Scrapy的Spider类和CrawlSpider类
Scrapy shell
用来调试Scrapy 项目代码的 命令行工具,启动的时候预定义了Scrapy的一些对象
设置 shell
Scrapy 的shell是基于运行环境中的python 解释器shell
本质上就是通过命令调用shell,并在启动的时候预定义需要使用的对象
scrapy允许通过在项目配置文件”scrapy.cfg”中进行配置来指定解释器shell,例如:
[settings]
shell = ipython
启动 shell
启动Scrapy shell的命令语法格式:scrapy shell [option] [url|file]
url 就是你想要爬取的网址,分析本地文件时一定要带上路径,scrapy shell默认当作url
Spider类
运行流程
首先生成初始请求以爬取第一个URL,并指定要使用从这些请求下载的响应调用的回调函数
在回调函数中,解析响应(网页)并返回,Item对象、Request对象或这些对象的可迭代的dicts
最后,从蜘蛛返回的项目通常会持久保存到数据库(在某些项目管道中)或导出写入文件
属性

name: spider的名称、必须是唯一的
start_urls: 起始urls、初始的Request请求来源
customer_settings: 自定义设置、运行此蜘蛛时将覆盖项目范围的设置。必须将其定义为类属性,因为在实例化之前更新了设置
logger: 使用Spider创建的Python日志器
方法
from_crawler:创建spider的类方法
start_requests:开始请求、生成request交给引擎下载返回response
parse:默认的回调方法,在子类中必须要重写
close:spider关闭时调用
CrawlSpider类
Spider类 是匹配url,然后返回request请求
CrawlSpider类 根据url规则,自动生成request请求
创建CrawlSpider类爬虫文件
crapy genspider -t crawl 爬虫名 域名
LinkExtractor参数

allow:正则表达式,满足的url会被提取出来
deny:正则表达式,满足的url不会被提取出来
estrict_xpaths:路径表达式,符合路径的标签提取出来
Rule参数

