python简单爬豆瓣电影排名
爬豆瓣电影
网站分析:
1 打开https://movie.douban.com,选择 【排行榜】,然后随便选择一类型,我这里选择科幻
2 一直浏览网页,发现没有下一的标签,是下滑再加载的,可以判定使用了 ajax 请求,进行异步的加载

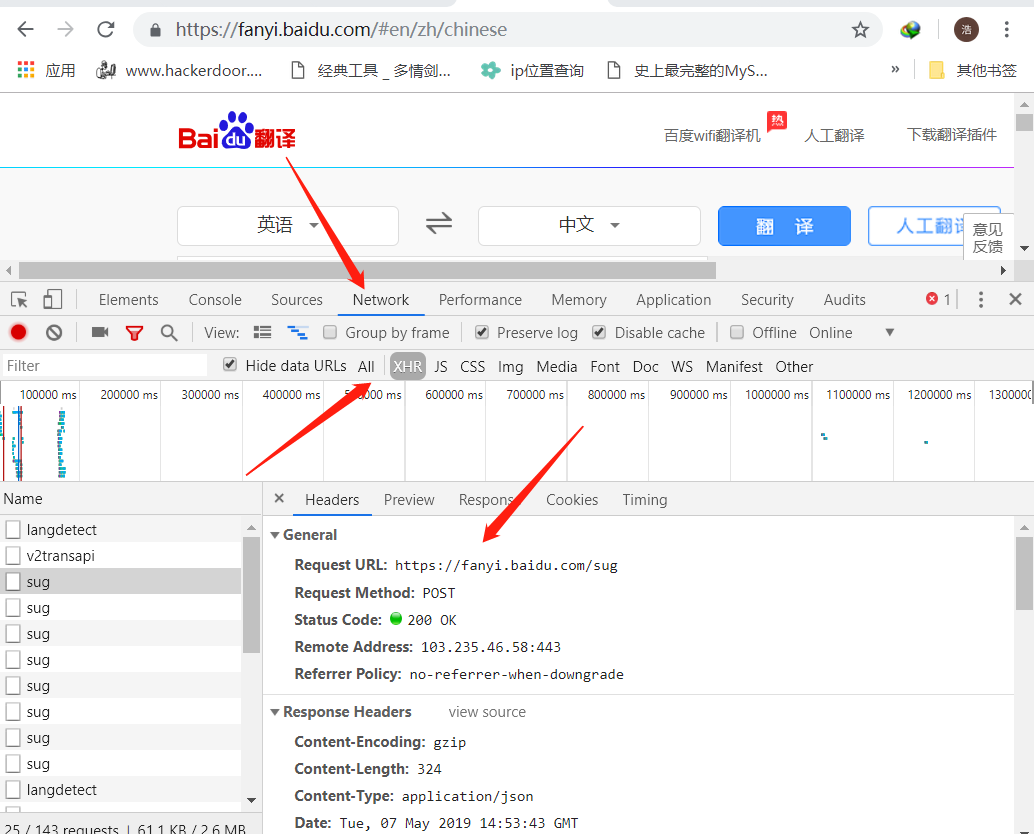
检查请求信息:
1.右键【检查】>【Network】
2 找url
简单实现代码
from urllib import request
import json
import time headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36"}
# url 信息:interval_id 表示排名段 可修改 ,limit 限制20个,就是每页请求多少个
url = "https://movie.douban.com/j/chart/top_list?type=17&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
data = rsp.read().decode() data = json.loads(data) print(data)
运行效果
优化输出格式,代码
from urllib import request
import json url = "https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&start=20&limit=20" rsp = request.urlopen(url)
data = rsp.read().decode() data = json.loads(data) #遍历输出每个'k'和‘v’的值
for item in data:
print("排名:", item['rank'],"\n",
"名称:",item['title'],"\n",
"类型:",item['types'],"\n",
"主演:",item['actors'],"\n",
"国家:",item['regions'],"\n",
"分数:",item['score'],"\n",
"图片:",item['cover_url'],"\n---------------")
优化效果

好了,这样的效果,看起来更顺眼了
python简单爬豆瓣电影排名的更多相关文章
- Python:python抓取豆瓣电影top250
一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧. 实现目标:抓取豆瓣电影top250,并输出到文件中 1.找到对应的url:https://movie.douba ...
