python scrapy爬取前程无忧招聘信息
使用scrapy框架之前,使用以下命令下载库:
pip install scrapy -i https://pypi.tuna.tsinghua.edu.cn/simple
1、创建项目文件夹
scrapy startproject 项目名

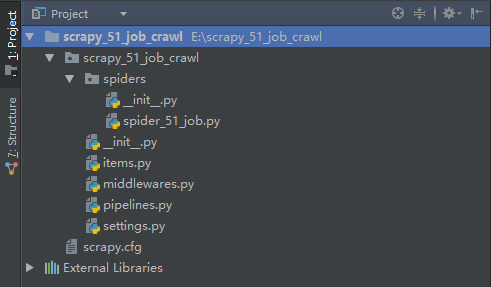
2、用pyCharm查看生成的项目目录
项目创建成功之后,会得到图中的文件目录

3、创建爬虫
根据提示cd到创建的项目文件中

使用以下命令创建爬虫
说明:
51_job.com ---- ----主域名
scrapy genspider spider_51_job 51job.com

此时,文件中多出了一个py文件
4、spider_51_job.py(代码)
说明:
from ..items import Scrapy51JobCrawlItem ---- -----调用存储类(存储类代码会在后面呈现)
# -*- coding: utf-8 -*-
import scrapy
from ..items import Scrapy51JobCrawlItem class QianPcSpider(scrapy.Spider):
name = '51job_crawl'
allowed_domains = ['51job.com']
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,%s.html?' #循环获取网页链接
a = []
for i in range(1, 5):
urls = url % i
a.append(urls)
start_urls = a def parse(self, response):
#获取职位名称
title_list = response.xpath('//div[@class="el"]/p/span/a')
for i in title_list:
# 职位href
page_url = i.xpath('./@href').get()
# 如果href存在,则回调执行函数item
if page_url:
yield scrapy.Request(page_url, callback=self.item) def item(self, response):
"""使用定义好的类"""
data_list = Scrapy51JobCrawlItem()
data_list['title'] = response.xpath('//div[@class="cn"]/h1/@title').get() #职位名称
data_list['salary'] = response.xpath('//div[@class="cn"]/strong/text()').get() #职位工资
data_list['company'] = response.xpath('//div[@class="cn"]/p/a/@title').get() #公司名称
data_list['Work_address'] = response.xpath('//div[@class="bmsg inbox"]/p/text()').get() #工作地址
yield data_list
5、定义存储类
items.py(代码)
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html import scrapy class Scrapy51JobCrawlItem(scrapy.Item):
# 职位名称
title = scrapy.Field()
# 职位工资
salary = scrapy.Field()
# 公司名称
company = scrapy.Field()
# 工作地址
Work_address = scrapy.Field()
6、管道相关代码
pipelines.py(代码)
# -*- coding: utf-8 -*- # Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# from flask import json
# from .items import Scrapy51JobCrawlItem
import json
from .items import Scrapy51JobCrawlItem class QcwyPipeline(object):
def process_item(self, item, spider):
return item class ScrapyDemoPipelin(object):
def open_spider(self, spider):
self.file = open('51_job.csv', 'w') def process_item(self, item, spider):
if isinstance(item,Scrapy51JobCrawlItem):
# 1.item - dict
dict_data = dict(item)
# 2.dict --str
str_data = json.dumps(dict_data) + '\n'
# 3.写入文件
self.file.write(str_data) return item def close_spider(self, spider):
self.file.close()
修改完成之后,要在setting中开启管道(管道默认是关闭的)