linkextractor:提取链接的实例对象
callback:回调函数
follow:指定是否应该从使用此规则提取的每个响应中跟踪链接
process_links:用于过滤连接的回调函数
process_request:用于过滤请求的回调函数
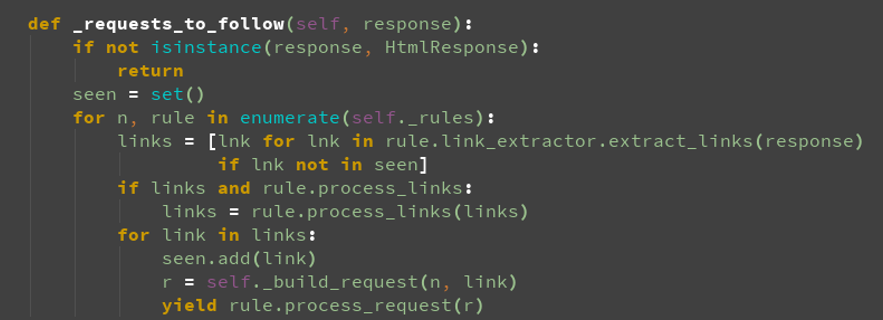
url去重
Scrapy的Spider类和CrawlSpider类的更多相关文章
- Scrapy框架——CrawlSpider类爬虫案例
Scrapy--CrawlSpider Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spide ...
- 13.CrawlSpider类爬虫
1.CrawlSpider介绍 Scrapy框架中分两类爬虫,Spider类和CrawlSpider类. 此案例采用的是CrawlSpider类实现爬虫. 它是Spider的派生类,Spider类的设 ...
- python爬虫入门(八)Scrapy框架之CrawlSpider类
CrawlSpider类 通过下面的命令可以快速创建 CrawlSpider模板 的代码: scrapy genspider -t crawl tencent tencent.com CrawSpid ...
- scrapy的CrawlSpider类
了解CrawlSpider 踏实爬取一般网站的常用spider,其中定义了一些规则(rule)来提供跟进link的方便机制,也许该spider不适合你的目标网站,但是对于大多数情况是可以使用的.因此, ...
- scrapy项目4:爬取当当网中机器学习的数据及价格(CrawlSpider类)
scrapy项目3中已经对网页规律作出解析,这里用crawlspider类对其内容进行爬取: 项目结构与项目3中相同如下图,唯一不同的为book.py文件 crawlspider类的爬虫文件book的 ...
- scrapy系列(四)——CrawlSpider解析
CrawlSpider也继承自Spider,所以具备它的所有特性,这些特性上章已经讲过了,就再在赘述了,这章就讲点它本身所独有的. 参与过网站后台开发的应该会知道,网站的url都是有一定规则的.像dj ...
- Scrapy(五):CrawlSpider的使用
Scrapy(五):CrawlSpider的使用 说明 :CrawlSpider,就是一个类,是Spider的一个子类,也是一个官方类,因为是子类,所以功能更加的强大,多了一项功能:去指定的页面中来抓 ...
- 爬虫07 /scrapy图片爬取、中间件、selenium在scrapy中的应用、CrawlSpider、分布式、增量式
爬虫07 /scrapy图片爬取.中间件.selenium在scrapy中的应用.CrawlSpider.分布式.增量式 目录 爬虫07 /scrapy图片爬取.中间件.selenium在scrapy ...
- Scrapy框架-Spider
目录 1. Spider 2.Scrapy源代码 2.1. Scrapy主要属性和方法 3.parse()方法的工作机制 1. Spider Spider类定义了如何爬取某个(或某些)网站.包括了爬取 ...
随机推荐
- ReactNative: 使用AppReistry注册类
一.简介 每一个应用程序的运行都有一个入口文件或者入口函数,例如iOS中的使用UIApplicationMain类完成入口函数的实现,在React-Native中,AppRegistry类就肩负着这个 ...
- 在Ubuntu 18.04系统上安装Pydio Cells详细图文教程
前言 基于云的协作工具Pydio cell提供了一系列灵活的特性,包括应用内消息传递.文件共享和版本控制.下面逐步介绍安装过程. Pydio cell最初是一个简单的基于云的文件共享系统,但经过升 ...
- C语言笔记 03_常量&存储类
常量 常量是固定值,在程序执行期间不会改变.这些固定的值,又叫做字面量. 常量可以是任何的基本数据类型,比如整数常量.浮点常量.字符常量,或字符串字面值,也有枚举常量. 整数常量 整数常量可以是十进制 ...
- 设计模式(含UML、设计原则、各种模式讲解链接)
一.统一建模语言UML UML是一种开放的方法,用于说明.可视化.构建和编写一个正在开发的.面向对象的.软件密集系统的制品的开放方法 UML展现了一系列最佳工程实践,这些最佳实践在对大规模,复杂系统进 ...
- 初识NLP 自然语言处理
接下来的一段时间,要深入研究下自然语言处理这一个学科,以期能够带来工作上的提升. 学习如何实用python实现各种有关自然语言处理有关的事物,并了解一些有关自然语言处理的当下和新进的研究主题. NLP ...
- PlayJava Day024
造型Cast补充: 子类的对象可以赋值给父类的变量 注意:Java中不存在对象对对象的赋值 父类的对象不能赋值给子类的变量 例: Vechicle v ; Car c = new Car() ; v ...
- MySQL的多表联查
1.内连接 规则:返回两个表的公共记录 语法: -- 语法一 select * from 表1 inner join 表2 on 表1.公共字段=表2.公共字段 -- 语法 ...
- angular cli http请求封装+拦截器配置+ 接口配置文件
内容:接口配置文件.http请求封装 .拦截器验证登录 1.接口配置文件 app.api.ts import { Component, OnInit } from '@angular/core'; / ...
- leaflet-webpack 入门开发系列五地图卷帘(附源码下载)
前言 leaflet-webpack 入门开发系列环境知识点了解: node 安装包下载webpack 打包管理工具需要依赖 node 环境,所以 node 安装包必须安装,上面链接是官网下载地址 w ...
- 使用可移动表空间(TTS)的最佳做法 (Doc ID 1457876.1)
Best Practices for Using Transportable Tablespaces (TTS) (Doc ID 1457876.1) APPLIES TO: Oracle Datab ...