时候,可以预先定义字段的类型以及相关属性elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项, ...
- Python分布式爬虫原理
转载 permike 原文 Python分布式爬虫原理 首先,我们先来看看,如果是人正常的行为,是如何获取网页内容的. (1)打开浏览器,输入URL,打开源网页 (2)选取我们想要的内容,包括标题,作 ...
- 基于Python,scrapy,redis的分布式爬虫实现框架
原文 http://www.xgezhang.com/python_scrapy_redis_crawler.html 爬虫技术,无论是在学术领域,还是在工程领域,都扮演者非常重要的角色.相比于其他 ...
- 纯手工打造简单分布式爬虫(Python)
前言 这次分享的文章是我<Python爬虫开发与项目实战>基础篇 第七章的内容,关于如何手工打造简单分布式爬虫 (如果大家对这本书感兴趣的话,可以看一下 试读样章),下面是文章的具体内容. ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- 跟繁琐的命令行说拜拜!Gerapy分布式爬虫管理框架来袭!
背景 用 Python 做过爬虫的小伙伴可能接触过 Scrapy,GitHub:https://github.com/scrapy/scrapy.Scrapy 的确是一个非常强大的爬虫框架,爬取效率高 ...
随机推荐
- Python-SSH批量登陆并执行命令
Python-SSH批量登陆并执行命令 #!/usr/bin/env python #-*- coding:utf-8 -*- import paramiko from time import cti ...
- bat连接映射盘
net use h: \\IP地址\目录 "密码" /user:"用户名"
- Tomcat源码解析-启动过程分析之主干流程
Tomcat启动入口就在脚本startup.sh中,具体脚本可以看tomcat的源码,这个启动脚本主要用来判断环境,找到catalina.sh脚本路径,将启动参数传递给catalina.sh执行.ca ...
- JAVA数据结构——单链表
链表:一. 顺序存储结构虽然是一种很有用的存储结构,但是他有如下几点局限性:1. 因为创造线性表的时候已经固定了空间,所以当需要扩充空间时,就需要重新创建一个地址连续的更大的存储空间.并把原有的数据元 ...
- OpenCV Sobel 导数
#include "opencv2/imgproc/imgproc.hpp" #include "opencv2/highgui/highgui.hpp" #i ...
- Nginx笔记总结十三:sub_filter内容替换
Nginx变异安装加上参数 --with-http_sub_module 配置文件: location ~* ^/portalproxy/([-]*)/portal(.*)$ { #sub_filte ...
- Ionic3学习笔记(十五)自定义 tab icon
本文为原创文章,转载请标明出处 美工做了一套 icon,自然是要用的.将 icon copy 到 assets 文件夹下. 例如 .icon-ios-home-custom 为 iOS icon 选中 ...
- 向MyEclipse的项目中导入js文件时,出现小红叉
这个问题困扰我很久.刚开始时,也没有解决,因此也在网上寻找解决方法,还是没能解决.最近做项目时再一次出现了这样的问题,于是决定还是再找找办法.在此,分享一下自己的解决方法,给正处于痛苦中的童鞋们带来解 ...
- 直播问答App乃虚火,调侃知识终不能长久盈利
随着王思聪在微博宣布"我.我乐意",一款叫"冲顶大会"的App冲到了大众面前,紧接着"芝士超人"携10亿元奖金从天而降,瞬间之内,在线答 ...
- 干了这碗蛋炒饭 继续APP性能提升
[前言] 什么是做功能,功能就是客户要一碗蛋炒饭,然后做了给他. 我想谁都明白,一家餐厅能活下去,是因为能把食材料理好,客户喜欢. 更准确的说,一家餐厅能活得下去,要考虑用户需求.食材,然后就是料理水 ...