吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型
# 导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn import model_selection
from sklearn.linear_model import Ridge,RidgeCV
# 读取糖尿病数据集
diabetes = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\08\\diabetes.xlsx', sep = '')
print(diabetes.shape)
print(diabetes.head())
# 构造自变量(剔除患者性别、年龄和因变量)
predictors = diabetes.columns[2:-1]
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(diabetes[predictors], diabetes['Y'],test_size = 0.2, random_state = 1234 )
# 构造不同的Lambda值
Lambdas = np.logspace(-5, 2, 200)
print(Lambdas.shape)
# 构造空列表,用于存储模型的偏回归系数
ridge_cofficients = []
# 循环迭代不同的Lambda值
for Lambda in Lambdas:
ridge = Ridge(alpha = Lambda, normalize=True)
ridge.fit(X_train, y_train)
ridge_cofficients.append(ridge.coef_)
print(np.shape(ridge_cofficients))
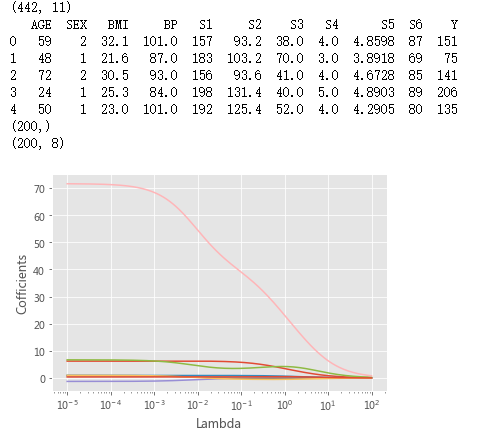
# 绘制Lambda与回归系数的关系
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
plt.plot(Lambdas, ridge_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Lambda')
plt.ylabel('Cofficients')
# 图形显示
plt.show()
# 岭回归模型的交叉验证
# 设置交叉验证的参数,对于每一个Lambda值,都执行10重交叉验证
ridge_cv = RidgeCV(alphas = Lambdas, normalize=True, scoring='neg_mean_squared_error', cv = 10)
print(ridge_cv)
# 模型拟合
ridge_cv.fit(X_train, y_train)
# 返回最佳的lambda值
ridge_best_Lambda = ridge_cv.alpha_
print(ridge_best_Lambda)

# 导入第三方包中的函数
from sklearn.metrics import mean_squared_error
# 基于最佳的Lambda值建模
ridge = Ridge(alpha = ridge_best_Lambda, normalize=True)
ridge.fit(X_train, y_train)
# 返回岭回归系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [ridge.intercept_] + ridge.coef_.tolist())
# 预测
ridge_predict = ridge.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,ridge_predict))
print(RMSE)

# 导入第三方模块中的函数
from sklearn.linear_model import Lasso,LassoCV
# 构造空列表,用于存储模型的偏回归系数
lasso_cofficients = []
for Lambda in Lambdas:
lasso = Lasso(alpha = Lambda, normalize=True, max_iter=10000)
lasso.fit(X_train, y_train)
lasso_cofficients.append(lasso.coef_)
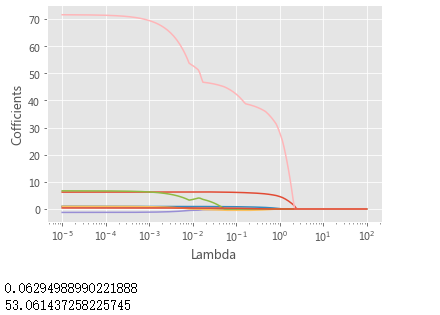
# 绘制Lambda与回归系数的关系
plt.plot(Lambdas, lasso_cofficients)
# 对x轴作对数变换
plt.xscale('log')
# 设置折线图x轴和y轴标签
plt.xlabel('Lambda')
plt.ylabel('Cofficients')
# 显示图形
plt.show()
# LASSO回归模型的交叉验证
lasso_cv = LassoCV(alphas = Lambdas, normalize=True, cv = 10, max_iter=10000)
lasso_cv.fit(X_train, y_train)
# 输出最佳的lambda值
lasso_best_alpha = lasso_cv.alpha_
print(lasso_best_alpha)
# 基于最佳的lambda值建模
lasso = Lasso(alpha = lasso_best_alpha, normalize=True, max_iter=10000)
lasso.fit(X_train, y_train)
# 返回LASSO回归的系数
pd.Series(index = ['Intercept'] + X_train.columns.tolist(),data = [lasso.intercept_] + lasso.coef_.tolist())
# 预测
lasso_predict = lasso.predict(X_test)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,lasso_predict))
print(RMSE)
# 导入第三方模块
from statsmodels import api as sms
# 为自变量X添加常数列1,用于拟合截距项
X_train2 = sms.add_constant(X_train)
X_test2 = sms.add_constant(X_test)
# 构建多元线性回归模型
linear = sms.formula.OLS(y_train, X_train2).fit()
# 返回线性回归模型的系数
print(linear.params)
# 模型的预测
linear_predict = linear.predict(X_test2)
# 预测效果验证
RMSE = np.sqrt(mean_squared_error(y_test,linear_predict))
print(RMSE)

