【读书笔记】2_增强学习中的Q-Learning
本文为Thomas Simonini增强学习系列文章笔记或读后感,原文可以直接跳转到medium系列文章。
主要概念为:
Q-Learning,探讨其概念以及用Numpy实现
我们可以将二维游戏想象成平面格子,每个格子代表一个状态,并且对应了不同的动作,例如下图:
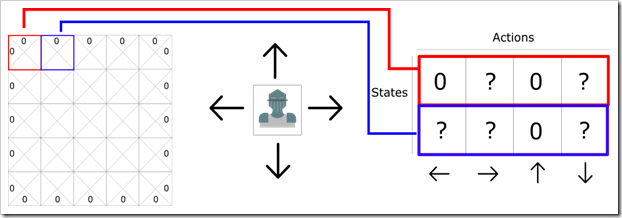
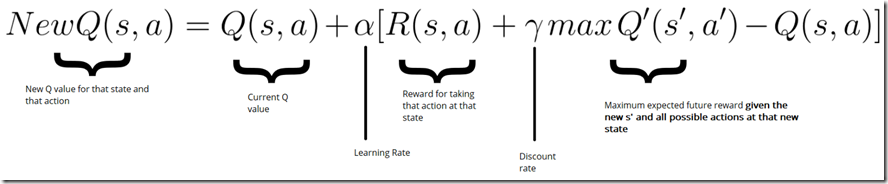
Q函数接收状态和动作两个参数并输出Q值,即在一个状态下各种动作各自未来的期望奖励。公式如下:

这里的未来期望奖励,就是当前状态下一直到结束状态(成功或失败)所获取的奖励。
Q-learning算法伪代码:

其中,更新Q值为bellman等式,如下描述:
这篇文章总体来说,非常简单,各种步骤也特别详细,告诉了我们如何计算Q-table的算法过程。但是为什么能迭代到最优,并没有给出一个比较明确的证明过程。主要也是因为采用的EE平衡问题,这个过程采用了greedy episolon的启发式算法,每次直接选取的是最大概率的action,而多次重复episode, 其实计算的是对未来的奖励积累的期望。所以从bellman等式到Q(s, a) state-value function 定义如何连接的呢?推导的公式如下:

