scala flatmap、reduceByKey、groupByKey
1、test.txt文件中存放
asd sd fd gf g
dkf dfd dfml dlf
dff gfl pkdfp dlofkp
// 创建一个Scala版本的Spark Context
val conf = new SparkConf().setAppName("wordCount")
val sc = new SparkContext(conf)
// 读取我们的输入数据
val input = sc.textFile(inputFile)
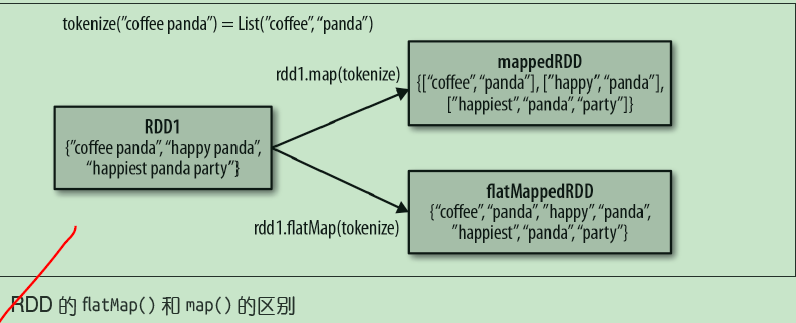
// 把它切分成一个个单词
val words = input.flatMap(line => line.split(" "))
//words为------------------
asd
sd
fd
gf
g
dkf
dfd
dfml
dlf
dff
gfl
pkdfp
dlofkp
val counts = words.map(word => (word, 1)).reduceByKey{case (x, y) => x + y}
// 将统计出来的单词总数存入一个文本文件,引发求值
counts.saveAsTextFile(outputFile)
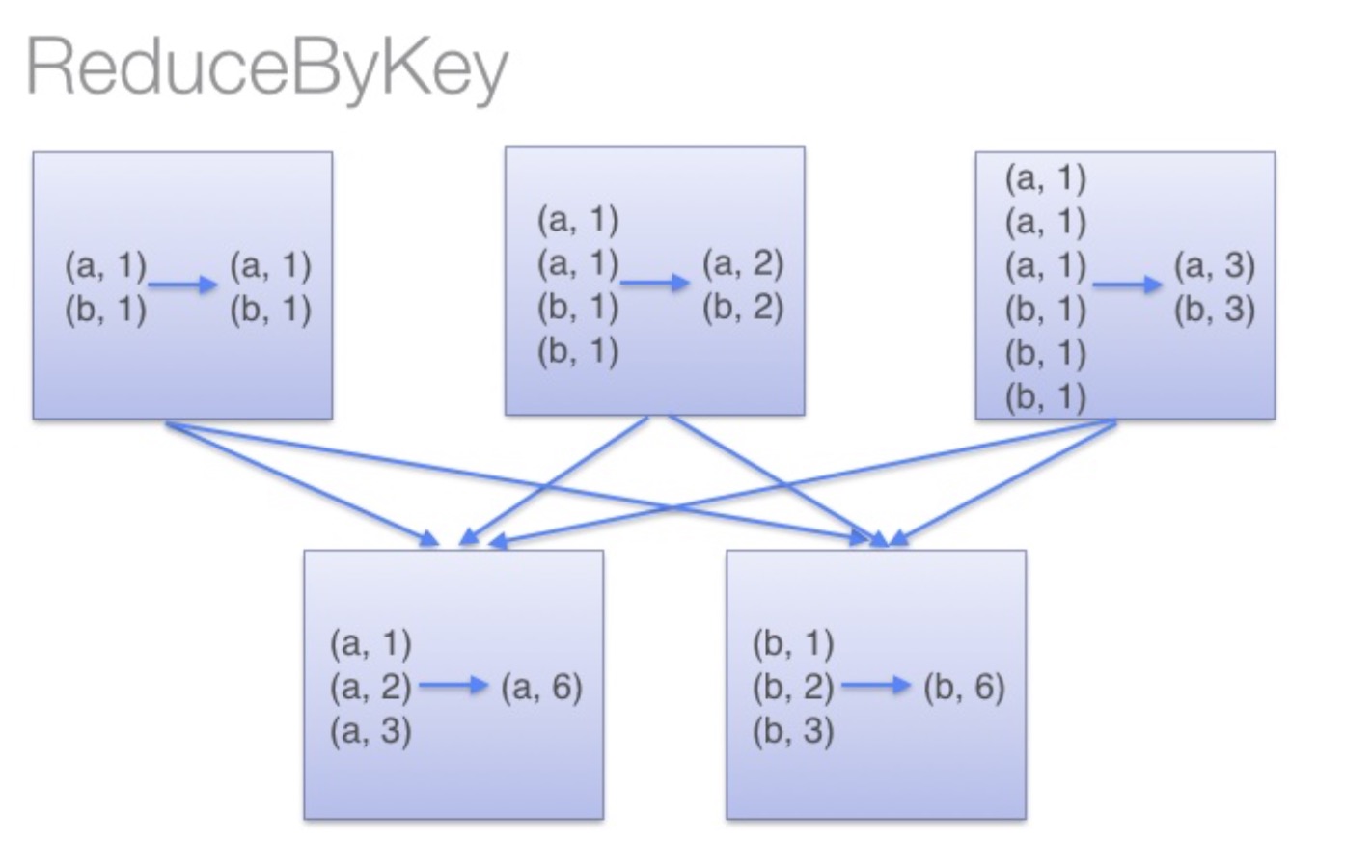
//reduceByKey 合并key计算

2、reduceByKey 合并key计算
按key求和
val rdd = sc.parallelize(List((“a”,2),(“b”,3),(“a”,3))) 合并key计算
