reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码
/**
* Merge the values for each key using an associative reduce function. This will also perform
* the merging locally on each mapper before sending results to a reducer, similarly to a
* "combiner" in MapReduce. Output will be hash-partitioned with the existing partitioner/
* parallelism level.
*/
def reduceByKey(func: (V, V) => V): RDD[(K, V)] = {
reduceByKey(defaultPartitioner(self), func)
} /**
* Group the values for each key in the RDD into a single sequence. Allows controlling the
* partitioning of the resulting key-value pair RDD by passing a Partitioner.
* The ordering of elements within each group is not guaranteed, and may even differ
* each time the resulting RDD is evaluated.
*
* Note: This operation may be very expensive. If you are grouping in order to perform an
* aggregation (such as a sum or average) over each key, using [[PairRDDFunctions.aggregateByKey]]
* or [[PairRDDFunctions.reduceByKey]] will provide much better performance.
*
* Note: As currently implemented, groupByKey must be able to hold all the key-value pairs for any
* key in memory. If a key has too many values, it can result in an [[OutOfMemoryError]].
*/
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = {
// groupByKey shouldn't use map side combine because map side combine does not
// reduce the amount of data shuffled and requires all map side data be inserted
// into a hash table, leading to more objects in the old gen.
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKey[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine=false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
通过源码可以发现:
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
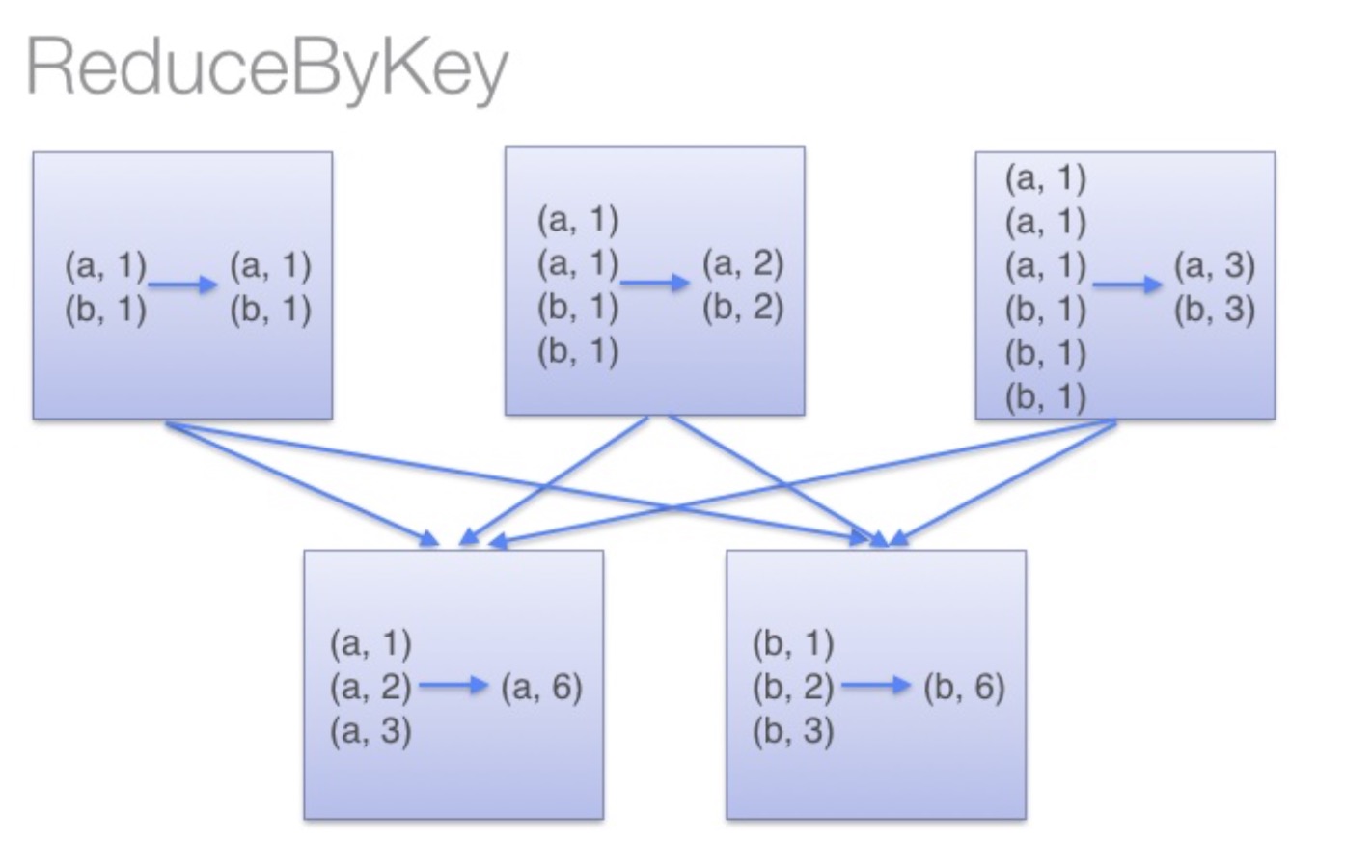
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。同时如果数据量十分大,可能还会造成OutOfMemoryError。
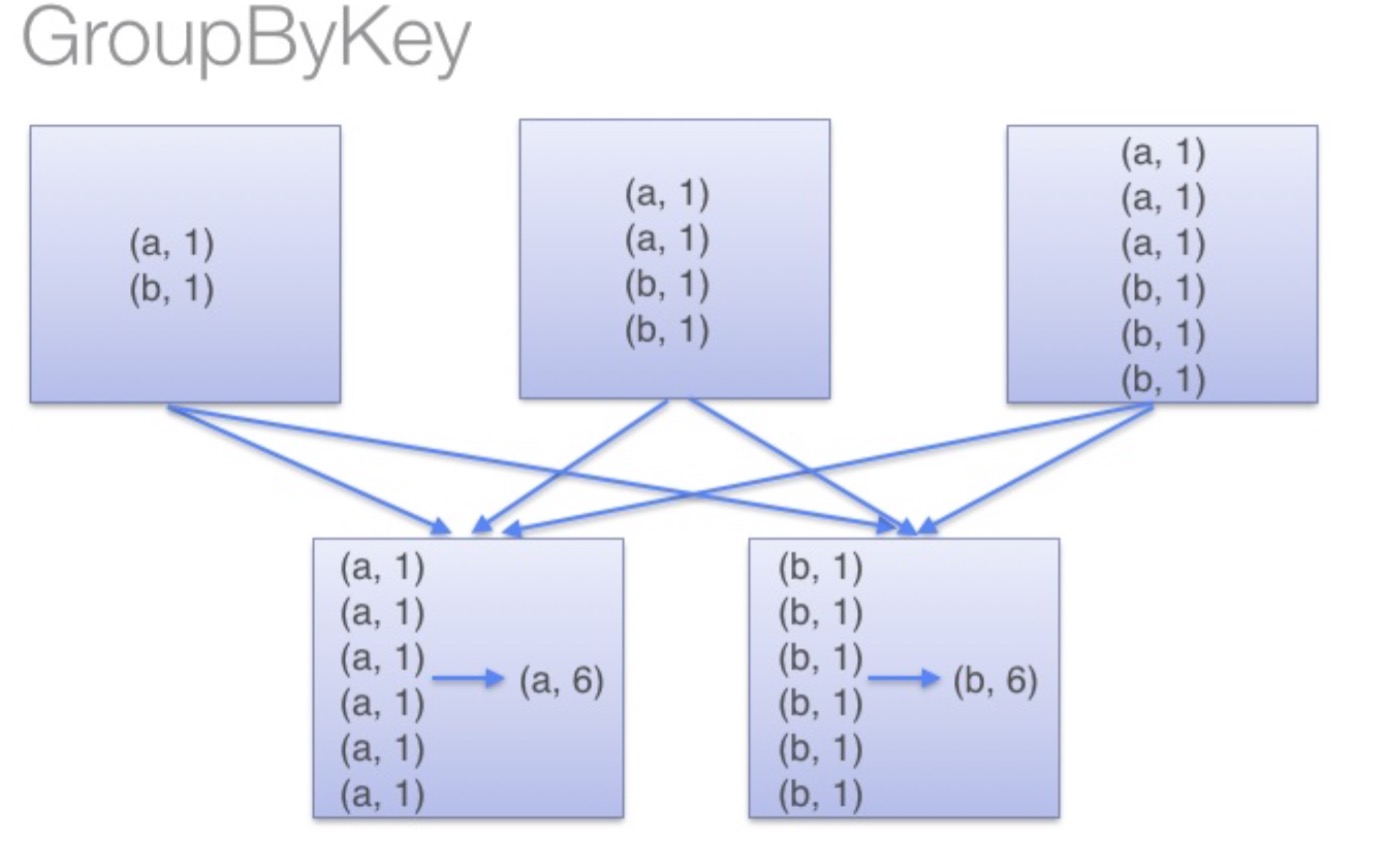
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。
reduceByKey和groupByKey的区别的更多相关文章
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- spark:reducebykey与groupbykey的区别
从源码看: reduceBykey与groupbykey: 都调用函数combineByKeyWithClassTag[V]((v: V) => v, func, func, partition ...
