00、Word Count
1、开发环境
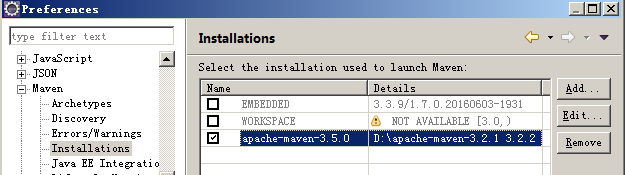
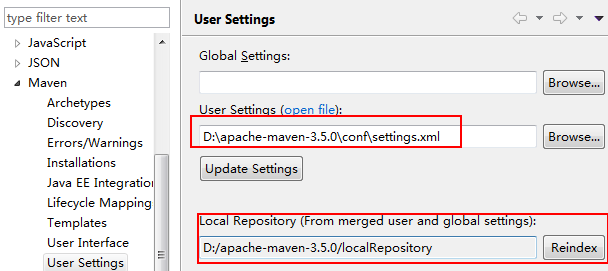
2、本地Local模拟运行

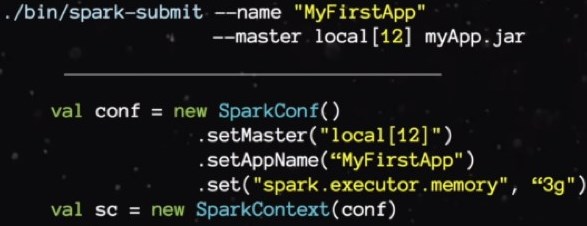
2.1、Java版
</project>
}
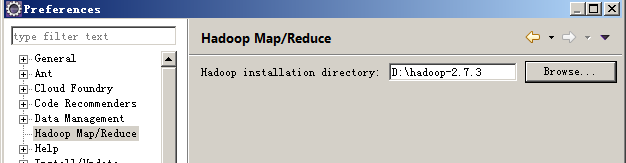
2.2、配置Hadoop客户端


2.3、Scala版:
}
4、在spark-shell中运行
00、Word Count的更多相关文章
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- Word Count
Word Count 一.个人Gitee地址:https://gitee.com/godcoder979/(该项目完整代码在这里) 二.项目简介: 该项目是一个统计文件字符.单词.行数等数目的应用程序 ...
- Mac下hadoop运行word count的坑
Mac下hadoop运行word count的坑 Word count体现了Map Reduce的经典思想,是分布式计算中中的hello world.然而博主很幸运地遇到了Mac下特有的问题Mkdir ...
- 软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序
软件工程第三个程序:“WC项目” —— 文件信息统计(Word Count ) 命令行程序 格式:wc.exe [parameter][filename] 在[parameter]中,用户通过输入参数 ...
- word count程序,以及困扰人的宽字符与字符
一个Word Count程序,由c++完成,有行数.词数.能完成路径下文件的遍历. 遍历文件部分的代码如下: void FindeFile(wchar_t *pFilePath) { CFileFin ...
- Spark的word count
word count package com.spark.app import org.apache.spark.{SparkContext, SparkConf} /** * Created by ...
- 无插件,无com组件,利用EXCEL、WORD模板做数据导出(一)
本次随笔主要讲述着工作中是如何解决数据导出的,对于数据导出到excel在日常工作中大家还是比较常用的,那导出到word呢,改如何处理呢,简单的页面导出问题应该不大,但是如果是标准的公文导出呢,要保证其 ...
- C# 读写xml、excel、word、ppt、access
C# 读写xml.excel.word.access 这里只是起个头,不做深入展开,方便以后用到参考 读写xml,主要使用.net 的xml下的document using System;using ...
- Java --本地提交MapReduce作业至集群☞实现 Word Count
还是那句话,看别人写的的总是觉得心累,代码一贴,一打包,扔到Hadoop上跑一遍就完事了????写个测试样例程序(MapReduce中的Hello World)还要这么麻烦!!!?,还本地打Jar包, ...
随机推荐
- node.js版本管理
Node安装 Node的安装需要依赖很多,如gcc等,首先我们需要将这些安装成功,用rpm命令查看下,果然我们并没有gcc等,所以要用yum进行安装(基于centos6.9版本): yum -y in ...
- linux下在root用户登陆状态下,以指定用户运行脚本程序实现方式
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAMcAAABKCAIAAACASdeXAAAEoUlEQVR4nO2dy7WlIBBFTYIoSIIkmD ...
- html5的audio实现高仿微信语音播放效果Demo
HTML部分: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <t ...
- $on在构造器外部添加事件$once执行一次的事件$off关闭事件
$on 在构造器外部添加事件. $on接收两个参数,第一个参数是调用时的事件名称,第二个参数是一个匿名方法. 如果按钮在作用域外部,可以利用$emit来执行. html <div id=&quo ...
- Java中文字符所占的字节数
Java语言中,中文字符所占的字节数取决于字符的编码方式,一般情况下,采用ISO8859-1编码方式时,一个中文字符与一个英文字符一样只占1个字节:采用GB2312或GBK编码方式时,一个中文字符占2 ...
- solr配置IKAnalyzer抛出ClassNotFoundException
这个问题搞了很久,在QQ群上问了很久,关键很气人的是我居然被群主给开了.我也是醉了.我不知道我哪里得罪了那个solr群的群主. 废话不多说.抛出的异常如下: 刚开始一直认为是没有找到类,也就相当于没找 ...
- 根据cookie记录跟踪ID来确定分享对象
一 :思路分析 1:用户注册的时候标记推客 2:推客生成分享链接 分享链接构成 (环境前缀+(此链接打开时需要调用的接口+推客的标记+&url=(商品的链接))) 3:需要写一个分享链接调 ...
- MSC VS 版本对应
MSC VS 版本对应 msc是微软的C编译器,安装对应的VS版本会带有,两者版本对应如下: MS VC++ 14.0 _MSC_VER = 1900 (Visual Studio 2015) MS ...
- nginx重启命令
service nginx restart nginx -s re
- 004.etcd集群部署-动态发现
一 etcd发现简介 1.1 需求背景 在实际环境中,集群成员的ip可能不会提前知道.如使用dhcp自动获取的情况,在这些情况下,使用自动发现来引导etcdetcd集群,而不是指定静态配置,这个过程被 ...