val r1 = rdd.reduceByKey((x,y) => x + y) 输出结果如下 (a,5)
(b,3)
reduceByKey:reduceByKey会在结果发送至reducer之前会对每个mapper在本地进行merge,有点类似于在MapReduce中的combiner。
这样做的好处在于,在map端进行一次reduce之后,数据量会大幅度减小,从而减小传输,保证reduce端能够更快的进行结果计算。
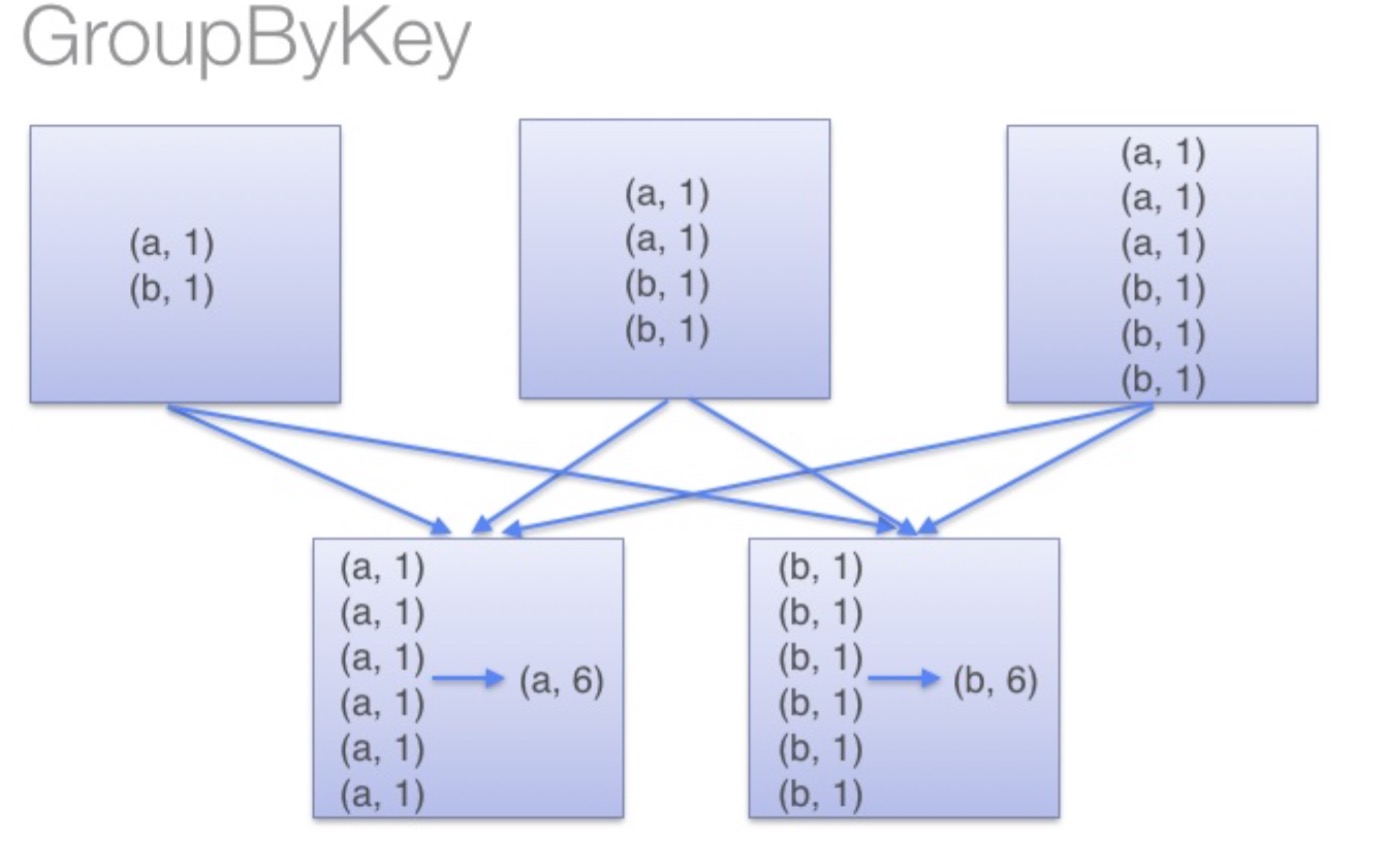
groupByKey:groupByKey会对每一个RDD中的value值进行聚合形成一个序列(Iterator),
此操作发生在reduce端,所以势必会将所有的数据通过网络进行传输,造成不必要的浪费。
同时如果数据量十分大,可能还会造成OutOfMemoryError。
通过以上对比可以发现在进行大量数据的reduce操作时候建议使用reduceByKey。
不仅可以提高速度,还是可以防止使用groupByKey造成的内存溢出问题。




scala flatmap、reduceByKey、groupByKey的更多相关文章
- Spark RDD/Core 编程 API入门系列 之rdd案例(map、filter、flatMap、groupByKey、reduceByKey、join、cogroupy等)(四)
声明: 大数据中,最重要的算子操作是:join !!! 典型的transformation和action val nums = sc.parallelize(1 to 10) //根据集合创建RDD ...
