吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型
import numpy as np
import matplotlib.pyplot as plt from sklearn import neighbors, datasets
from sklearn.model_selection import train_test_split def load_classification_data():
# 使用 scikit-learn 自带的手写识别数据集 Digit Dataset
digits=datasets.load_digits()
X_train=digits.data
y_train=digits.target
# 进行分层采样拆分,测试集大小占 1/4
return train_test_split(X_train, y_train,test_size=0.25,random_state=0,stratify=y_train) #KNN分类KNeighborsClassifier模型
def test_KNeighborsClassifier(*data):
X_train,X_test,y_train,y_test=data
clf=neighbors.KNeighborsClassifier()
clf.fit(X_train,y_train)
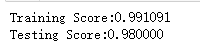
print("Training Score:%f"%clf.score(X_train,y_train))
print("Testing Score:%f"%clf.score(X_test,y_test)) # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier
test_KNeighborsClassifier(X_train,X_test,y_train,y_test)
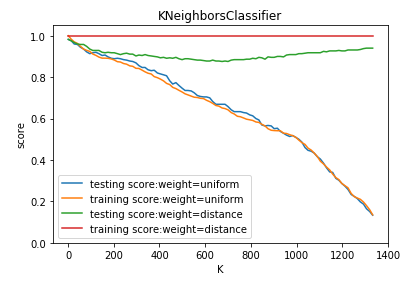
def test_KNeighborsClassifier_k_w(*data):
'''
测试 KNeighborsClassifier 中 n_neighbors 和 weights 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,num=100,endpoint=False,dtype='int')
weights=['uniform','distance'] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 weights 下, 预测得分随 n_neighbors 的曲线
for weight in weights:
training_scores=[]
testing_scores=[]
for K in Ks:
clf=neighbors.KNeighborsClassifier(weights=weight,n_neighbors=K)
clf.fit(X_train,y_train)
testing_scores.append(clf.score(X_test,y_test))
training_scores.append(clf.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:weight=%s"%weight)
ax.plot(Ks,training_scores,label="training score:weight=%s"%weight)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsClassifier")
plt.show() # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier_k_w
test_KNeighborsClassifier_k_w(X_train,X_test,y_train,y_test)
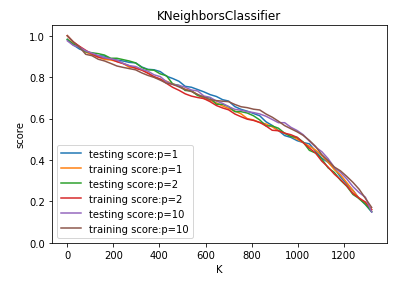
def test_KNeighborsClassifier_k_p(*data):
'''
测试 KNeighborsClassifier 中 n_neighbors 和 p 参数的影响
'''
X_train,X_test,y_train,y_test=data
Ks=np.linspace(1,y_train.size,endpoint=False,dtype='int')
Ps=[1,2,10] fig=plt.figure()
ax=fig.add_subplot(1,1,1)
### 绘制不同 p 下, 预测得分随 n_neighbors 的曲线
for P in Ps:
training_scores=[]
testing_scores=[]
for K in Ks:
clf=neighbors.KNeighborsClassifier(p=P,n_neighbors=K)
clf.fit(X_train,y_train)
testing_scores.append(clf.score(X_test,y_test))
training_scores.append(clf.score(X_train,y_train))
ax.plot(Ks,testing_scores,label="testing score:p=%d"%P)
ax.plot(Ks,training_scores,label="training score:p=%d"%P)
ax.legend(loc='best')
ax.set_xlabel("K")
ax.set_ylabel("score")
ax.set_ylim(0,1.05)
ax.set_title("KNeighborsClassifier")
plt.show() # 获取分类模型的数据集
X_train,X_test,y_train,y_test=load_classification_data()
# 调用 test_KNeighborsClassifier_k_p
test_KNeighborsClassifier_k_p(X_train,X_test,y_train,y_test)
吴裕雄 python 机器学习——KNN分类KNeighborsClassifier模型的更多相关文章
- 吴裕雄 python 机器学习——KNN回归KNeighborsRegressor模型
import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors, datasets from skle ...
- 吴裕雄 python 机器学习——半监督学习LabelSpreading模型
import numpy as np import matplotlib.pyplot as plt from sklearn import metrics from sklearn import d ...
- 吴裕雄 python 机器学习——层次聚类AgglomerativeClustering模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——密度聚类DBSCAN模型
import numpy as np import matplotlib.pyplot as plt from sklearn import cluster from sklearn.metrics ...
- 吴裕雄 python 机器学习——支持向量机非线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习——支持向量机线性回归SVR模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 吴裕雄 python 机器学习-KNN(2)
import matplotlib import numpy as np import matplotlib.pyplot as plt from matplotlib.patches import ...
- 吴裕雄 python 机器学习-KNN算法(1)
import numpy as np import operator as op from os import listdir def classify0(inX, dataSet, labels, ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
随机推荐
- 计算器程序编写_python
一.计算一串字符串的最终值,相当于eval函数功能: #!/usr/bin/env python # _*_ coding:utf-8 _*_ #Author:chenxz import re def ...
- eclipse unable to start within 45 seconds
在eclipse4.8.2中运行tomcat8.5项目时,提示出错: Server Tomcat v8.0 Server at localhost was unable to start within ...
- 如何架构一个 React 项目?
编程有点像搞园艺.比起竭力去对付BUG(虫子),我们更愿意把一切弄得整洁有序,以免最后落得个身在荒野丛林中.低劣的架构会拖我们的后腿,也会使得BUG更容易钻进系统里去. 想要对你的项目进行架构,方法有 ...
- c# Gridview 自动分页功能 解决后面页面不显示问题
操作步骤: 操作如下: 1.更改GrdView控件的AllowPaging属性为true. 2.更改GrdView控件的PageSize属性为 任意数值(默认为10) 3.更改GrdView控件的Pa ...
- AcWing 1010. 拦截导弹
//贪心加dp #include<iostream> using namespace std ; ; int n; int q[N]; int f[N]; int g[N];//存每个序列 ...
- PHP pdf 转 图片
function pdf2png($pdf,$path,$page=-1) { if(!extension_loaded('imagick')) { return false; } if(!file_ ...
- vue 3.0 项目搭建移动端 (七) 安装Vant
# 通过 npm 安装 npm i vant -S 安装完配置 babel.config.js module.exports = { presets: ['@vue/app'], plugins: [ ...
- 【Python】字符串处理方法
- [HNOI2014] 道路堵塞 - 最短路,线段树
对不起对不起,辣鸡蒟蒻又来用核弹打蚊子了 完全ignore了题目给出的最短路,手工搞出一个最短路,发现对答案没什么影响 所以干脆转化为经典问题:每次询问删掉一条边后的最短路 如果删掉的是非最短路边,那 ...
- Log4j的isdebugEnabled的作用
转自:https://www.iteye.com/blog/zhukewen-java-1174017 在项目中我们经常可以看到这样的代码: if (logger.isDebugEnabled()) ...