利用requestes\pyquery\BeautifulSoup爬取某租房公寓(深圳市)4755条租房信息及总结
为了分析深圳市所有长租、短租公寓的信息,爬取了某租房公寓深圳区域所有在租公寓信息,以下记录了爬取过程以及爬取过程中遇到的问题:
爬取代码:
1 import requests
2 from requests.exceptions import RequestException
3 from pyquery import PyQuery as pq
4 from bs4 import BeautifulSoup
5 import pymongo
6 from config import *
7 from multiprocessing import Pool
8
9 client = pymongo.MongoClient(MONGO_URL) # 申明连接对象
10 db = client[MONGO_DB] # 申明数据库
11
12 def get_one_page_html(url): # 获取网站每一页的html
13 headers = {
14 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/85.0.4183.121 Safari/537.36"
16 }
17 try:
18 response = requests.get(url, headers=headers)
19 if response.status_code == 200:
20 return response.text
21 else:
22 return None
23 except RequestException:
24 return None
25
26
27 def get_room_url(html): # 获取当前页面上所有room_info的url
28 doc = pq(html)
29 room_urls = doc('.r_lbx .r_lbx_cen .r_lbx_cena a').items()
30 return room_urls
31
32
33 def parser_room_page(room_html):
34 soup = BeautifulSoup(room_html, 'lxml')
35 title = soup.h1.text
36 price = soup.find('div', {'class': 'room-price-sale'}).text[:-3]
37 x = soup.find_all('div', {'class': 'room-list'})