- Python抓取豆瓣电影top250!
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理.作者:404notfound 一直对爬虫感兴趣,学了python后正好看到 ...
- Scala学习之爬豆瓣电影
简单使用Scala和Jsoup对豆瓣电影进行爬虫,技术比較简单易学. 写文章不易,欢迎大家採我的文章,以及给出实用的评论,当然大家也能够关注一下我的github:多谢. 1.爬虫前期准备 找好须要抓取 ...
- 2_爬豆瓣电影_ajax动态加载
爬豆瓣 什么是 AJAX ? AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. AJAX = Asynchronous JavaScript and XML(AJAX = 异步 ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- python爬虫--用xpath爬豆瓣电影
步骤 将目标网站下的页面抓取下来 将抓取下来的数据根据一定规则进行提取 具体流程 将目标网站下的页面抓取下来 1. 倒库 import requests 2.头信息(有时候可不写) headers ...
- 一、python简单爬取静态网页
一.简单爬虫框架 简单爬虫框架由四个部分组成:URL管理器.网页下载器.网页解析器.调度器,还有应用这一部分,应用主要是NLP配合相关业务. 它的基本逻辑是这样的:给定一个要访问的URL,获取这个ht ...
- python 简单爬取今日头条热点新闻(一)
今日头条如今在自媒体领域算是比较强大的存在,今天就带大家利用python爬去今日头条的热点新闻,理论上是可以做到无限爬取的: 在浏览器中打开今日头条的链接,选中左侧的热点,在浏览器开发者模式netwo ...
- Python简单爬取图书信息及入库
课堂上老师布置了一个作业,如下图所示: 就是简单写一个借书系统. 大概想了一下流程,登录-->验证登录信息-->登录成功跳转借书界面-->可查看自己的借阅书籍以及数量... 登录可以 ...
随机推荐
- pycharm同时使用python2.7和python3.5设置方法
pycharm同时使用python2.7和python3.5设置方法 - CSDN博客https://blog.csdn.net/qwerty200696/article/details/530159 ...
- POJ-2752-Seek the Name-kmp的变形
The little cat is so famous, that many couples tramp over hill and dale to Byteland, and asked the l ...
- Redis Cluste部署
一.原生搭建篇Cluster了解cluster的架构 Redis-cluster是使用的是一致性哈希算法来切分数据存储,总计16383个槽,分成16383/N(redis节点)个分区,存取时将key转 ...
- CSS三大特性之优先级顺序
id选择器>类选择器>标签选择器>通配符>继承>浏览器默认
- wpf 几种常用控件样式
转自:http://blog.csdn.net/xuejiren/article/details/39449515
- Echarts——更改仪表盘方向和颜色
做小项目需要用到仪表盘,官方给出的颜色设置如下: 而我想要如下样式的: 最后,经过一番折腾算是搞成了如下样式效果: 要达到上面效果关键在于设置Echarts的如下两处js代码: 1.大小值要颠倒,因为 ...
- 2、docker镜像管理
Docker镜像管理 镜像是Docker容器的基础,想运行一个Docker容器就需要有镜像.我们上面已经学会了使用search搜索镜像.那么这个镜像是怎么创建的呢? 创建镜像 镜像的创建有以下几种方法 ...
- [JZOJ2702] 【GDKOI2012模拟02.01】探险
题目 题目大意 给你一个每条边正反权值不一定相同的无向图,求起点为111点的最小环. 思考历程 一看到这题,就觉得是一个经典模型. 然后思考先前做过最小环的经历,发现没个卵用. 我突然想到,既然这一个 ...
- Ionic3 demo TallyBook 实例2
1.添加插件 2.相关页面 消费页面: <ion-header> <ion-navbar> <ion-title> 消费记录 </ion-title> ...
- 12DUILib经典教程(实例)
Duilib经典实例教程:1基本框架:一个简单的Duilib程序一般是下面这个样子的:://Duilib使用设置部分:#pragmaonce:#defineWIN32_LEAN_AND_ME:#def ...