tensorflow在文本处理中的使用——skip-gram & CBOW原理总结
摘自:http://www.cnblogs.com/pinard/p/7160330.html
先看下列三篇,再理解此篇会更容易些(个人意见)
- 词向量基础
CBOW与Skip-Gram用于神经网络语言模型
词向量基础
用词向量来表示词并不是word2vec的首创,在很久之前就出现了。最早的词向量是很冗长的,它使用是词向量维度大小为整个词汇表的大小,对于每个具体的词汇表中的词,将对应的位置置为1。比如我们有下面的5个词组成的词汇表,词"Queen"的序号为2, 那么它的词向量就是(0,1,0,0,0)(0,1,0,0,0)。同样的道理,词"Woman"的词向量就是(0,0,0,1,0)(0,0,0,1,0)。这种词向量的编码方式我们一般叫做1-of-N representation或者one hot representation.
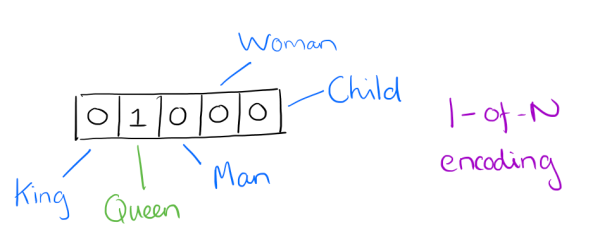
One hot representation用来表示词向量非常简单,但是却有很多问题。最大的问题是我们的词汇表一般都非常大,比如达到百万级别,这样每个词都用百万维的向量来表示简直是内存的灾难。这样的向量其实除了一个位置是1,其余的位置全部都是0,表达的效率不高,能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
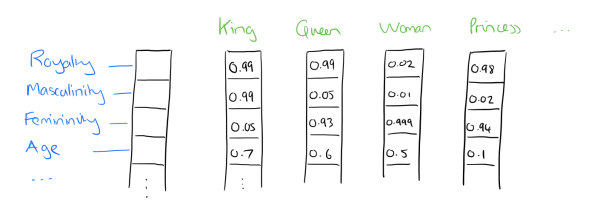
有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
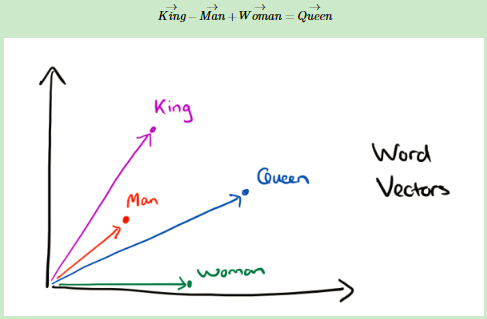
可见我们只要得到了词汇表里所有词对应的词向量,那么我们就可以做很多有趣的事情了。不过,怎么训练得到合适的词向量呢?一个很常见的方法是使用神经网络语言模型。
CBOW与Skip-Gram用于神经网络语言模型
在word2vec出现之前,已经有用神经网络DNN来用训练词向量进而处理词与词之间的关系了。采用的方法一般是一个三层的神经网络结构(当然也可以多层),分为输入层,隐藏层和输出层(softmax层)。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。
- CBOW模型:训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。
- Skip-Gram模型:和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。
******************************************************************************************************************************
- CBOW模型
- input:我们的上下文大小取值为4,上下文对应的词有8个,前后各4个,这8个词是我们模型的输入。由于CBOW使用的是词袋模型,因此这8个词都是平等的,也就是不考虑他们和我们关注的词之间的距离大小,只要在我们上下文之内即可。
- output:期望输出词是"Learning",输出是所有词的softmax概率(训练的目标是期望训练样本特定词对应的softmax概率最大)
- Network:对应的CBOW神经网络模型输入层有8个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。
- 这样当我们有新的需求,要求出某8个词对应的最可能的输出中心词时,我们可以通过一次DNN前向传播算法并通过softmax激活函数找到概率最大的词对应的神经元即可。
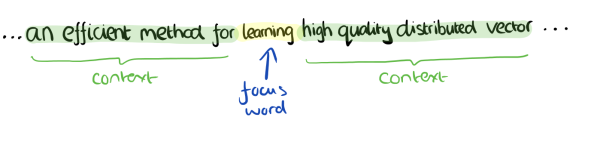
- Skip-Gram模型
- input:特定的这个词"Learning"是我们的输入
- output:我们的上下文大小取值为4,8个上下文词是我们的输出
- Network:我们的输入是特定词, 输出是softmax概率排前8的8个词,对应的Skip-Gram神经网络模型输入层有1个神经元,输出层有词汇表大小个神经元。隐藏层的神经元个数我们可以自己指定。通过DNN的反向传播算法,我们可以求出DNN模型的参数,同时得到所有的词对应的词向量。
- 这样当我们有新的需求,要求出某1个词对应的最可能的8个上下文词时,我们可以通过一次DNN前向传播算法得到概率大小排前8的softmax概率对应的神经元所对应的词即可。
以上就是神经网络语言模型中如何用CBOW与Skip-Gram来训练模型与得到词向量的大概过程。但是这和word2vec中用CBOW与Skip-Gram来训练模型与得到词向量的过程有很多的不同。
问题:
