Hadoop HDFS NameNode工作机制
Secondary namenode
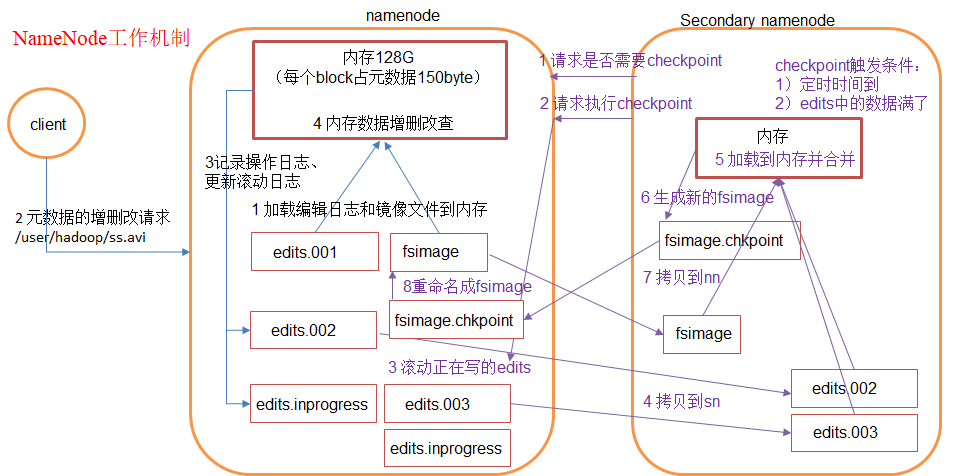
首先,我们假设如果存储在Namenode节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断点,元数据丢失,整个集群就无法工作了!!!因此必须在磁盘中有备份,在磁盘中的备份就是fsImage,存放在Namenode节点对应的磁盘中。当在内存中的元数据更新时,如果同时更新fsImage镜像文件(文件的随机读写),会导致效率过低,但如果不更新,就会发生一致性问题,一旦Namenode节点断电,就会产生数据丢失。因此,引入操作日志文件edits.log(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到edits.log中。这样,一旦Namenode节点断电,可以通过镜像
文件fsImage和edits.log的合并,合成元数据。但是,如果长时间添加数据到edit.log中,会导致该文件数据过大,效率降低且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行fsImage和edits.log的合并,如果这个操作由Namenode节点完成,又会效率过低。因此,引入一个新的secondaryNamenode,专门用于fsImage和edits.log的合并。





chkpoint检查时间参数设置
(1)通常情况下,SecondaryNameNode每隔一小时执行一次。
[core-site.xml]
|
<property> <name>dfs.namenode.checkpoint.period</name> <value>3600</value> </property> |
(2)一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
|
<property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description>操作动作次数</description> </property> <property> <name>dfs.namenode.checkpoint.period</name> <value>60</value> <description> 1分钟检查一次操作次数</description> </property> |
元数据目录分析
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
|
$HADOOP_HOME/bin/hdfs namenode -format |
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
current/ |-- VERSION |-- edits_* |-- fsimage_0000000000008547077 |-- fsimage_0000000000008547077.md5 `-- seen_txid |
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
<property> <name>dfs.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value>
</property> hadoop.tmp.dir是在core-site.xml中配置的,默认值如下 <property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value>
<description>A base for other temporary directories.</description> </property> |
dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
1、VERSION文件是Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013 namespaceID=934548976 clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196 cTime=0 storageType=NAME_NODE blockpoolID=BP-893790215-192.168.24.72-1383809616115 layoutVersion=-47 |
其中
(1)、namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)、storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)、cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)、layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)、clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a、使用如下命令格式化一个Namenode:
$HADOOP_HOME/bin/hdfs
namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b、使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format
-clusterId <cluster_id>
c、升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs
start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId
<cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
(6)、blockpoolID:是针对每一个Namespace所对应的blockpool的ID,上面的这个BP-893790215-192.168.24.72-1383809616115就是在我的ns1的namespace下的存储块池的ID,这个ID包括了其对应的NameNode节点的ip地址。
2、$dfs.namenode.name.dir/current/seen_txid非常重要,是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits

hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-2.7.2/edits.xml
hdfs oev -p XML -i edits_0000000000000000001-0000000000000000002 -o /mnt/hgfs/linuxsharefile/edits_test_3.xml
hdfs oev -p XML -i edits_0000000000000000003-0000000000000000015 -o /mnt/hgfs/linuxsharefile/edits_test_4.xml
hdfs oev -p XML -i edits_0000000000000000003-0000000000000000016 -o /mnt/hgfs/linuxsharefile/edits_test_11.xml
hdfs oev -p XML -i edits_inprogress_0000000000000000017 -o /mnt/hgfs/linuxsharefile/edits_inprogress_10.xml
fsimage_0000000000000000017

