Python爬虫从入门到放弃(二十)之 Scrapy分布式原理
关于Scrapy工作流程回顾
Scrapy单机架构
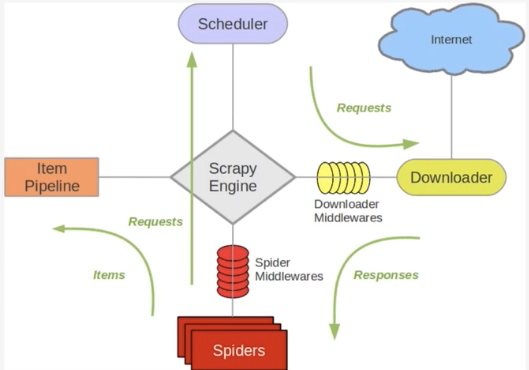
上图的架构其实就是一种单机架构,只在本机维护一个爬取队列,Scheduler进行调度,而要实现多态服务器共同爬取数据关键就是共享爬取队列。
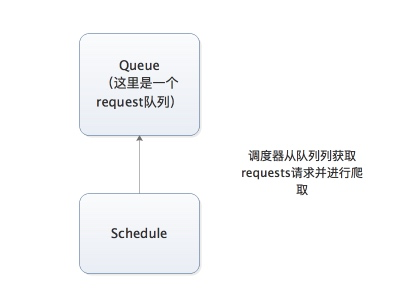
分布式架构
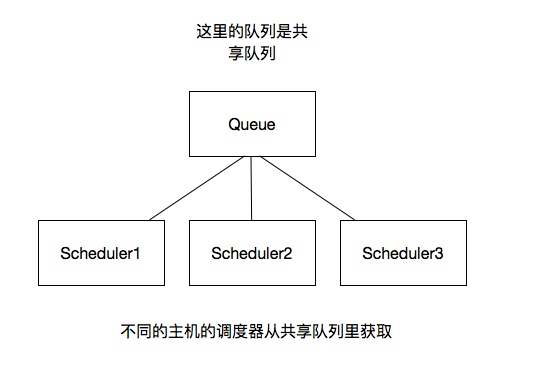
我将上图进行再次更改
这里重要的就是我的队列通过什么维护?
这里一般我们通过Redis为维护,Redis,非关系型数据库,Key-Value形式存储,结构灵活。
并且redis是内存中的数据结构存储系统,处理速度快,提供队列集合等多种存储结构,方便队列维护
如何去重?
这里借助redis的集合,redis提供集合数据结构,在redis集合中存储每个request的指纹
在向request队列中加入Request前先验证这个Request的指纹是否已经加入集合中。如果已经存在则不添加到request队列中,如果不存在,则将request加入到队列并将指纹加入集合
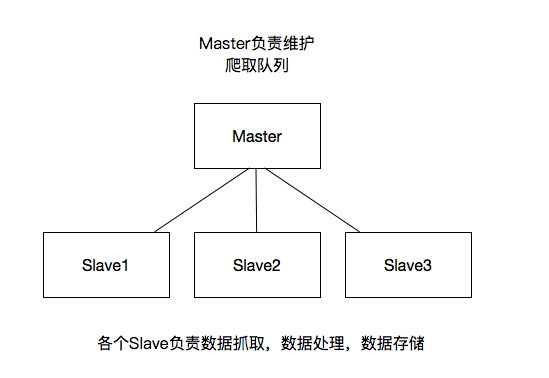
如何防止中断?如果某个slave因为特殊原因宕机,如何解决?
这里是做了启动判断,在每台slave的Scrapy启动的时候都会判断当前redis request队列是否为空
如果不为空,则从队列中获取下一个request执行爬取。如果为空则重新开始爬取,第一台丛集执行爬取向队列中添加request
如何实现上述这种架构?
这里有一个scrapy-redis的库,为我们提供了上述的这些功能
scrapy-redis改写了Scrapy的调度器,队列等组件,利用他可以方便的实现Scrapy分布式架构
关于scrapy-redis的地址:https://github.com/rmax/scrapy-redis
搭建分布式爬虫
参考官网地址:https://scrapy-redis.readthedocs.io/en/stable/
前提是要安装scrapy_redis模块:pip install scrapy_redis
这里的爬虫代码是用的之前写过的爬取知乎用户信息的爬虫
修改该settings中的配置信息:
替换scrapy调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
添加去重的class
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
添加pipeline
如果添加这行配置,每次爬取的数据也都会入到redis数据库中,所以一般这里不做这个配置
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
共享的爬取队列,这里用需要redis的连接信息
这里的user:pass表示用户名和密码,如果没有则为空就可以
REDIS_URL = 'redis://user:pass@hostname:9001'
设置为为True则不会清空redis里的dupefilter和requests队列
这样设置后指纹和请求队列则会一直保存在redis数据库中,默认为False,一般不进行设置
SCHEDULER_PERSIST = True
设置重启爬虫时是否清空爬取队列
这样每次重启爬虫都会清空指纹和请求队列,一般设置为False
SCHEDULER_FLUSH_ON_START=True
分布式
将上述更改后的代码拷贝的各个服务器,当然关于数据库这里可以在每个服务器上都安装数据,也可以共用一个数据,我这里方面是连接的同一个mongodb数据库,当然各个服务器上也不能忘记:
所有的服务器都要安装scrapy,scrapy_redis,pymongo
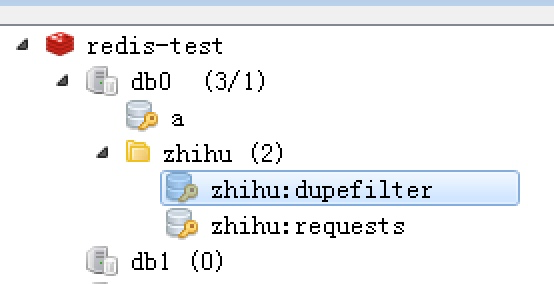
这样运行各个爬虫程序启动后,在redis数据库就可以看到如下内容,dupefilter是指纹队列,requests是请求队列
Python爬虫从入门到放弃(二十)之 Scrapy分布式原理的更多相关文章
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- Python爬虫从入门到放弃(十九)之 Scrapy爬取所有知乎用户信息(下)
在上一篇文章中主要写了关于爬虫过程的分析,下面是代码的实现,完整代码在:https://github.com/pythonsite/spider items中的代码主要是我们要爬取的字段的定义 cla ...