word2vec为什么 不用现成的DNN模型,要继续优化出新方法呢?最主要的问题是DNN模型的这个处理过程非常耗时。我们的词汇表一般在百万级别以上,这意味着我们DNN的输出层需要进行softmax计算各个词的输出概率的的计算量很大。有没有简化一点点的方法呢?可以去此处找答案
tensorflow在文本处理中的使用——skip-gram & CBOW原理总结的更多相关文章
- tensorflow在文本处理中的使用——Doc2Vec情感分析
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——CBOW词嵌入模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——skip-gram模型
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——Word2Vec预测
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——TF-IDF算法
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——词袋
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- tensorflow在文本处理中的使用——辅助函数
代码来源于:tensorflow机器学习实战指南(曾益强 译,2017年9月)——第七章:自然语言处理 代码地址:https://github.com/nfmcclure/tensorflow-coo ...
- TensorFlow实现文本情感分析详解
http://c.biancheng.net/view/1938.html 前面我们介绍了如何将卷积网络应用于图像.本节将把相似的想法应用于文本. 文本和图像有什么共同之处?乍一看很少.但是,如果将句 ...
- jQuery文本框中的事件应用
jQuery文本框中的事件应用 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "ht ...
随机推荐
- Codeforces 442B
题目链接 B. Andrey and Problem time limit per test 2 seconds memory limit per test 256 megabytes input s ...
- Beetl 3中文文档 转载 http://ibeetl.com/guide/
Beetl作者:李家智(闲大赋) <xiandafu@126.com> 1. 什么是Beetl 广告:闲大赋知识星球,付费会员 Beetl( 发音同Beetle ) 目前版本是3.0.7, ...
- MAC+VS Code+C/C++调试配置
目录 VS Code C/C++ 环境配置 添加工作区文件夹 Say Hello world 关于三个配置文件--Debug 原地址 VS Code C/C++ 环境配置 添加工作区文件夹 虽然代码能 ...
- python 类的创建
- 外贸电子商务网站之Prestashop 语言包安装
prestashop添加语言-下载语言包 我们找到中文简体(Chinese-Simplified)一行,点击最后一栏的下载(Download)按钮,我们点击下载,可以下到一个以语言的 ISO为文件名, ...
- 基于OPNET的路由协议仿真教程(AODV、OLSR 、DSR等)
前言: 目前由于项目需要,学习了基于opnet的网络仿真方法,发现该软件的学习资料少之又少,所以将自己搜集到的学习资料进行整理,希望能帮助后来的人. 主要参考资料:OPNET网络仿真(清华陈敏版) 仿 ...
- PLAY2.6-SCALA(六) 异步处理结果
1.创建异步的controller Play是一个自底向上的异步框架,play处理所有的request都是异步.非阻塞的.默认的方式是使用异步的controller.换句话说,contrller中的应 ...
- AtCoder Regular Contest 085 C HSI【概率论】
AtCoder Regular Contest 085 C HSI 没学概率论还不怎么看得懂,虽然感觉不难,其实明明可以猜出来的..... 参考博客:https://www.cnblogs.com/g ...
- String和Object转换
http://www.cnblogs.com/mingzi/archive/2009/01/03/1367474.html
- 2019-8-31-dotnet-控制台-Hangfire-后台定时任务
title author date CreateTime categories dotnet 控制台 Hangfire 后台定时任务 lindexi 2019-08-31 16:55:58 +0800 ...