hdfs oiv -p XML -i fsimage_0000000000000000017 -o /mnt/hgfs/linuxsharefile/fsimage_1.xml
hdfs oiv -p XML -i fsimage_0000000000000000002 -o /mnt/hgfs/linuxsharefile/fsimage_1.xml
hdfs oiv -p XML -i fsimage_0000000000000000016 -o /mnt/hgfs/linuxsharefile/fsimage_1.xml
hdfs oiv -p XML -i fsimage_0000000000000000002 -o fsimage_1.xml
fsimage_0000000000000000002
Hadoop HDFS NameNode工作机制的更多相关文章
- HDFS中NameNode和Secondary NameNode工作机制
NameNode工作机制 0)启动概述 Namenode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作.一旦在内存中成功建立文件系统元数据的映像,则创建一个 ...
- NameNode&Secondary NameNode 工作机制
NameNode&Secondary NameNode 工作机制 NameNode: 1.启动时,加载编辑日志和镜像文件到内存 2.当客户端对元数据进行增删改,请求NameNode 3.Nam ...
- 图文详解 HDFS 的工作机制及其原理
大家好,我是大D. 今天开始给大家分享关于大数据入门技术栈--Hadoop的学习内容. 初识 Hadoop 为了解决大数据中海量数据的存储与计算问题,Hadoop 提供了一套分布式系统基础架构,核心内 ...
- Hadoop系列009-NameNode工作机制
本人微信公众号,欢迎扫码关注! NameNode工作机制 1 NameNode & SecondaryNameNode工作机制 1.1 第一阶段:namenode启动 1)第一次启动namen ...
- NameNode && Secondary NameNode工作机制
NameNode && Secondary NameNode工作机制 1)工作流程 2) fsimage和edits NameNode是HDFS的大脑,它维护着整个文件系统的目录树, ...
- NameNode工作机制
NameNode工作机制
- Hadoop框架:NameNode工作机制详解
本文源码:GitHub·点这里 || GitEE·点这里 一.存储机制 1.基础描述 NameNode运行时元数据需要存放在内存中,同时在磁盘中备份元数据的fsImage,当元数据有更新或者添加元数据 ...
- HDFS中NameNode工作机制
引言 NameNode: 存储元数据 管理整个HDFS集群 DataNode: 存储数据的block SecondaryNameNode: 辅助HDFS完成一些事情 NameNode和Secondar ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
随机推荐
- SQL拼接大法
SQL拼接大法: Step1:括号先写上() Step2:在括号内写上(, , , , , ,) Step3:再写上单引号(,' ' ...
- CSS3一个酷炫的加载效果
上效果图,用截屏工具制作的,看起来有点卡,在网页上面显示还是不错的. CSS代码: <style type="text/css"> .loader{ position: ...
- 【Python】多进程-共享变量(Value、string、list、Array、dict)
#练习:未使用共享变量 from multiprocessing import Process def f(n, a): n = 3.1415927 for i in range(len(a)): a ...
- 【Python】多进程2
#练习:测试单进程和多进程执行效率 import multiprocessing import time def m1(x): time.sleep(0.01) return x * x if __n ...
- ANDROID BINDER机制浅析
Binder是Android上一种IPC机制,重要且较难理解.由于Linux上标准IPC在灵活和可靠性存在一定不足,Google基于OpenBinder的设计和构想实现了Binder. 本文只简单介绍 ...
- day 020 常用模块02
主要内容: 什么是序列化 pickle shelve json configparser(模块) 一 序列化 我们在存储数据或者网络传输数据的时候,需要对我们的对象进行处理,把对象处理成方便存储和 传 ...
- HDU 4642 Fliping game (简单博弈)
Fliping game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Tota ...
- qduoj LC的课后辅导
描述 有一天,LC给我们出了一道题,如图: 这个图形从左到右由若干个 宽为1 高不确定 的小矩形构成,求出这个图形所包含的最大矩形面积. 输入 多组测试数据每组测试数据的第一行为n(0 <= n ...
- (18)模型层 -ORM之msql 多表操作(字段的属性)
数据库表的对应关系 1.一对一 #关联字段写在那张表都可以 PS:只要写OneToOneField就会自动加一个id 2.一对多 #关系确立,关联字段写在多的一方 3.多对多 #多对多的关系 ...
- PS学习之动态表情制作
准备素材 1. 2. 3. 4. 最后效果图: 在PS中打开四个图片 另外新建一个文件 用魔棒工具抠图 点击白色位置 右键选择反向 右键人物 选择拷贝的图层 重复,将四个图片扣好 拖到新建的文件里 如 ...