Python爬虫爬取搜狐视频电影并存储到mysql数据库
数据获取方式:微信搜索关注【靠谱杨阅读人生】回复【电影】。
整理不易,资源付费,谢谢支持。
代码:
1 import time
2 import traceback
3 import requests
4 from lxml import etree
5 import re
6 from bs4 import BeautifulSoup
7 from lxml.html.diff import end_tag
8 import json
9 import pymysql
10 #连接数据库 获取游标
11 def get_conn():
12 """
13 :return: 连接,游标
14 """
15 # 创建连接
16 conn = pymysql.connect(host="127.0.0.1",
17 user="root",
18 password="000429",
19 db="movierankings",
20 charset="utf8")
21 # 创建游标
22 cursor = conn.cursor() # 执行完毕返回的结果集默认以元组显示
23 if ((conn != None) & (cursor != None)):
24 print("数据库连接成功!游标创建成功!")
25 else:
26 print("数据库连接失败!")
27 return conn, cursor
28 #关闭数据库连接和游标
29 def close_conn(conn, cursor):
30 if cursor:
31 cursor.close()
32 if conn:
33 conn.close()
34 return 1
35
36 def get_souhu():
37 url='https://film.sohu.com/list_0_0_0_2_2_1_60.html?channeled=1200100000'
38 #最新上架
39 new_url='https://film.sohu.com/list_0_0_0_2_1_1_60.html?channeled=1200100000'
40 #本周热播
41 week_url='https://film.sohu.com/list_0_0_0_2_0_1_60.html?channeled=1200100000'
42 headers={
43 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
44 }
45
46 #初始化list
47 templist=[]
48 dataRes=[]
49 #最受好评
50 for i in range(1,31):
51 url_1='https://film.sohu.com/list_0_0_0_2_2_'
52 auto=str(i)
53 url_2='_60.html?channeled=1200100000'
54 url=url_1+auto+url_2
55 response = requests.get(url, headers)
56 response.encoding = 'utf-8'
57 page_text = response.text
58 # etree_ = etree.HTML(page_text)
59 # 获取所有的li
60 soup = BeautifulSoup(page_text, 'lxml')
61 # 标签层级选择
62 li_list = soup.select('.movie-list>li')
63 print(len(li_list))
64 if(len(li_list)==0):
65 print("最受好评爬取结束!")
66 if(len(dataRes)!=0):
67 return dataRes
68 for li in li_list:
69 li_text=str(li)
70 # print(li_text)
71 li_soup=BeautifulSoup(li_text,'lxml')
72 name=li_soup.find('div',class_="v_name_info").text
73 #添加名字
74 templist.append(name)
75 # print(name)
76 #添加评分
77 score=li_soup.find('span',class_='v_score').text
78 #处理评分
79 score=score[-4:-1]
80 templist.append(score)
81 # print(score)
82 #添加path
83 path=li_soup.find('a',target="_blank")['href']
84 templist.append(path)
85 # print(path)
86 #添加播放状态
87 state="VIP"
88 templist.append(state)
89 print(templist)
90 dataRes.append(templist)
91 templist=[]
92 print("-------------------------------------------")
93 # print(len(dataRes))
94
95 # #最新上架
96 #
97 # templist = []
98 # for i in range(1,31):
99 # url_1='https://film.sohu.com/list_0_0_0_2_1_'
100 # auto=str(i)
101 # url_2='_60.html?channeled=1200100000'
102 # url=url_1+auto+url_2
103 # response = requests.get(url, headers)
104 # response.encoding = 'utf-8'
105 # page_text = response.text
106 # # etree_ = etree.HTML(page_text)
107 # # 获取所有的li
108 # soup = BeautifulSoup(page_text, 'lxml')
109 # # 标签层级选择
110 # li_list = soup.select('.movie-list>li')
111 # print(len(li_list))
112 # if(len(li_list)==0):
113 # print("最新上架爬取结束!")