- reduceByKey和groupByKey区别与用法
在spark中,我们知道一切的操作都是基于RDD的.在使用中,RDD有一种非常特殊也是非常实用的format——pair RDD,即RDD的每一行是(key, value)的格式.这种格式很像Pyth ...
- 【spark】常用转换操作:reduceByKey和groupByKey
1.reduceByKey(func) 功能: 使用 func 函数合并具有相同键的值. 示例: val list = List("hadoop","spark" ...
- spark RDD,reduceByKey vs groupByKey
Spark中有两个类似的api,分别是reduceByKey和groupByKey.这两个的功能类似,但底层实现却有些不同,那么为什么要这样设计呢?我们来从源码的角度分析一下. 先看两者的调用顺序(都 ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- spark新能优化之reduceBykey和groupBykey的使用
val counts = pairs.reduceByKey(_ + _) val counts = pairs.groupByKey().map(wordCounts => (wordCoun ...
- scala flatmap、reduceByKey、groupByKey
1.test.txt文件中存放 asd sd fd gf g dkf dfd dfml dlf dff gfl pkdfp dlofkp // 创建一个Scala版本的Spark Context va ...
- 32、reduceByKey和groupByKey对比
一.groupByKey 1.图解 val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2 ...
随机推荐
- POJ 1204 Word Puzzles | AC 自动鸡
题目: 给一个字母矩阵和几个模式串,矩阵中的字符串可以有8个方向 输出每个模式串开头在矩阵中出现的坐标和这个串的方向 题解: 我们可以把模式串搞成AC自动机,然后枚举矩阵最外围一层的每个字母,向八个方 ...
- 使用org.jsoup.Jsoup下载网络中的图片
package com.enation.newtest; import java.io.BufferedOutputStream; import java.io.File; import java.i ...
- 从Jetty、Tomcat和Mina中提炼NIO构架网络服务器的经典模式
如何正确使用NIO来构架网络服务器一直是最近思考的一个问题,于是乎分析了一下Jetty.Tomcat和Mina有关NIO的源码,发现大伙都基于类似的方式,我感觉这应该算是NIO构架网络服务器的经典模式 ...
- 高级数据查询SQL语法
接上一篇关系数据库SQL之基本数据查询:子查询.分组查询.模糊查询,主要是关系型数据库基本数据查询.包括子查询.分组查询.聚合函数查询.模糊查询,本文是介绍一下关系型数据库几种高级数据查询SQL语法, ...
- linux之expr命令
expr命令可以实现数值运算.数值或字符串比较.字符串匹配.字符串提取.字符串长度计算等功能.它还具有几个特殊功能,判断变量或参数是否为整数.是否为空.是否为0等. 先看expr命令的info文档in ...
- 51Nod 1048 整数分解为2的幂 V2
题目链接 分析: $O(N)$和$O(NlogN)$的做法很简单就不写了...%了一发神奇的$O(log^3n*$高精度$)$的做法... 考虑我们只能用$2$的整次幂来划分$n$,所以我们从二进制的 ...
- Asp .Net MVC中常用过滤属性类
/// <summary> /// /// </summary> public class AjaxOnlyAttribute : ActionFilterAttribute ...
- 理想中的SQL语句条件拼接方式 (二)
问题以及想要的效果,不重复叙述,如果需要的请先看 理想中的SQL语句条件拼接方式 . 效果 现在有2个类映射数据库的2张表,结构如下: public class User { public int U ...
- Application binary interface and method of interfacing binary application program to digital computer
An application binary interface includes linkage structures for interfacing a binary application pro ...
- linux用户态定时器的使用---19【转】
转自:http://www.cnblogs.com/zxouxuewei/p/5095288.html 原创博文,转载请标明出处--周学伟http://www.cnblogs.com/zxouxuew ...