- 32、reduceByKey和groupByKey对比
一.groupByKey 1.图解 val counts = pairs.groupByKey().map(wordCounts => (wordCounts._1, wordCounts._2 ...
- Spark记录-Spark性能优化(开发、资源、数据、shuffle)
开发调优篇 原则一:避免创建重复的RDD 通常来说,我们在开发一个Spark作业时,首先是基于某个数据源(比如Hive表或HDFS文件)创建一个初始的RDD:接着对这个RDD执行某个算子操作,然后得到 ...
- spark提交命令 spark-submit 的参数 executor-memory、executor-cores、num-executors、spark.default.parallelism分析
转载:https://blog.csdn.net/zimiao552147572/article/details/96482120 nohup spark-submit --master yarn - ...
- 转载-reduceByKey和groupByKey的区别
原文链接-https://www.cnblogs.com/0xcafedaddy/p/7625358.html 先来看一下在PairRDDFunctions.scala文件中reduceByKey和g ...
- reduceByKey和groupByKey的区别
先来看一下在PairRDDFunctions.scala文件中reduceByKey和groupByKey的源码 /** * Merge the values for each key using a ...
- Spark中groupByKey、reduceByKey与sortByKey
groupByKey把相同的key的数据分组到一个集合序列当中: [("hello",1), ("world",1), ("hello",1 ...
- 【Spark算子】:reduceByKey、groupByKey和combineByKey
在spark中,reduceByKey.groupByKey和combineByKey这三种算子用的较多,结合使用过程中的体会简单总结: 我的代码实践:https://github.com/wwcom ...
- 深入理解groupByKey、reduceByKey区别——本质就是一个local machine的reduce操作
下面来看看groupByKey和reduceByKey的区别: val conf = new SparkConf().setAppName("GroupAndReduce").se ...
随机推荐
- 修改CentOS默认yum源为国内yum镜像源
CentOS默认的yum源不是国内的yum源,在通过yum安装一些软件的时候,会出现这样那样的错误,以及在下载安装的速度上也是非常慢的. 所以这个时候就需要将yum源替换成国内的yum源,国内主要开源 ...
- VMware中某个虚拟机卡死,单独关闭某个虚拟机的办法
在虚拟机中部署ceph时,其中一个虚拟机突然意外卡死,网络搜索到解决的办法,特此整理如下: 一.找到卡死虚拟机的安装目录,在安装目录下找到VMware这个文本文档 二.打开该文本文档,在文档中查找pi ...
- 11.redis_python
# pip install redis import redis # 1.链接数据库 key--value client = redis.StrictRedis(host='127.0.0.1', p ...
- 2.02-request_header_two
import urllib.request def load_baidu(): url= "http://www.baidu.com" #添加请求头的信息 #创建请求对象 requ ...
- (2)Python索引和切片
- 并发控制--Concurrency control--乐观、悲观及方法
In information technology and computer science, especially in the fields of computer programming, op ...
- 在Ubuntu18.04上使用Anaconda(python3.7)环境中安装tensorflow1.13.1
由于清华镜像源迟迟没有更新tensorflow1.13.1导致python3.7不能使用tensorflow 这里有一个解决方法 管理员模式打开(一定要管理员模式 不然会导致权限不足) 输入 pip ...
- 【转】如何使用分区助手完美迁移系统到SSD固态硬盘?
自从SSD固态硬盘出世以来,一直都被持续关注着,SSD的性能优势让无数用户起了将操作系统迁移到SSD的心思,直接后果就是让无数机械硬盘为止黯然退场,很多软件都可以做到系统迁移,然而,被完美迁移的系统却 ...
- springboot--bean交给容器
1.把bean交给springboot管理 springboot也是一个spring容器.把一个bean交给springboot的容器有三种方法,前两种是先把bean交给spring容器再把sprin ...
- AppCan10个超实用的APP必备插件,让你少敲80%代码
一个APP的需求来自于哪儿?产品.老板.客户….. 做程序员不容易,需求一句话,就是几千几万行代码!所幸,在AppCan平台开发APP,开发者只需完成应用的前端部分,至于各项复杂的功能,就交给AppC ...