吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split def create_regression_data(n):
'''
创建回归模型使用的数据集
'''
X =5 * np.random.rand(n, 1)
y = np.sin(X).ravel()
# 每隔 5 个样本就在样本的值上添加噪音
y[::5] += 1 * (0.5 - np.random.rand(int(n/5)))
# 进行简单拆分,测试集大小占 1/4
return train_test_split(X, y,test_size=0.25,random_state=0) #KNN回归KNeighborsRegressor模型
def test_KNeighborsRegressor(*data):
X_train,X_test,y_train,y_test=data
regr=neighbors.KNeighborsRegressor()
regr.fit(X_train,y_train)
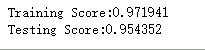
print("Training Score:%f"%regr.score(X_train,y_train))
print("Testing Score:%f"%regr.score(X_test,y_test)) #获取回归模型的数据集
X_train,X_test,y_train,y_test=create_regression_data(1000)
# 调用 test_KNeighborsRegressor
test_KNeighborsRegressor(X_train,X_test,y_train,y_test)
def test_KNeighborsRegressor_k_w(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 weights 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int')
weights=['uniform','distance'] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线
for weight in weights:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(weights=weight,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
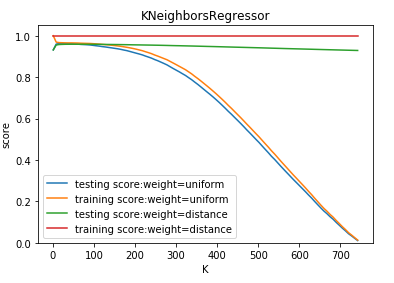
ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight)
ax.plot(Ks,training_scores,label="training score:weight=%s"%weight)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_w
test_KNeighborsRegressor_k_w(X_train,X_test,y_train,y_test)
def test_KNeighborsRegressor_k_p(*data):
'''
测试 KNeighborsRegressor 中 n_neighbors 和 p 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int')
Ps=[1,2,10] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线
for P in Ps:
training_scores=[]
testing_scores=[]
for K in Ks:
regr=neighbors.KNeighborsRegressor(p=P,n_neighbors=K)
regr.fit(X_train,y_train)
testing_scores.append(regr.score(X_test,y_test))
training_scores.append(regr.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:p=%d"%P)
ax.plot(Ks,training_scores,label="training score:p=%d"%P)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsRegressor")
plt.show() # 调用 test_KNeighborsRegressor_k_p
test_KNeighborsRegressor_k_p(X_train,X_test,y_train,y_test)

吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型的更多相关文章
- 吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——逻辑回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——ElasticNet回归
import numpy as np import matplotlib.pyplot as plt from matplotlib import cm from mpl_toolkits.mplot ...
- 吴裕雄 python 机器学习——Lasso回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——岭回归
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model from s ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
随机推荐
- 实用沙盒工具 —— VMware Workstation15安装教程
一:简介 VMware Workstation(中文名"威睿工作站")是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发.测试 .部署新 ...
- ABC155 D pair 边界处理取整
ABC155 D pair 取整坑点 思路 很常见的一道题,二分找答案,然后看这个答案排rank?,排rank?用二分继续找一遍二分套二分即可,就是边界比较烦,老年人写的心情烦躁 老年人被取整坑的几天 ...
- [ZJOI2009] 狼与羊的故事 - 最小割
给定一个\(N \times M\)方格矩阵,每个格子可在\(0,1,2\)中取值.要求在方格的边上进行划分,使得任意联通块内不同时包含\(1\)和\(2\)的格子. ________________ ...
- mybatis大于等于小于等于的写法
第一种写法(1): 原符号 < <= > >= & ' " 替换符号 < <= > >= & ' " ...
- google protocol 入门 demo
ubunbu系统下google protobuf的安装 说明: 使用protobuf时需要安装两部分: 第一部分为*.proto文件的编译器,它负责把定义的*.proto文件生成对应的c++类的.h和 ...
- python求极值点(波峰波谷)
python求极值点主要用到scipy库. 1. 首先可先选择一个函数或者拟合一个函数,这里选择拟合数据:np.polyfit import pandas as pd import matplotli ...
- Ant风格表达式
1. ?:匹配任意一个字符 * :匹配0或者任意数量的字符 ** :匹配0或更多的目录
- 棋盘划分问题中4的k次方减一是三的倍数
1.数学归纳法(万物皆可数学归纳) ①当n=1时:4-1=3(是三的倍数) ②假设n-1成立证明n成立:4n-1=4n-1*(4-1)+4n-1-1 =3*4n-1+(4n-1-1) 所以4n-1%3 ...
- 【音乐欣赏】《Heart Made of Stone》 - The Tech Thieves
曲名:Heart Made of Stone 作者:The Tech Thieves Yeah It's been years now and I wonder Is it over? Do you ...
- java课后作业3
1.动手动脑 由于类中定义了需要参数的构造方法,导致系统不再提供默认的构造方法. 2.java字段初始化 运行结果 100 300 java字段在初始化时先按照对应的构造方法执行.若构造方法中没有对变 ...