7、在项目中创建一个main.py 启动文件
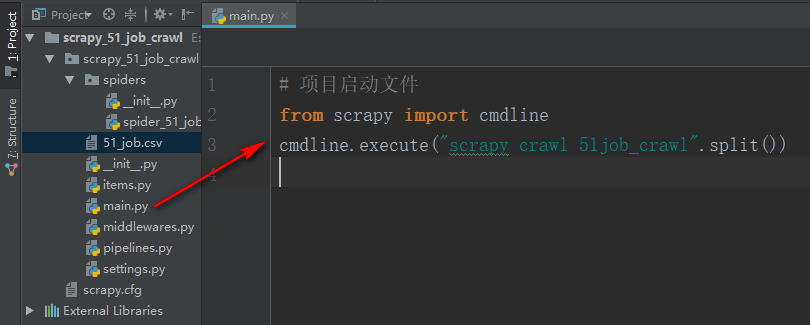
下面是相关代码:
# 项目启动文件
from scrapy import cmdline
cmdline.execute("scrapy crawl 51job_crawl".split())
代码运行成功后并没有我们想要的数据,我们只需要在setting中设置一个请求头即可
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "guid=a314b28b83cee821d850c2f4aec4c17f; adv=adsnew%3D1%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fsp0.baidu.com%252F9q9JcDHa2gU2pMbgoY3K%252Fadrc.php%253Ft%253D06KL00c00fDewkY03lV-00uiAsjsUOkI00000F2YH7C00000Im6S0g.THLZ_Q5n1VeHksK85HcdnjDLnjc1g1uxTAT0T1dBnjRknH79uj0snhPhryDk0ZRqfYF7rj61wHmzfHT3rDfvnjn4n1IKfRDLfH04PYuAPHD0mHdL5iuVmv-b5HnzrHfdPjTvrHDhTZFEuA-b5HDv0ARqpZwYTZnlQzqYTh7Wui3dnyGEmB4WUvYEIZF9mvR8TA9s5v7bTv4dUHYznj0YnW6zFh7JTjd9i7csmY9PPbk4rgw9nd7dH-wATyczigNunW-YHjPiUbs1HhkBR1-Luys3XRdDwHwnUy6sm-ILQdG8iMuBNj7GyNI_pvwmfWmhp1Y1PhRsPHw9mH0YPH-WnhNbujNBPjIhPHIWmWmknAf3n6KWThnqn1RzPW6%2526tpl%253Dtpl_11534_20937_16032%2526l%253D1514976402%2526attach%253Dlocation%25253D%252526linkName%25253D%252525E6%252525A0%25252587%252525E5%25252587%25252586%252525E5%252525A4%252525B4%252525E9%25252583%252525A8-%252525E6%252525A0%25252587%252525E9%252525A2%25252598-%252525E4%252525B8%252525BB%252525E6%252525A0%25252587%252525E9%252525A2%25252598%252526linkText%25253D%252525E3%25252580%25252590%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A751Job%252525E3%25252580%25252591-%25252520%252525E5%252525A5%252525BD%252525E5%252525B7%252525A5%252525E4%252525BD%2525259C%252525E5%252525B0%252525BD%252525E5%2525259C%252525A8%252525E5%25252589%2525258D%252525E7%252525A8%2525258B%252525E6%25252597%252525A0%252525E5%252525BF%252525A7%2521%252526xp%25253Did%2528%25252522m3294547691_canvas%25252522%2529%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FDIV%2525255B1%2525255D%2525252FH2%2525255B1%2525255D%2525252FA%2525255B1%2525255D%252526linkType%25253D%252526checksum%25253D78%2526ie%253Dutf-8%2526f%253D8%2526tn%253D25017023_6_pg%2526wd%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526oq%253D%2525E5%252589%25258D%2525E7%2525A8%25258B%2525E6%252597%2525A0%2525E5%2525BF%2525A7%2526rqlang%253Dcn%2526lm%253D-1%2526ssl_s%253D1%2526ssl_c%253Dssl1_16f22154dbf%26%7C%26adsnum%3D2004282; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; 51job=cenglish%3D0%26%7C%26; search=jobarea%7E%60000000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FApython%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60000000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21",
"Host": "jobs.51job.com",