吴裕雄 数据挖掘与分析案例实战(7)——岭回归与LASSO回归模型的更多相关文章
- 吴裕雄 数据挖掘与分析案例实战(15)——DBSCAN与层次聚类分析
# 导入第三方模块import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfr ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 吴裕雄 数据挖掘与分析案例实战(13)——GBDT模型的应用
# 导入第三方包import pandas as pdimport matplotlib.pyplot as plt # 读入数据default = pd.read_excel(r'F:\\pytho ...
- 吴裕雄 数据挖掘与分析案例实战(12)——SVM模型的应用
import pandas as pd # 导入第三方模块from sklearn import svmfrom sklearn import model_selectionfrom sklearn ...
- 吴裕雄 数据挖掘与分析案例实战(10)——KNN模型的应用
# 导入第三方包import pandas as pd # 导入数据Knowledge = pd.read_excel(r'F:\\python_Data_analysis_and_mining\\1 ...
- 吴裕雄 数据挖掘与分析案例实战(8)——Logistic回归分类模型
import numpy as npimport pandas as pdimport matplotlib.pyplot as plt # 自定义绘制ks曲线的函数def plot_ks(y_tes ...
- 吴裕雄 数据挖掘与分析案例实战(5)——python数据可视化
# 饼图的绘制# 导入第三方模块import matplotlibimport matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['S ...
- 吴裕雄 数据挖掘与分析案例实战(4)——python数据处理工具:Pandas
# 导入模块import pandas as pdimport numpy as np # 构造序列gdp1 = pd.Series([2.8,3.01,8.99,8.59,5.18])print(g ...
- 吴裕雄 数据挖掘与分析案例实战(3)——python数值计算工具:Numpy
# 导入模块,并重命名为npimport numpy as np# 单个列表创建一维数组arr1 = np.array([3,10,8,7,34,11,28,72])print('一维数组:\n',a ...
随机推荐
- 阿里巴巴Java开发手册-并发处理
1. [强制]获取单例对象需要保证线程安全,其中的方法也要保证线程安全.说明:资源驱动类.工具类.单例工厂类都需要注意. 2. [强制]创建线程或线程池时请指定有意义的线程名称,方便出错时回溯.正例: ...
- python下的类的部分特点
#coding=utf-8 class data: def __init__(self): #构造函数 self.name=' def pp(self): print self.name class ...
- Exchange 2003服务器中如何在公司资料夹中设置共享行事历
Exchange 2003服务器中如何在公司资料夹中设置共享行事历 编写人:左丘文 2018-2-23 春节假期归来,开工第一天,感觉还没有从假期中恢复及调整过来.突然想到了我已经荒废了近一年的园子, ...
- 微信JS-SDK官方示例程序
示例地址:http://203.195.235.76/jssdk/ /* * 注意: * 1. 所有的JS接口只能在公众号绑定的域名下调用,公众号开发者需要先登录微信公众平台进入“公众号设置”的“功能 ...
- windows下使用vscode编写运行以及调试Python
更新于2018年10月: 首先去python官网下载python3 地址:https://www.python.org/downloads/windows/ 下载好后直接安装 记得勾选添加环境变量 ...
- POJ 2139 Six Degrees of Cowvin Bacon (floyd)
Six Degrees of Cowvin Bacon Time Limit : 2000/1000ms (Java/Other) Memory Limit : 131072/65536K (Ja ...
- 如何使用沙箱测试单笔转账到支付宝账号(php版) https://openclub.alipay.com/read.php?tid=1770&fid=28
说明: 本帖是利用支付宝沙箱测试电脑网站支付接口 测试环境:Apache2.4.23 +php 5.6.25 沙箱环境测试正式环境请修改网关为下方值 复制代码 1 正式环境网关:htt ...
- pycharm下getpass.getpass()卡住
pycharm下getpass.getpass()卡住不运行是什么问题 python pycharm 首先声明 下面这几行代码在命令行和eclipse下都能正常运行 import getpass pr ...
- 信息学奥赛(NOIP)初赛学习方法推荐
首先声明:本帖针对初学者,本帖只是列出一个大概的框架,不属于自学方法,有条件有能力,请找一位好老师来教,多跟前辈交流经验.(否则多会出现事倍功半的悲剧!) 一.初赛内容 初赛偏重于基础知识. 1. 一 ...
- MAN 手册各章节功能介绍及快捷键键位整理
前言 Man 手册页(Manua pages ,缩写man page) 是在linux操作系统在线软件文档的一种普遍形式.内容包括计算机程序库和系统调用等命令的帮助手册. 手册页是用troff排版 ...