38 area = x[0].text[7:-11] # 面积
39 bianhao = x[1].text[4:]
40 house_type = x[2].text.strip()[3:7] # 户型
41 floor = x[5].text[4:-2] # 楼层
42 location1 = x[6].find_all('a')[0].text # 分区
43 location2 = x[6].find_all('a')[1].text
44 location3 = x[6].find_all('a')[2].text
45 subway = x[7].text[4:]
46 addition = soup.find_all('div', {'class': 'room-title'})[0].text
47 yield {
48 'title': title,
49 'price': price,
50 'area': area,
51 'bianhao': bianhao,
52 'house_type': house_type,
53 'floor': floor,
54 'location1': location1,
55 'location2': location2,
56 'location3': location3,
57 'subway': subway,
58 'addition': addition
59 }
60
61
62 def save_to_mongo(result):
63 if db[MONGO_TABLE].insert_one(result):
64 print('存储到mongodb成功', result)
65 return True
66 return False
67
68
69 def main(page):
70 url = 'http://www.xxxxx.com/room/sz?page=' + str(page) # url就不粘啦,嘻嘻
71 html = get_one_page_html(url)
72 room_urls = get_room_url(html)
73 for room_url in room_urls:
74 room_url_href = room_url.attr('href')
75 room_html = get_one_page_html(room_url_href)
76 if room_html is None: # 非常重要,否则room_html为None时会报错
77 pass
78 else:
79 results = parser_room_page(room_html)
80 for result in results:
81 save_to_mongo(result)
82
83 if __name__ == '__main__':
84 pool = Pool() # 使用多进程提高爬取效率
85 pool.map(main, [i for i in range(1, 258)])
在写爬取代码过程中遇到了两个问题:
(一)在get_room_url(html)函数中,开始是想直接return每个租房信息的room_url,但是return不同于print,函数运行到return时就会结束该函数,这样就只能返回每页第一个租房room_url。解决办法是:return 包含每页所有room_url的generator生成器,在main函数中用for循环遍历,再从每个room_url中获取href,传入到get_one_page_html(room_url_href)中进行解析。
(二)没有写第76行的if语句,我默认get_one_page_html(room_url_href)返回的room_html不为空,因此出现multiprocessing.pool.RemoteTraceback报错:
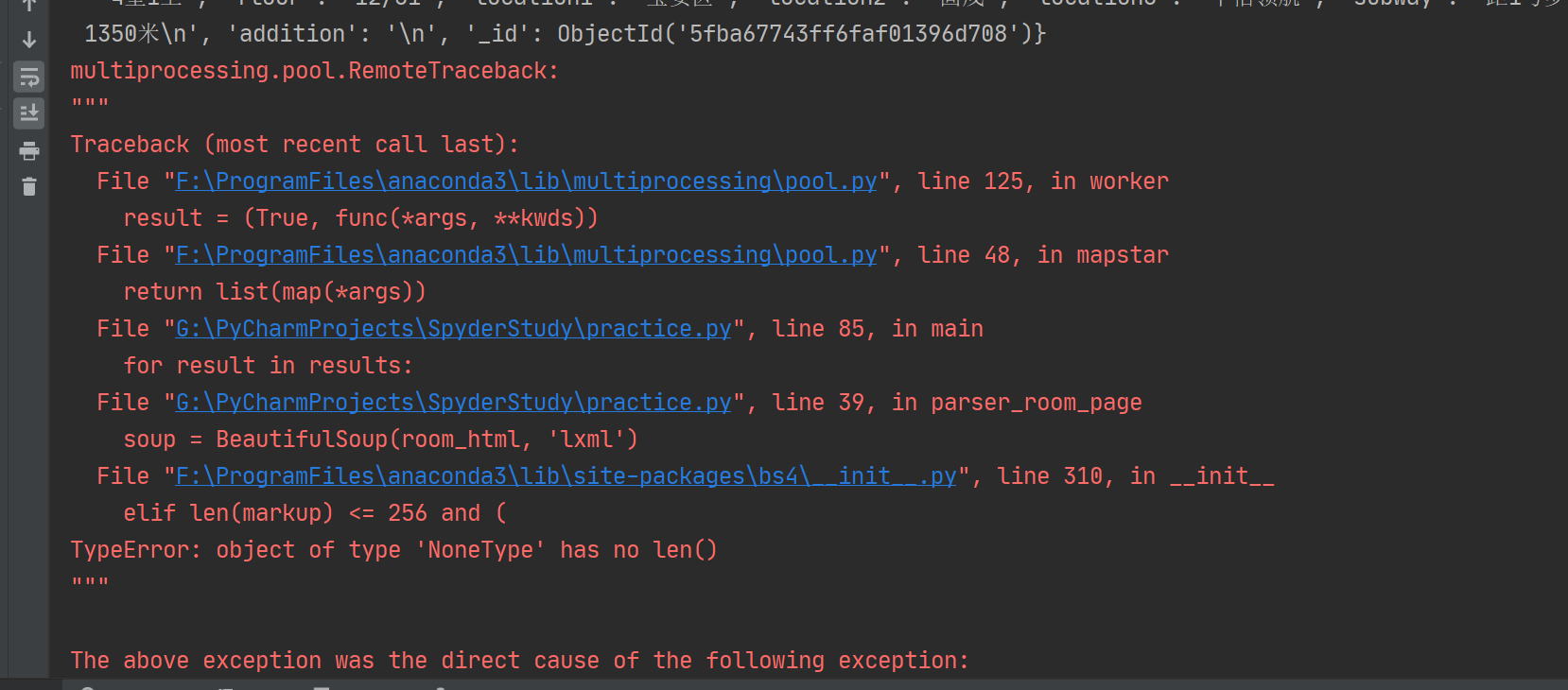
上图中显示markup为None情况下报错,点击蓝色"F:\ProgramFiles\anaconda3\lib\site-packages\bs4\__init__.py"发现markup为room_html,即部分room_html出现None情况。要解决这个问题,必须让代码跳过room_html is None的情况,因此添加 if 语句解决了这个问题。
最终成功爬取某租房公寓深圳市258页共4755条租房信息,为下一步进行数据分析做准备。
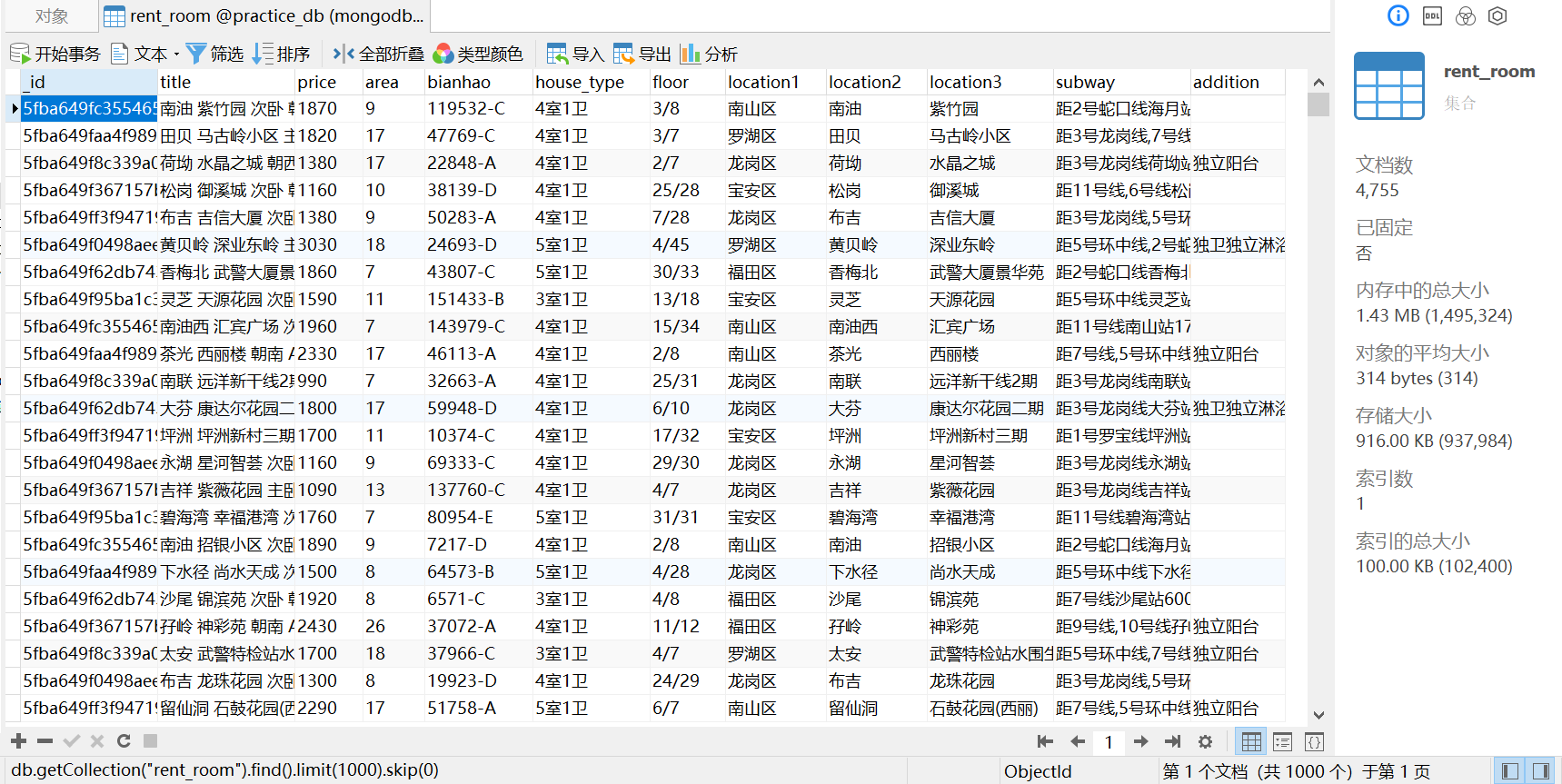
其中单条信息:

利用requestes\pyquery\BeautifulSoup爬取某租房公寓(深圳市)4755条租房信息及总结的更多相关文章
- PYTHON 爬虫笔记九:利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集(实战项目二)
利用Ajax+正则表达式+BeautifulSoup爬取今日头条街拍图集 目标站点分析 今日头条这类的网站制作,从数据形式,CSS样式都是通过数据接口的样式来决定的,所以它的抓取方法和其他网页的抓取方 ...
