Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等。熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析。
一、项目分析
1. 网页分析
斗鱼直播网站按直播类型明显在网页上划分区域,同时在每一种类型区域中,视频标签框都将具有相同的class名称,如:直播房间的class名称为:ellipsis,直播类型class为:tag ellipsis,主播名称为:dy-name ellipsis fl,人气活跃度为:dy-num fr,这使得本实验的进行更为便捷。
这里使用xpath_helper_2_0_2工具,对网页中的class进行分析并转换成相应的xpath表达式,如下:
ellipsis为:
//div[@id='live-list-content']//h3[@class='ellipsis']/text()
dy-num fr为:
//div[@id='live-list-content']//span[@class='dy-num fr']/text()
dy-name ellipsis fl为:
//div[@id='live-list-content']//span[@class='dy-name ellipsis fl']/text()
tag ellipsis为:
//div[@id='live-list-content']//span[@class='tag ellipsis']/text()
2. url分析
这里的网页加载可由self.driver调用get()方法完成,同时在网页模块判断的时候,可由其调用find_element_by_class_name('shark-pager-next').click()方法串,自动完成下一页的模拟翻转。
同时可调用page_source.find('shark-pager-disable-next')方法进行判断是否为模块中的最后一页。
二、项目工具
Python 3.7.1 、 JetBrains PyCharm 2018.3.2
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图
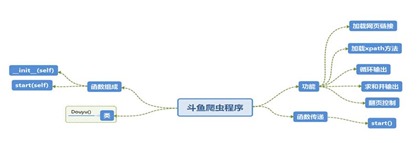
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)

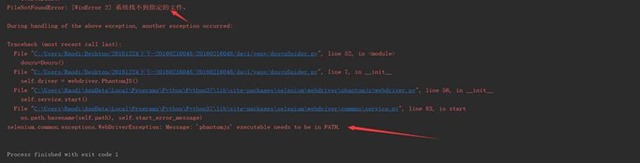
图3-2 爬虫程序BUG描述②
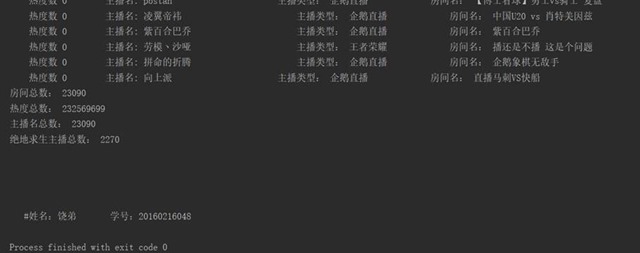
四、项目结果
五、项目心得
关于本例实验心得可总结如下:
1、 当程序运行结果提示错误为:ModuleNotFoundError: No module named 'lxml',最好的解决方法是:首先排除是否lxml是否安装,再检查lxml是否被导入。本实验中,是由于工程项目为能成功导入lxml,解决方法如图5-1所示,在“Project Interperter”中选择python安装目录,即可。
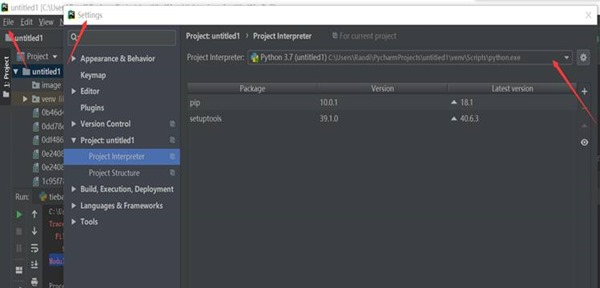
图5-1 错误解决过程
2、 当出现如图4-6的爬虫程序BUG描述时,可以确定为phantomjs没有设置环境变量,或者编程程序没有成功加载环境,后者的解决方法只需重新启动JetBrains PyCharm 2018.3.2即可,对于前者可在系统中设置环境即可
3、 新版selenium不支持phantomJS的解决方法:使用Chrome+headless或Firefox+headless,headless:无头参数,如图5-2所示:
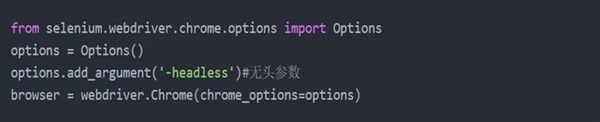
图5-2 解决方法
六、项目源码
doyu.py
from selenium import webdriver
from lxml import etree
import twisted
import scrapy
from openpyxl import Workbook
import time
class Douyu(object):
def __init__(self):
self.driver = webdriver.PhantomJS() def start(self):
self.driver.get('https://www.douyu.com/directory/all')
room_sum=0
host_sum=0
type_sum=0
while True:
time.sleep(2)
content=etree.HTML(self.driver.page_source)
roomnames=content.xpath("//div[@id='live-list-content']//h3[@class='ellipsis']/text()")
hots=content.xpath("//div[@id='live-list-content']//span[@class='dy-num fr']/text()")
names=content.xpath("//div[@id='live-list-content']//span[@class='dy-name ellipsis fl']/text()")
types=content.xpath("//div[@id='live-list-content']//span[@class='tag ellipsis']/text()")
for roomname,hot,name,type in zip(roomnames,hots,names,types):
roomname=roomname.strip()
print("\t热度数",hot," \t主播名:",name," \t主播类型:",type," \t房间名:",roomname)
