[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息
一、介绍
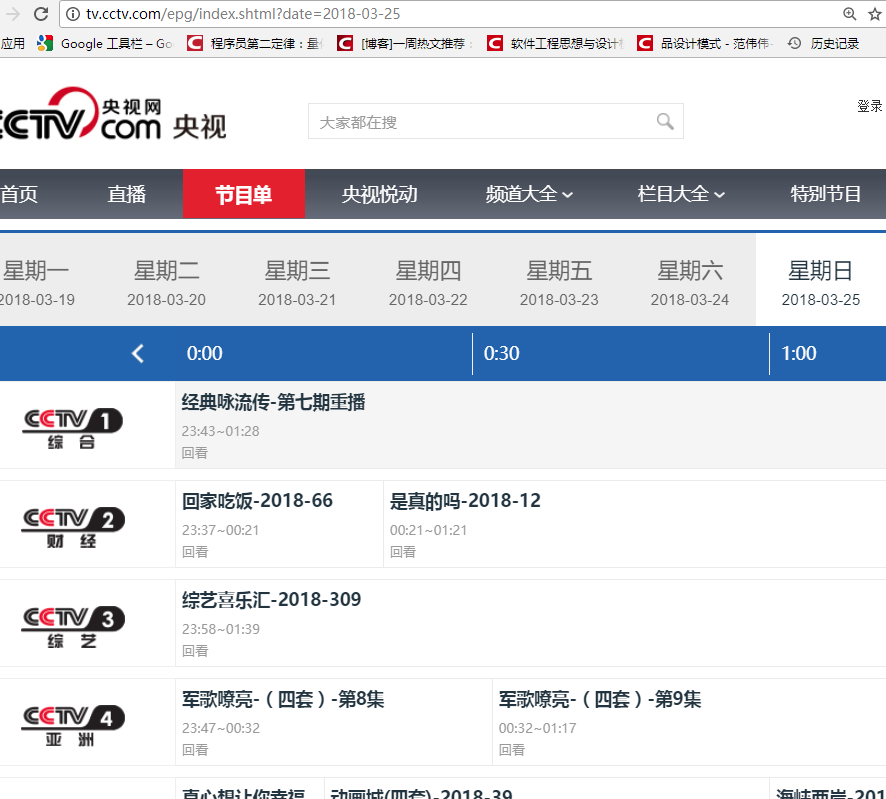
本例子用Selenium +phantomjs爬取节目(http://tv.cctv.com/epg/index.shtml?date=2018-03-25)的信息
二、网站信息
三、数据抓取
针对上面的网站信息,来进行抓取
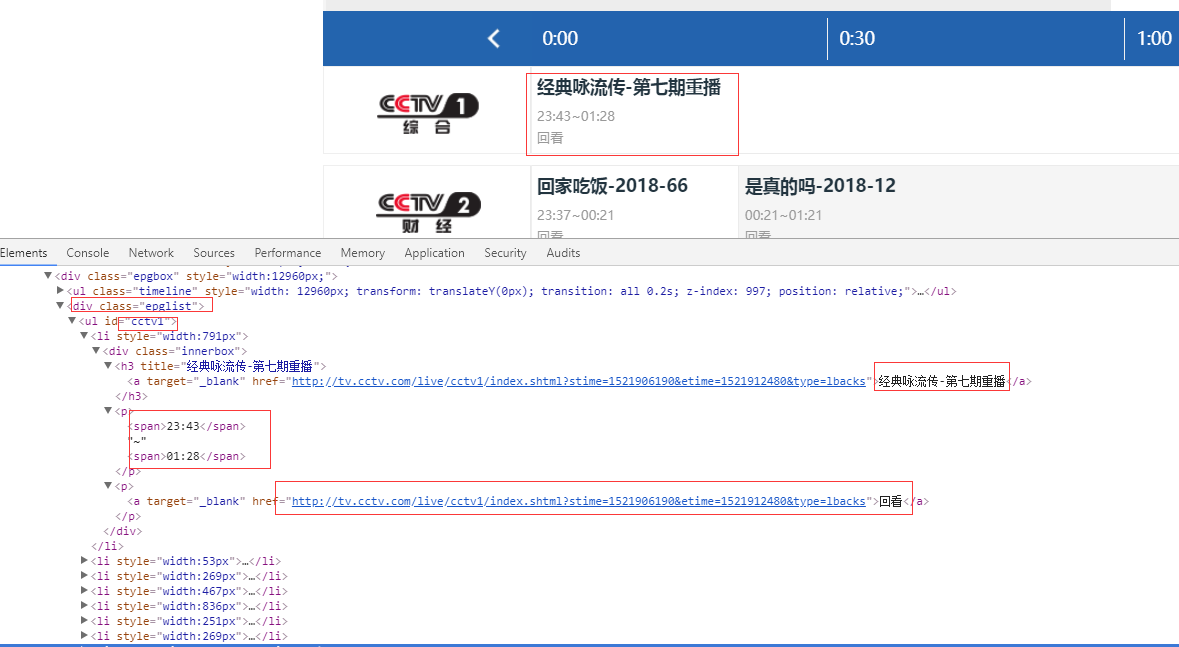
1、首先抓取信息列表
抓取代码:Elements = doc('div[class="epglist"]').find('ul')
2、节目名称,链接,时间
title = subEle('div[class="innerbox"]').find('h3').text().encode('utf8')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8')
四,实现代码
# coding=utf-8
import os
import re
from selenium import webdriver
from datetime import datetime,timedelta
import selenium.webdriver.support.ui as ui
import time
from pyquery import PyQuery as pq
class cctvDriver: def __init__(self,startDate,endDate):
#通过配置文件获取IEDriverServer.exe路径
self.urls = self.getUrlsFromStartEndDate(startDate,endDate)
IEDriverServer ='C:\Program Files\Internet Explorer\IEDriverServer.exe'
self.driver = webdriver.Ie(IEDriverServer)
self.driver.maximize_window()
self.fileName = time.strftime('%Y-%m-%d') def compareDate(self, startDate, endDate):
start_Date = time.strptime(startDate, "%Y-%m-%d")
end_Date = time.strptime(endDate, "%Y-%m-%d")
totalSeconds = (end_Date - start_Date).total_seconds()
if totalSeconds >= 0:
print endDate
return True
else:
print startDate
return False def compareTime(self, startTime, endTime):
st = int(startTime.replace(':',""))
et = int(endTime.replace(':',""))
if st>et:
return True
else:
return False def getUrlsFromStartEndDate(self,startDate,endDate): urls = []
start_Date = datetime.strptime(startDate, "%Y-%m-%d")
end_date = datetime.strptime(endDate, "%Y-%m-%d")
ts = end_date-start_Date days = ts.days + 1
index = 0
for d in xrange(0,days):
date = start_Date + timedelta(days=index)
urls.append('http://tv.cctv.com/epg/index.shtml?date='+date.strftime("%Y-%m-%d"))
index += 1
return urls def WriteLog(self, message,date):