- python爬虫:利用BeautifulSoup爬取链家深圳二手房首页的详细信息
1.问题描述: 爬取链家深圳二手房的详细信息,并将爬取的数据存储到Excel表 2.思路分析: 发送请求--获取数据--解析数据--存储数据 1.目标网址:https://sz.lianjia.com ...
- 利用requests和BeautifulSoup爬取菜鸟教程的代码与图片并保存为markdown格式
还是设计模式的开卷考试,我想要多准备一点资料,于是写了个爬虫爬取代码与图片,有巧妙地进行格式化进一步处理,最终变为了markdown的格式 import requests from bs4 impor ...
- Python爬虫之利用BeautifulSoup爬取豆瓣小说(三)——将小说信息写入文件
#-*-coding:utf-8-*- import urllib2 from bs4 import BeautifulSoup class dbxs: def __init__(self): sel ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- 利用Python网络爬虫爬取学校官网十条标题
利用Python网络爬虫爬取学校官网十条标题 案例代码: # __author : "J" # date : 2018-03-06 # 导入需要用到的库文件 import urll ...
- # [爬虫Demo] pyquery+csv爬取猫眼电影top100
目录 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 代码君 [爬虫Demo] pyquery+csv爬取猫眼电影top100 站点分析 https://maoyan.co ...
- Python使用urllib,urllib3,requests库+beautifulsoup爬取网页
Python使用urllib/urllib3/requests库+beautifulsoup爬取网页 urllib urllib3 requests 笔者在爬取时遇到的问题 1.结果不全 2.'抓取失 ...
- python爬虫:爬取链家深圳全部二手房的详细信息
1.问题描述: 爬取链家深圳全部二手房的详细信息,并将爬取的数据存储到CSV文件中 2.思路分析: (1)目标网址:https://sz.lianjia.com/ershoufang/ (2)代码结构 ...
随机推荐
- php生成器 yield 转
一.yield介绍 文档介绍说道:生成器函数的核心是yield关键字.它最简单的调用形式看起来像一个return申明,不同之处在于普通return会返回值并终止函数的执行,而yield会返回一个值给 ...
- selenium基础--环境搭建
下载地址 Chrome点击下载chrome的webdriver: http://chromedriver.storage.googleapis.com/index.html不同的Chrome的版本对应 ...
- T-sql语句,group by 加 order by的使用方法
select AuHousesID,sum(Turnover) from Auction group by AuHousesID order by sum(Turnover) desc
- 【荐】JavaScript图片放大技术(放大镜)示例代码
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- js 日期格式、内容合法、比较大小、表单提交验证
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"/> 5 &l ...
- win7下安装docker
为了支持老版本的windows系统,docker官方提供了docker toolbox,让用户可以在windows10以前版本的操作系统上来体验docker. 一,安装 下载msi安装文件,一路nex ...
- 【0】TensorFlow光速入门-序
本文地址:https://www.cnblogs.com/tujia/p/13863181.html 序言: 对于我这么一个技术渣渣来说,想学习TensorFlow机器学习,实在是太难了: 百度&qu ...
- IDEA上运行Flink任务
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- nacos 作为配置中心使用心得--配置使用
1.页面配置 撇开原理不谈,先来介绍下nacos的基本使用,如下图nacos配置是以data id为单位进行使用的,基本上一个服务的一个配置文件就对应一个data id,支持的格式有xml,yaml, ...
- NB-IoT的eDRX模式主要目的是什么
传统的2.56秒寻呼间隔对UE的电量消耗较大,NB-IoT的eDRX模式主要目的就是支能够持更长周期的寻呼监听,从而达到省电的目的.而在下行数据发送频率小时,通过核心网和用户终端的协商配合,用户终端调 ...