新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述
Spark 是一个用来实现快速而通用的集群计算的平台。
在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理。 在处理大规模数据集时,速度是非常重要的。速度快就意味着我们可以进行交互式的数据操作, 否则我们每次操作就需要等待数分钟甚至数小时。
Spark 的一个主要特点就是能够在内存中进行计算, 因而更快。不过即使是必须在磁盘上进行的复杂计算, Spark 依然比 MapReduce 更加高效。
2.Spark生态系统
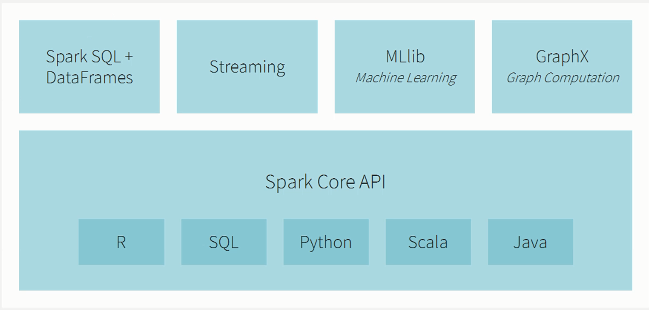
3.Spark学网站
1)databricks 网站
2)spark 官网
3)github 网站
4.Spark2.x源码下载及编译生成版本
1)Spark2.2源码下载到bigdata-pro02.kfk.com节点的/opt/softwares/目录下。
解压
tar -zxf spark-2.2.0.tgz -C /opt/modules/
2)spark2.2编译所需要的环境:Maven3.3.9和Java8
3)Spark源码编译的方式:Maven编译、SBT编译(暂无)和打包编译make-distribution.sh
a)下载Jdk8并安装
tar -zxf jdk8u11-linux-x64.tar.gz -C /opt/modules/
b)JAVA_HOME配置/etc/profile
vi /etc/profile
export JAVA_HOME=/opt/modules/jdk1.8.0_11
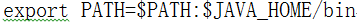
编辑退出之后,使之生效
source /etc/profile
c)如果遇到不能加载当前版本的问题
rpm -qa|grep jdk
rpm -e --nodeps jdk版本
which java 删除/usr/bin/java
d)下载并解压Maven
下载Maven
解压maven
tar -zxf apache-maven-3.3.9-bin.tar.gz -C /opt/modules/
配置MAVEN_HOME
vi /etc/profile
export MAVEN_HOME=/opt/modules/apache-maven-3.3.9
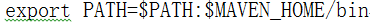
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=1024M -XX:ReservedCodeCacheSize=1024M"
编辑退出之后,使之生效
source /etc/profile
查看maven版本
mvn -version
e)编辑make-distribution.sh内容,可以让编译速度更快
VERSION=2.2.0
SCALA_VERSION=2.11.8
SPARK_HADOOP_VERSION=2.5.0
#支持spark on hive
SPARK_HIVE=1
4)通过make-distribution.sh源码编译spark
./dev/make-distribution.sh --name custom-spark --tgz -Phadoop-2.5 -Phive -Phive-thriftserver -Pyarn
#编译完成之后解压
tar -zxf spark-2.2.0-bin-custom-spark.tgz -C /opt/modules/
5.scala安装及环境变量设置
1)下载
2)解压
tar -zxf scala-2.11.8.tgz -C /opt/modules/
3)配置环境变量
vi /etc/profile
export SCALA_HOME=/opt/modules/scala-2.11.8
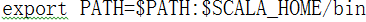
4)编辑退出之后,使之生效
source /etc/profile
6.spark2.0本地模式运行测试
1)启动spark-shell测试
./bin/spark-shell
scala> val textFile = spark.read.textFile("README.md")
textFile: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.count()
res0: Long = 126
scala> textFile.first()
res1: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line => line.contains("Spark"))
linesWithSpark: org.apache.spark.sql.Dataset[String] = [value: string]
scala> textFile.filter(line => line.contains("Spark")).count() // How many lines contain "Spark"?
res3: Long = 15
2)词频统计
a)创建一个本地文件stu.txt
vi /opt/datas/stu.txt
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es
solr dajiangtai scala
linux java scala
python spark mlib
kafka spark mysql
spark es scala
azkaban oozie mysql
storm storm storm
scala mysql es
spark spark spark
b)spark-shell 词频统计
./bin/spark-shell
scala> val rdd = spark.read.textFile("/opt/datas/stu.txt")
#词频统计
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).collect
#对词频进行排序
scala> val lines = rdd.flatmap(x => x.split(" ")).map(x => (x,1)).rdd.reduceBykey((a,b) => (a+b)).map(x =>(x._2,x._1)).sortBykey().map(x => (x._2,x._1)).collect
7.spark 服务web监控页面
通过web页面查看spark服务情况
bigdata-pro01.kfk.com:4040
新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用.目前越来越多的开源分布式处理系统如Cloudera.Apache Storm.Spa ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——21、大数据Web可视化分析系统开发
1.基于业务需求的WEB系统设计 2.下载Tomcat并创建Web工程并配置相关服务 下载tomcat,解压并启动tomcat服务. 1)新建web app项目 创建好之后的效果 2)对tomcat进 ...
- 新闻网大数据实时分析可视化系统项目——15、基于IDEA环境下的Spark2.X程序开发
1.Windows开发环境配置与安装 下载IDEA并安装,可以百度一下免费文档. 2.IDEA Maven工程创建与配置 1)配置maven 2)新建Project项目 3)选择maven骨架 4)创 ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
随机推荐
- python应用-pycharm新建模板默认添加shebang编码作者时间等信息
1.pycharm4.5激活码 用户名: yueting3527 注册码: ===== LICENSE BEGIN ===== 93347-12042010 00001FMHemWIs"6w ...
- Manjaro 与 Windows 双系统时间相差8小时
Manjaro 与 Windows 双系统时间相差8小时 产生原因: Windows 将本地硬件时间作为设定时区(如 UTC+8)的区时,而 Linux 默认将其作为 UTC 时间. 解决方式: 让 ...
- 实现简单HttpServer案例
<html> <head> <title>第一个表单</title> </head> <body> <pre> me ...
- linux与python3安装redis
1.linux安装redis服务 apt-get install redis* 进入客户端管理 redis-cli 启动服务 service redis startservice redis rest ...
- POJ3268 Silver Cow Party (建反图跑两遍Dij)
One cow from each of N farms (1 ≤ N ≤ 1000) conveniently numbered 1..N is going to attend the big co ...
- 一个简单的PHP文件下载方法 download
<?php /* * *@param function downloadFile 文件下载 * *@param string $filename 下载文件的路径(根目录下的绝对路径) * *@p ...
- 关于热部署Devtools出现同一个类型进行类型转换失败的问题
背景: 最近在和学长们做一个小系统,在进行任务调度的设置的时候会出现类型转换失败的错误,原本是同一个类型的,不应该出现类型转换失败的问题,起初以为是序列化的问题,回来发现并不是这个原因, 报错截图: ...
- idea 构建maven web项目
参考:https://blog.csdn.net/czc9309/article/details/80304074 idea Tomcat 部署 war和war exploded的区别 参考: ht ...
- 8个问题全面了解5G关键技术Massive MIMO
1 什么是Massive MIMO Massive MIMO(大规模天线技术,亦称为Large Scale MIMO)是第五代移动通信(5G)中提高系统容量和频谱利用率的关键技术.它最早由美国贝尔实验 ...
- Codeforces 601A:The Two Routes 宽搜最短路径
A. The Two Routes time limit per test 2 seconds memory limit per test 256 megabytes input standard i ...