fileName = os.path.join(os.getcwd(), 'cctvInfo/'+date + '.txt')
with open(fileName, 'a') as f:
f.write(message) def CatchData(self):
className = "//div[@class='epglist']/ul"
for url in self.urls:
date = url.split('=')[1]
start_Date = datetime.strptime(date, "%Y-%m-%d") + timedelta(days=-1)
predate = start_Date.strftime("%Y-%m-%d")
self.driver.get(url)
time.sleep(5)
selenium_html = self.driver.execute_script("return document.documentElement.outerHTML")
doc = pq(selenium_html)
Elements = doc('div[class="epglist"]').find('ul')
message = ''
recount = 0
for element in Elements.items():
channel = element.attr('id')
subElements = element.find("li") for subEle in subElements.items():
strTime = subEle('div[class="innerbox"]').find('p').text().encode('utf8').strip().replace(
'回看', '').replace('直播','')
if strTime:
title = subEle('div[class="innerbox"]').find('h3').text().encode(
'utf8').strip().replace(
',', ',')
link = subEle('div[class="innerbox"]').find('p').find('a').attr('href')
if self.compareTime(strTime.split('~')[0],strTime.split('~')[1]):
starttime = predate + " " + strTime.split('~')[0]
else:
starttime = date + " " + strTime.split('~')[0]
endtime = date + " " + strTime.split('~')[1] mess = '\r\n{0},{1},{2},{3},{4}'.format(channel, title, starttime, endtime, link)
# print mess
message += mess
recount+=1
if len(message)>10:
self.WriteLog(message.strip(),date)
print recount
self.driver.close()
self.driver.quit() # #测试抓取微博数据
obj = cctvDriver('2018-01-01','2018-03-01')
obj.CatchData()
[Python爬虫] 之二十九:Selenium +phantomjs 利用 pyquery抓取节目信息信息的更多相关文章
- [Python爬虫] 之二十七:Selenium +phantomjs 利用 pyquery抓取今日头条视频
一.介绍 本例子用Selenium +phantomjs爬取今天头条视频(http://www.tvhome.com/news/)的信息,输入给定关键字抓取图片信息. 给定关键字:视频:融合:电视 二 ...
- [Python爬虫] 之二十三:Selenium +phantomjs 利用 pyquery抓取智能电视网数据
一.介绍 本例子用Selenium +phantomjs爬取智能电视网(http://news.znds.com/article/news/)的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字 ...