114 # if(len(dataRes)!=0):
115 # return dataRes
116 # for li in li_list:
117 # li_text=str(li)
118 # # print(li_text)
119 # li_soup=BeautifulSoup(li_text,'lxml')
120 # name=li_soup.find('div',class_="v_name_info").text
121 # #添加名字
122 # templist.append(name)
123 # # print(name)
124 # #添加评分
125 # score=li_soup.find('span',class_='v_score').text
126 # #处理评分
127 # score=score[-4:-1]
128 # templist.append(score)
129 # # print(score)
130 # #添加path
131 # path=li_soup.find('a',target="_blank")['href']
132 # templist.append(path)
133 # # print(path)
134 # #添加播放状态
135 # state="VIP"
136 # templist.append(state)
137 # print(templist)
138 # dataRes.append(templist)
139 # templist=[]
140 # print("-------------------------------------------")
141 # # print(len(dataRes))
142 # #本周热播
143 # templist = []
144 # for i in range(1, 31):
145 # url_1 = 'https://film.sohu.com/list_0_0_0_2_0_'
146 # auto = str(i)
147 # url_2 = '_60.html?channeled=1200100000'
148 # url = url_1 + auto + url_2
149 # response = requests.get(url, headers)
150 # response.encoding = 'utf-8'
151 # page_text = response.text
152 # # etree_ = etree.HTML(page_text)
153 # # 获取所有的li
154 # soup = BeautifulSoup(page_text, 'lxml')
155 # # 标签层级选择
156 # li_list = soup.select('.movie-list>li')
157 # print(len(li_list))
158 # if (len(li_list) == 0):
159 # print("本周热播爬取结束!")
160 # if (len(dataRes) != 0):
161 # return dataRes
162 # for li in li_list:
163 # li_text = str(li)
164 # # print(li_text)
165 # li_soup = BeautifulSoup(li_text, 'lxml')
166 # name = li_soup.find('div', class_="v_name_info").text
167 # # 添加名字
168 # templist.append(name)
169 # # print(name)
170 # # 添加评分
171 # score = li_soup.find('span', class_='v_score').text
172 # # 处理评分
173 # score = score[-4:-1]
174 # templist.append(score)
175 # # print(score)
176 # # 添加path
177 # path = li_soup.find('a', target="_blank")['href']
178 # templist.append(path)
179 # # print(path)
180 # # 添加播放状态
181 # state = "VIP"
182 # templist.append(state)
183 # print(templist)
184 # dataRes.append(templist)
185 # templist = []
186 # print("-------------------------------------------")
187 # print(len(dataRes))
188 #list去重
189 # old_list = dataRes
190 # new_list = []
191 # for i in old_list:
192 # if i not in new_list:
193 # new_list.append(i)
194 # print(new_list) # [2, 3, 4, 5, 1]
195 return dataRes
196 #插入数据库
197 def insert_souhu():
198 cursor = None
199 conn = None
200 try:
201 count=0
202 list = get_souhu()
203 print(f"{time.asctime()}开始插入搜狐电影数据")
204 conn, cursor = get_conn()
205 sql = "insert into moviesohu (id,name,score,path,state) values(%s,%s,%s,%s,%s)"
206 for item in list:
207 print(item)
208 count = count + 1
209 #异常捕获,防止数据库主键冲突