Numpy具体实现
# -*- coding: utf-8 -*- # pkg need
import numpy as np
import gym
import random
import time # step 1. create the environment
env = gym.make("Taxi-v2")
env.render() # tick and run it to see # this game enviroment could be found detail documented at:
# https://gym.openai.com/envs/#toy_text
# pick and drop off the passenger right for -20 points,
# fail for either one will lose 10 points
# every step will decrease 1 points # step 2. create the q-table and initialize it.
state_size = env.observation_space.n
action_size = env.action_space.n
qtable = np.zeros((state_size, action_size))
print("state size: %d, action size: %d" % qtable.shape) # tick and run # step 3. create the hyperparameters
total_episodes = 50000
total_test_episodes = 100
max_steps = 99 learning_rate = 0.7
gamma = 0.618 # exploration parameter
epsilon = 1.0 # exploration rate
max_epsilon = 1.0 # exploration probability at start
min_epsilon = 0.01 # minumum exploration probability
decay_rate = 0.01 # exponential rate to decay exploration rate # step 4. The Q learning algorithm
# 2 For life or until learning is stopped
for episode in range(total_episodes):
# reset the environment
state = env.reset()
step = 0
done = False # start the game
for step in range(max_steps):
# 3 choose an action a in the current world state (s)
# first random a number
ee_tradeoff = random.uniform(0, 1) # exploitation, taking the biggest Q value for this state
if ee_tradeoff > epsilon:
action = np.argmax(qtable[state, :])
else:
action = env.action_space.sample() # exploration, randomly sample a action # take action and observe the outcome
new_state, reward, done, info = env.step(action) # Update the Q(s, a)
qtable[state, action] += learning_rate * (
reward + gamma * np.max(qtable[new_state, :]) - qtable[state, action]) # update state
state = new_state # if done: finish episode
if done:
break # reduce epsilon -> we want less and less exploration
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode) print(qtable) # use q table to play taxi def play(env, qtable, show=True, sec=None):
state = env.reset()
step = 0
done = False
total_rewards = 0 for step in range(max_steps):
# see agent to play
if show:
env.render()
action = np.argmax(qtable[state, :]) new_state, reward, done, info = env.step(action)
total_rewards += reward if done:
break if sec:
time.sleep(sec) state = new_state
return total_rewards # play one test episode
play(env, qtable) env.reset()
rewards = []
for episode in range(total_test_episodes):
total_rewards = play(env, qtable, show=False)
rewards.append(total_rewards) env.close()
print("Score over time: " + str(sum(rewards) / total_test_episodes))
参考文献:
1. bellman equation to state value function,berkeley的增强学习课程,讲的真详细。
【读书笔记】2_增强学习中的Q-Learning的更多相关文章
- 【Deep Learning读书笔记】深度学习中的概率论
本文首发自公众号:RAIS,期待你的关注. 前言 本系列文章为 <Deep Learning> 读书笔记,可以参看原书一起阅读,效果更佳. 概率论 机器学习中,往往需要大量处理不确定量,或 ...
- 剑指offer学习读书笔记--二维数组中的查找
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都是按照从上到下递增的顺序排序.请设计一个函数,输入这样的一个二维数组和一个整数,判断数组是否含有这个整数. 1 2 8 9 2 4 9 1 ...
- 错误内存【读书笔记】C程序中常见的内存操作有关的典型编程错误
题记:写这篇博客要主是加深自己对错误内存的认识和总结实现算法时的一些验经和训教,如果有错误请指出,万分感谢. 对C/C++程序员来讲,内存管理是个不小的挑战,绝对值得慎之又慎,否则让由上万行代码构成的 ...
- 《EM-PLANT仿真技术教程》读书笔记(持续更新中)
1.在系统分析过程中,必须考虑系统所处的环境,因此划分系统与环境的边界是系统分析的首要任务 2.模型可以分为物理模型和数学模型.数学模型可以分为解析模型.逻辑模型.网络模型以及仿真模型.模型可以分为离 ...
- linq读书笔记2-查询内存中的对象
上次我们说到了linq对数组内容的检索,自.net2.0以后,泛型成了很常见的一种应用技术,linq对泛型的检索也提供了完善的支持 如对list类型的支持,范例如下: class Program ...
- [读书笔记] 四、SpringBoot中使用JPA 进行快速CRUD操作
通过Spring提供的JPA Hibernate实现,进行快速CRUD操作的一个栗子~. 视图用到了SpringBoot推荐的thymeleaf来解析,数据库使用的Mysql,代码详细我会贴在下面文章 ...
- [读书笔记] Spring MVC 学习指南 -- 第一章
控制反转(Inversion of Control, IoC)/ 依赖注入: 比如说,类A依赖于类B,A需要调用B的某一个方法,那么在调用之前,类A必须先获得B的一个示例引用. 通常我们可以在A中写代 ...
- 剑指Offer读书笔记(持续更新中)
(1)定义一个空的类型,里面没有不论什么成员变量和成员函数,对该类型求sizeof,得到的结果是多少? 答案是1.空类型的实例中不包括不论什么信息,本来求sizeof应该是0,可是当我们声明该类型实例 ...
- 【读书笔记】iOS-属性中的内存管理参数
一,assign 代表设置时候直接赋值,而不是复制或者保留它. 二,retain. 会在赋值的时候把新值保留.此属性只能用于Object-C对象类型. 三,copy 在赋值时,将新值复制一份,复制工作 ...
随机推荐
- 【题解】洛谷P1002过河卒
首先,一道入门DP 然而对于蒟蒻的我已经难到爆了好吗 第一点:动态转移方程 用DP的关键! 这题我们可以发现每一步的方案数由上面的那步加上左边的那步得到 所以自然而然的方程就出来了: f[i][k]= ...
- 【题解】洛谷 P1525 关押罪犯
题目 https://www.luogu.org/problemnew/show/P1525 思路 把所有边sort一遍从大到小排列 运用并查集思想敌人的敌人就是朋友 从最大边开始查找连着的两个罪犯 ...
- AngularJS 表格(带有CSS样式)
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- python核心编程2 第十五章 练习
15-1.识别下列字符串 :“bat ”.“bit ”.“but ”.“hat ”.“hit” 或 “hut ” import re from random import choice strtupl ...
- 图片懒加载 jquery.lazyload
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- 迷你MyBank
该迷你MyBank,存贮是用对象数组来存贮的,所以比较简单,容易理解,适合新手.. 一.创建chengyuan类,在其中声明所需的成员变量: public class chengyuan { //该类 ...
- SSM框架理解搭建(虽然是网上拼的,但是实际按照搭建是可以的)——
SpringSpring就像是整个项目中装配bean的大工厂,在配置文件中可以指定使用特定的参数去调用实体类的构造方法来实例化对象.Spring的核心思想是IoC(控制反转),即不再需要程序员去显式地 ...
- grafana使用Prometheus数据源监控mongo数据库
数据库改用mongo后,监控需求就需要整合进grafana里,由于一直在坚持docker化部署,那么此次也不例外. 1. 安装Prometheus: What is Prometheus? Prome ...
- php柱状图多系列动态实现
<?php require_once 'data.php'; require_once 'jpgraph/src/jpgraph.php'; require_once"jpgraph/ ...
- 微信小程序关于tabbar点击切换数据不刷新问题
微信小程序中经常遇到的需求就是我提交了一个表单或者进行了一个操作,需要在我的个人中心页面中实时显示出来,但是小程序中的tabbar切换类似于tab切换 并不会进行页面刷新请求 所以总是会造成一些数据更 ...