- [Python爬虫] 之二十一:Selenium +phantomjs 利用 pyquery抓取36氪网站数据
一.介绍 本例子用Selenium +phantomjs爬取36氪网站(http://36kr.com/search/articles/电视?page=1)的资讯信息,输入给定关键字抓取资讯信息. 给 ...
- [Python爬虫] 之二十:Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据
一.介绍 本例子用Selenium +phantomjs 利用 pyquery通过搜狗搜索引擎数据()的资讯信息,输入给定关键字抓取资讯信息. 给定关键字:数字:融合:电视 抓取信息内如下: 1.资讯 ...
- [Python爬虫] 之二十八:Selenium +phantomjs 利用 pyquery抓取网站排名信息
一.介绍 本例子用Selenium +phantomjs爬取中文网站总排名(http://top.chinaz.com/all/index.html,http://top.chinaz.com/han ...
- [Python爬虫] 之三十:Selenium +phantomjs 利用 pyquery抓取栏目
一.介绍 本例子用Selenium +phantomjs爬取栏目(http://tv.cctv.com/lm/)的信息 二.网站信息 三.数据抓取 首先抓取所有要抓取网页链接,共39页,保存到数据库里 ...
- [Python爬虫] 之三十一:Selenium +phantomjs 利用 pyquery抓取消费主张信息
一.介绍 本例子用Selenium +phantomjs爬取央视栏目(http://search.cctv.com/search.php?qtext=消费主张&type=video)的信息(标 ...
- [Python爬虫] 之二十六:Selenium +phantomjs 利用 pyquery抓取智能电视网站图片信息
一.介绍 本例子用Selenium +phantomjs爬取智能电视网站(http://www.tvhome.com/news/)的资讯信息,输入给定关键字抓取图片信息. 给定关键字:数字:融合:电视 ...
- [Python爬虫] 之二十五:Selenium +phantomjs 利用 pyquery抓取今日头条网数据
一.介绍 本例子用Selenium +phantomjs爬取今日头条(http://www.toutiao.com/search/?keyword=电视)的资讯信息,输入给定关键字抓取资讯信息. 给定 ...
随机推荐
- MSSQL为单独数据库创建登录账户
如果要为一个数据库创建一个独立的账号需要这个数据库为包含数据库 当前(非包含)的数据库所面临的问题在描述什么是包含数据库之前,先了解一下为什么会出现包含数据库.当前的数据库有一些问题,如下:1.在数据 ...
- hdu 5576 dp
题目大意:给你一个长度为 n 的 字符串表示一个乘法,一次操作随机选两个字符进行交换,进行m次操作,让你求出所有可能操作 的答案和. (1 <= n, m <= 50) 思路:巨难.. ...
- 35.Spark系统运行内幕机制循环流程
一:TaskScheduler原理解密 1, DAGScheduler在提交TaskSet给底层调度器的时候是面向接口TaskScheduler的,这符合面向对象中依赖抽象而不依赖的原则,带来底层资 ...
- lamp字符编码的转换规则
1.lamp字符编码的转换规则 lamp(Linux+Apache+Mysql+PHP) 1.1GB 2312 GB 2312 或 GB 2312-80 是中国国家标准简体中文字符集,全称<信息 ...
- 用jquery实现文章自动生成二级目录(续)
前文:用jquery实现文章自动生成二级目录. 使用方法的补充 我们可以把我们的js和css上传到博客园,然后在页面HTML代码中使用他们. 发现的一些问题 在我把我的js放到自己的博客园上运行之后发 ...
- org.hibernate.HibernateException: Could not obtain transaction-synchronized Session for current thread
spring与hibernate整合报错 org.hibernate.HibernateException: Could not obtain transaction-synchronized Ses ...
- 洛谷——P1292 倒酒
P1292 倒酒 题目描述 Winy是一家酒吧的老板,他的酒吧提供两种体积的啤酒,a ml和b ml,分别使用容积为a ml和b ml的酒杯来装载. 酒吧的生意并不好.Winy发现酒鬼们都非常穷.有时 ...
- linux的bash和shell关系
shell通俗理解:把用户输入的命令翻译给操作系统. shell 是一个交互性命令解释器.shell独立于操作系统,这种设计让用户可以灵活选择适合自己的shell.shell让你在命令行键入命令,经过 ...
- 【HDU 5730】Shell Necklace
http://acm.hdu.edu.cn/showproblem.php?pid=5730 分治FFT模板. DP:\(f(i)=\sum\limits_{j=0}^{i-1}f(j)\times ...
- hdu 4825(Trie)
Xor Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 132768/132768 K (Java/Others)Total S ...