room_sum+=1
if hot[-1]=='万':
hot=hot[:-1]
hot=int(float(hot)*10000)
host_sum+=hot
#host_sum=host_sum+hot else:
host_sum+=int(hot) if type=='绝地求生':
type_sum+=1
else:
a=0
a+=1
ret=self.driver.page_source.find('shark-pager-disable-next')
if ret>0:
break
else:
# 非最后一页,点击下一页
self.driver.find_element_by_class_name('shark-pager-next').click()
print('房间总数:',room_sum)
print('热度总数:', host_sum)
print('主播名总数:', room_sum)
print('绝地求生主播总数:',type_sum) class DoubanPipeline(object):
wb = Workbook()
ws = wb.active
# 设置表头
ws.append(['标题', '评分']) def process_item(self, item):
# 添加数据
line = [item['title'], item['star']]
self.ws.append(line) # 按行添加
self.wb.save('douban.xlsx')
return item if __name__=="__main__":
douyu=Douyu()
douyu.start() #//div[@id='live-list-content']//h3[@class='ellipsis']/text()
#//div[@id='live-list-content']//span[@class='dy-num fr']/text()
#ret= driver.page_source.find('shark-pager-disable-next')
#print(ret)
Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy项目 - 实现百度贴吧帖子主题及图片爬取的爬虫设计
要求编写的程序可获取任一贴吧页面中的帖子链接,并爬取贴子中用户发表的图片,在此过程中使用user agent 伪装和轮换,解决爬虫ip被目标网站封禁的问题.熟悉掌握基本的网页和url分析,同时能灵活使 ...
- Scrapy实现腾讯招聘网信息爬取【Python】
一.腾讯招聘网 二.代码实现 1.spider爬虫 # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentIte ...
随机推荐
- Spring学习之旅(十三)--使用NoSQL数据库
除了关系型数据库之外,现在还有一种 NoSQL 数据库非常流行,而 Spring 自然也没有放过对它的支持. NoSQL 数据库有很多种,如: MongoDBGenericJackson2JsonRe ...
- 变量声明关键字var ,let,const
今天带大家了解的是比较有趣的几个变量声明关键字var,let,const. 我们在最初接触JS的时候,变量是我们重要的一个组成部分,在使用时规定必须要先进行声明,否则网页将会报错: console.l ...
- Python——常用模块(time/datetime, random, os, shutil, json/pickcle, collections, hashlib/hmac, contextlib)
1.time/datetime 这两个模块是与时间相关的模块,Python中通常用三种方式表示时间: #时间戳(timestamp):表示的是从1970年1月1日00:00:00开始按秒计算的偏移量. ...
- Java连载24-break语句、continue语句、输出质数练习
一.break 1.break是Java语言中的关键字,被翻译为“中断/折断” 2.break + ";"可以成为一个单独的完整的java语句: break; 3.break语 ...
- filter修改post参数
前景:公司项目web渗透测试中提出管理登录时,传输密码不能为明文,需要加密传输,但是迫于系统架构,后端代码不能修改,只能在filter中解密参数. 1.前端加密处理: <script type= ...
- ASP.NET Core 3.0中使用动态控制器路由
原文:Dynamic controller routing in ASP.NET Core 3.0 作者:Filip W 译文:https://www.cnblogs.com/lwqlun/p/114 ...
- P2774 方格取数问题 网络最大流 割
P2774 方格取数问题:https://www.luogu.org/problemnew/show/P2774 题意: 给定一个矩阵,取出不相邻的数字,使得数字的和最大. 思路: 可以把方格分成两个 ...
- POJ 1236 Network of Schools - 缩点
POJ 1236 :http://poj.org/problem?id=1236 参考:https://www.cnblogs.com/TnT2333333/p/6875680.html 题意: 有好 ...
- 通过对微信pc hook实现微信助手
本软件主要通过对pc端微信hook来实现的,微信版本2.6.8.52. 软件下载地址: http://blog.yshizi.cn/104.html 软件实现功能: 支持爆粉 支持文本消息群发 支持自 ...
- 在docker上编译openjdk8
以前曾经试过在VMware上安装linux,再在linux上编译openjdk8,但是每次都不顺利,例如linux环境,预装依赖软件,openjdk源码的选择等环境都会遇到问题,一旦失败再重新开始挺费 ...