210 try:
211 cursor.execute(sql, [0, item[0], item[1], item[2], item[3] ])
212 except pymysql.err.IntegrityError:
213 print("重复!跳过!")
214 conn.commit() # 提交事务 update delete insert操作
215 print(f"{time.asctime()}插入搜狐电影数据完毕")
216 except:
217 traceback.print_exc()
218 finally:
219 close_conn(conn, cursor)
220 return;
221
222 if __name__ == '__main__':
223 # get_iqy()
224 # get_souhu()
225 insert_souhu()
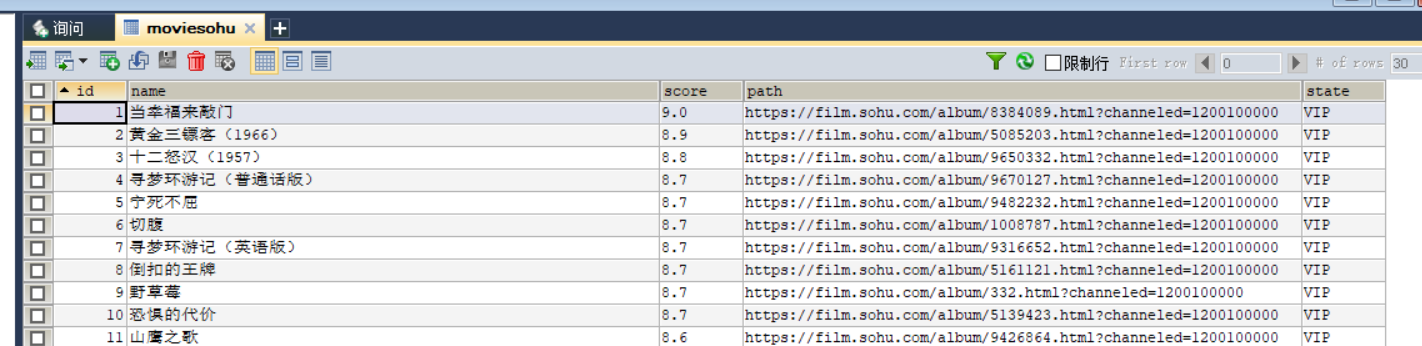
运行截图

数据库截图
建表语句
1 CREATE TABLE `moviesohu` (
2 `id` INT(11) NOT NULL AUTO_INCREMENT,
3 `name` VARCHAR(45) COLLATE utf8_bin NOT NULL,
4 `score` VARCHAR(45) COLLATE utf8_bin NOT NULL,
5 `path` VARCHAR(100) COLLATE utf8_bin NOT NULL,
6 `state` VARCHAR(10) COLLATE utf8_bin NOT NULL,
7 PRIMARY KEY (`name`),
8 KEY `id` (`id`)
9 ) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
Python爬虫爬取搜狐视频电影并存储到mysql数据库的更多相关文章
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- Python爬虫 - 爬取百度html代码前200行
Python爬虫 - 爬取百度html代码前200行 - 改进版, 增加了对字符串的.strip()处理 源代码如下: # 改进版, 增加了 .strip()方法的使用 # coding=utf-8 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- Python爬虫|爬取喜马拉雅音频
"GOOD Python爬虫|爬取喜马拉雅音频 喜马拉雅是知名的专业的音频分享平台,用户规模突破4.8亿,汇集了有声小说,有声读物,儿童睡前故事,相声小品等数亿条音频,成为国内发展最快.规模 ...
- python爬虫爬取内容中,-xa0,-u3000的含义
python爬虫爬取内容中,-xa0,-u3000的含义 - CSDN博客 https://blog.csdn.net/aiwuzhi12/article/details/54866310
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
随机推荐
- win32-使用GDI+缩放图像
滑动鼠标滚轮可以改变图像大小 #include <windows.h> #include <tchar.h> #include <Urlmon.h> // URLD ...
- 【Android逆向】静态分析+frida破解test2.apk
有了上一篇的基础 https://www.cnblogs.com/gradyblog/p/17152108.html 现在尝试静态分析的方式来处理 为什么还要多此一举,因为题眼告诉了我们是五位数字,所 ...
- mybatis处理集合、数组参数使用in查询
对于mybatis的参数类型是集合数组的时候进行查询. 第一种:参数list ,使用mybatis的标签 1 SELECT * FROM TABLE_NAME AS a WHERE 2 3 a.id ...
- Elasticsearch系列之-查询
Elasticsearch之-查询 查询分类: 基本查询:使用es内置查询条件进行查询 组合查询:把多个查询组合在一起进行复合查询 过滤:查询的同时,通过filter条件在不影响打分的情况下筛选数据 ...
- 【ACM专项练习#01】基本输入输出,如何加减
关于ACM,牛客其实也有专门的模拟练习:https://ac.nowcoder.com/acm/contest/5657#question 做这个也可以 关于while(cin>>n) 在 ...
- nginx判断是否手机访问
if ( $http_user_agent ~* "(Android|iPhone|Windows Phone|UC|Kindle|MicroMessenger |iPad)" ) ...
- Android系统瘦身
文件格式: Windows常见的文件系统是FAT16.FAT32,NTFS,在Windows环境提供了分区格式转换工具,可以在DOC环境下 使用 Convert命令(Convert e:/fs:nt ...
- base64实现图片多图上传功能
function webPic_upload($savepath,$url_data){$mark=ture; $pic_url=''; if(is_array($url_data)){ foreac ...
- 摆脱鼠标系列 - vscode vim 插件 常用快捷键整理
列表 只总结当前用到的快捷键,并且对 ctrl+c v w 这三个快捷键还是用vscode,过渡下. 复制当前行 yy 复制当前单词 yaw 移动到下一个单词 w 下移10行 . 这个有不管用了,估计 ...
- npm pack - npm install .tgz 离线安装 前端开发环境
npm pack - npm install .tgz 离线安装 前端开发环境 为什么有这个需求 曾经出差,到一个机构里面,里面是局域网,没有外网.后台都是java,刻录个光盘,然后就把开发环境装好了 ...