- Python爬虫从入门到放弃(十)之 关于深度优先和广度优先
网站的树结构 深度优先算法和实现 广度优先算法和实现 网站的树结构 通过伯乐在线网站为例子: 并且我们通过访问伯乐在线也是可以发现,我们从任何一个子页面其实都是可以返回到首页,所以当我们爬取页面的数据 ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python爬虫从入门到放弃(十六)之 Scrapy框架中Item Pipeline用法
当Item 在Spider中被收集之后,就会被传递到Item Pipeline中进行处理 每个item pipeline组件是实现了简单的方法的python类,负责接收到item并通过它执行一些行为, ...
- Python爬虫从入门到放弃(十八)之 Scrapy爬取所有知乎用户信息(上)
爬取的思路 首先我们应该找到一个账号,这个账号被关注的人和关注的人都相对比较多的,就是下图中金字塔顶端的人,然后通过爬取这个账号的信息后,再爬取他关注的人和被关注的人的账号信息,然后爬取被关注人的账号 ...
- Python爬虫从入门到放弃(十四)之 Scrapy框架中选择器的用法
Scrapy提取数据有自己的一套机制,被称作选择器(selectors),通过特定的Xpath或者CSS表达式来选择HTML文件的某个部分Xpath是专门在XML文件中选择节点的语言,也可以用在HTM ...
- python爬虫从入门到放弃前奏之学习方法
首谈方法 最近在整理爬虫系列的博客,但是当整理几篇之后,发现一个问题,不管学习任何内容,其实方法是最重要的,按照我之前写的博客内容,其实学起来还是很点枯燥不能解决传统学习过程中的几个问题: 这个是普通 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
随机推荐
- 在CentOS7下安装jekyll
[root@k8smaster nodejs]# yum install gem ruby ruby-devel -y [root@k8smaster nodejs]# gem sources -l ...
- CSS 浅析position:relative/absolute定位方式
## 一.position:relative 相对定位 ## 分两种情况分析: · 无 position: relative: · 有 position: relative. 代码如下图: 显示效果如 ...
- 记一次服务器Tomcat优化经历
公司需要一台测试服务器来做测试用,所以花了几天时间把服务全部部署好,在部署好war包之后,发现Tomcat访问超级慢. 1.进入Tomcat的bin目录下,运行 ./catalina.sh run命令 ...
- 多行文本省略号的实现.html
多行文本省略号的实现 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...
- php提示php_network_getaddresses: getaddrinfo failed: Name or service not known
php_network_getaddresses: getaddrinfo failed: Name or service not known 面对这个错误,已经相对熟悉了.想起来应该是服务器无法访问 ...
- 一些爬虫中的snippet
1.tornado 一个精简的异步爬虫(来自tornado的demo) #!/usr/bin/env python import time from datetime import timedelta ...
- Socket实现-Socket I/O
Socket层的核心是两个函数:sosend()和soreceive().这两个函数负责处理所有Socket层和协议层之间的I/O操作. select()系统调用的作用是监控文件描述符的状态.一般用于 ...
- CSS三种引入方式:内联、页级、外联
1.内联CSS 内联CSS也可称为行内CSS或者行级CSS,它直接在标签内部引入,显著的优点是十分的便捷.高效:但是同时也造成了不能够重用样式的缺点,如果代码行数到达一定长度不建议采用.通常内联CSS ...
- win7-x64安装mysql5.7.11(官方zip版)
1.下载官方安装包(http://www.mysql.com/downloads/),此zip包是没有安装器的(*.msi),也没有辅助配置的自动程序. 2.解压zip包,将文件放入指定目录,如:D: ...
- Oracle trunc()函数的用法--来着心静禅定ing
1.TRUNC(for dates) TRUNC函数为指定元素而截去的日期值. 其具体的语法格式如下: TRUNC(date[,fmt]) 其中: date 一个日期值 fmt 日期格式,该日期将由指 ...