"Referer": "https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,1.html?",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-site",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36",
}
python scrapy爬取前程无忧招聘信息的更多相关文章
- Python爬虫学习(二) ——————爬取前程无忧招聘信息并写入excel
作为一名Pythoner,相信大家对Python的就业前景或多或少会有一些关注.索性我们就写一个爬虫去获取一些我们需要的信息,今天我们要爬取的是前程无忧!说干就干!进入到前程无忧的官网,输入关键字&q ...
- python之scrapy爬取jingdong招聘信息到mysql数据库
1.创建工程 scrapy startproject jd 2.创建项目 scrapy genspider jingdong 3.安装pymysql pip install pymysql 4.set ...
- 爬虫框架之Scrapy——爬取某招聘信息网站
案例1:爬取内容存储为一个文件 1.建立项目 C:\pythonStudy\ScrapyProject>scrapy startproject tenCent New Scrapy projec ...
- 爬取拉勾网招聘信息并使用xlwt存入Excel
xlwt 1.3.0 xlwt 文档 xlrd 1.1.0 python操作excel之xlrd 1.Python模块介绍 - xlwt ,什么是xlwt? Python语言中,写入Excel文件的扩 ...
- 网络爬虫之scrapy爬取某招聘网手机APP发布信息
1 引言 过段时间要开始找新工作了,爬取一些岗位信息来分析一下吧.目前主流的招聘网站包括前程无忧.智联.BOSS直聘.拉勾等等.有段时间时间没爬取手机APP了,这次写一个爬虫爬取前程无忧手机APP岗位 ...
- python scrapy爬取HBS 汉堡南美航运公司柜号信息
下面分享个scrapy的例子 利用scrapy爬取HBS 船公司柜号信息 1.前期准备 查询提单号下的柜号有哪些,主要是在下面的网站上,输入提单号,然后点击查询 https://www.hamburg ...
- Python爬取拉勾网招聘信息并写入Excel
这个是我想爬取的链接:http://www.lagou.com/zhaopin/Python/?labelWords=label 页面显示如下: 在Chrome浏览器中审查元素,找到对应的链接: 然后 ...
- Python——Scrapy爬取链家网站所有房源信息
用scrapy爬取链家全国以上房源分类的信息: 路径: items.py # -*- coding: utf-8 -*- # Define here the models for your scrap ...
- 简单的python爬虫--爬取Taobao淘女郎信息
最近在学Python的爬虫,顺便就练习了一下爬取淘宝上的淘女郎信息:手法简单,由于淘宝网站本上做了很多的防爬措施,应此效果不太好! 爬虫的入口:https://mm.taobao.com/json/r ...
随机推荐
- Gartner:阿里云位列全球云数据库市场份额前三,数据库未来需上云
近日,国际权威研究机构Gartner发布 <The Future of the Database Management System (DBMS) Market Is Cloud>报告,鲜 ...
- install jqdatasdk
install jqdatasdk pip3 install jqdatasdk ... 54% |█████████████████ | 3.2MB 84kB/s eta 0:0 54% |████ ...
- Alpha版本第一周作业
姓名 学号 周前计划安排 每周实际工作记录 自我打分 LTR 61213 1.撰写博客2.分配具体任务并完成个人任务 1.已完成博客撰写2.任务分配完成并继续构思实现方法 95 LHL 61212 完 ...
- part12.5-定时器去抖
- @gym - 101137K@ Knights of the Old Republic
目录 @description@ @solution@ @accepted code@ @details@ @description@ 给定 N 个点 M 条边的一张图. 每个点有两个属性 Ai, B ...
- Pytorch使用tensorboardX网络结构可视化。超详细!!!
https://www.jianshu.com/p/46eb3004beca 1 引言 我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorbo ...
- js this详解
This的定义: 它代表函数运行时,自动生成的一个内部对象,只能在函数内部使用. this的指向在函数定义的时候是确定不了的,只有函数执行的时候才能确定this到底指向谁,实际上this的最终指向的是 ...
- HZOJ 题
首先对于n<=100的点,直接暴力dp,f[i][j][k]表示时间为i,在i,j位置的方案数,枚举转移即可,期望得分40. ) { ) { f[][][]=; ;i<=n;i++) ;x ...
- 云原生生态周报 Vol. 6 | KubeCon EU 特刊
5 月 26日,2019 年第一个 KubeCon + CloudNativeCon 在巴塞罗那成功闭幕.本届 KubeCon 共吸引了超过 7700 名与会者,相较去年哥本哈根大会的 4300 余名 ...
- SuperSocket命令和命令加载器
关键字: 命令, 命令加载器, 多命令程序集 命令 (Command) SuperSocket 中的命令设计出来是为了处理来自客户端的请求的, 它在业务逻辑处理之中起到了很重要的作用. 命令类必须实现 ...