吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) # plotly
import chart_studio.plotly as py
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
import plotly.graph_objs as go
import seaborn as sns
# word cloud library
from wordcloud import WordCloud # matplotlib
import matplotlib.pyplot as plt
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
dataframe = pd.read_csv("F:\\kaggleDataSet\\healthcare-data\\test_2v.csv")
import chart_studio.plotly as py
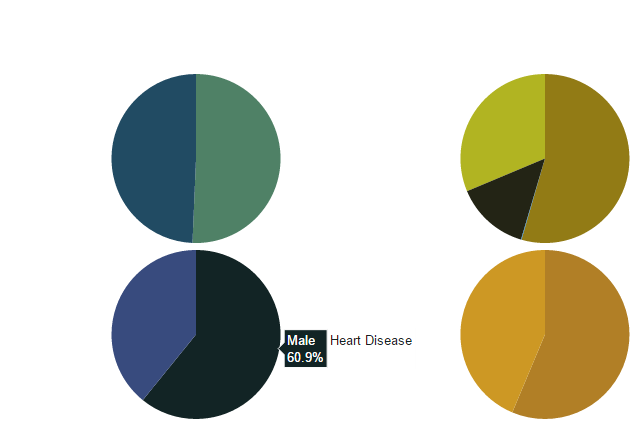
from plotly.graph_objs import * df_heart_disease = dataframe[dataframe.heart_disease== 1]
labels = df_heart_disease.gender
pie1_list=df_heart_disease.heart_disease df_hypertension= dataframe[dataframe.hypertension == 1]
labels1 = df_hypertension.gender
pie1_list1=df_hypertension.hypertension labels2 = dataframe.Residence_type
pie1_list2 = dataframe.heart_disease labels3 = dataframe.work_type
pie1_list3 = dataframe.heart_disease fig = {
'data': [
{
'labels': labels,
'values': pie1_list,
'type': 'pie',
'name': 'Heart Disease',
'marker': {'colors': ['rgb(56, 75, 126)',
'rgb(18, 36, 37)',
'rgb(34, 53, 101)',
'rgb(36, 55, 57)',
'rgb(6, 4, 4)']},
'domain': {'x': [0, .48],
'y': [0, .49]},
'hoverinfo':'label+percent+name',
'textinfo':'none'
},
{
'labels': labels1,
'values': pie1_list1,
'marker': {'colors': ['rgb(177, 127, 38)',
'rgb(205, 152, 36)',
'rgb(99, 79, 37)',
'rgb(129, 180, 179)',
'rgb(124, 103, 37)']},
'type': 'pie',
'name': 'Hypertension',
'domain': {'x': [.52, 1],
'y': [0, .49]},
'hoverinfo':'label+percent+name',
'textinfo':'none' },
{
'labels': labels2,
'values': pie1_list2,
'marker': {'colors': ['rgb(33, 75, 99)',
'rgb(79, 129, 102)',
'rgb(151, 179, 100)',
'rgb(175, 49, 35)',
'rgb(36, 73, 147)']},
'type': 'pie',
'name': 'Residence Type',
'domain': {'x': [0, .48],
'y': [.51, 1]},
'hoverinfo':'label+percent+name',
'textinfo':'none'
},
{
'labels': labels3,
'values': pie1_list3,
'marker': {'colors': ['rgb(146, 123, 21)',
'rgb(177, 180, 34)',
'rgb(206, 206, 40)',
'rgb(175, 51, 21)',
'rgb(35, 36, 21)']},
'type': 'pie',
'name':'Work Type',
'domain': {'x': [.52, 1],
'y': [.51, 1]},
'hoverinfo':'label+percent+name',
'textinfo':'none'
} ],
'layout': {'title': '',
'showlegend': False}
} iplot(fig)
import chart_studio.plotly as py
import plotly.graph_objs as go # Create random data with numpy
import numpy as np df_250 = dataframe.iloc[:250,:] random_x = df_250.index
random_y0 = df_250.avg_glucose_level
random_y1 = df_250.bmi
random_y2 = df_250.age # Create traces
trace0 = go.Scatter(
x = random_x,
y = random_y0,
mode = 'markers',
name = 'Avg. Glucose Level'
)
trace1 = go.Scatter(
x = random_x,
y = random_y1,
mode = 'lines+markers',
name = 'BMI'
)
trace2 = go.Scatter(
x = random_x,
y = random_y2,
mode = 'lines',
name = 'Age'
) data = [trace0, trace1, trace2]
iplot(data, filename='scatter-mode')

import chart_studio.plotly as py
import plotly.graph_objs as go
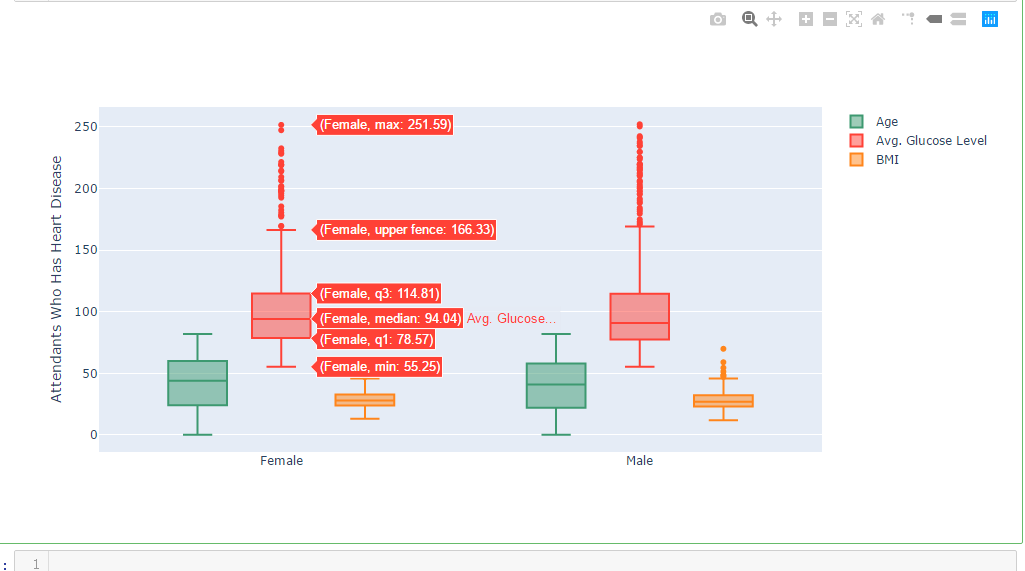
df_heart_disease = dataframe[dataframe.heart_disease==1]
labels = df_heart_disease.gender
x = labels trace0 = go.Box(
y=dataframe.age,
x=x,
name='Age',
marker=dict(
color='#3D9970'
)
)
trace1 = go.Box(
y=dataframe.avg_glucose_level,
x=x,
name='Avg. Glucose Level',
marker=dict(
color='#FF4136'
)
)
trace2 = go.Box(
y=dataframe.bmi,
x=x,
name='BMI',
marker=dict(
color='#FF851B'
)
)
data = [trace0, trace1, trace2]
layout = go.Layout(
yaxis=dict(
title='Attendants Who Has Heart Disease',
zeroline=False
),
boxmode='group'
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
import chart_studio.plotly as py
import plotly.graph_objs as go
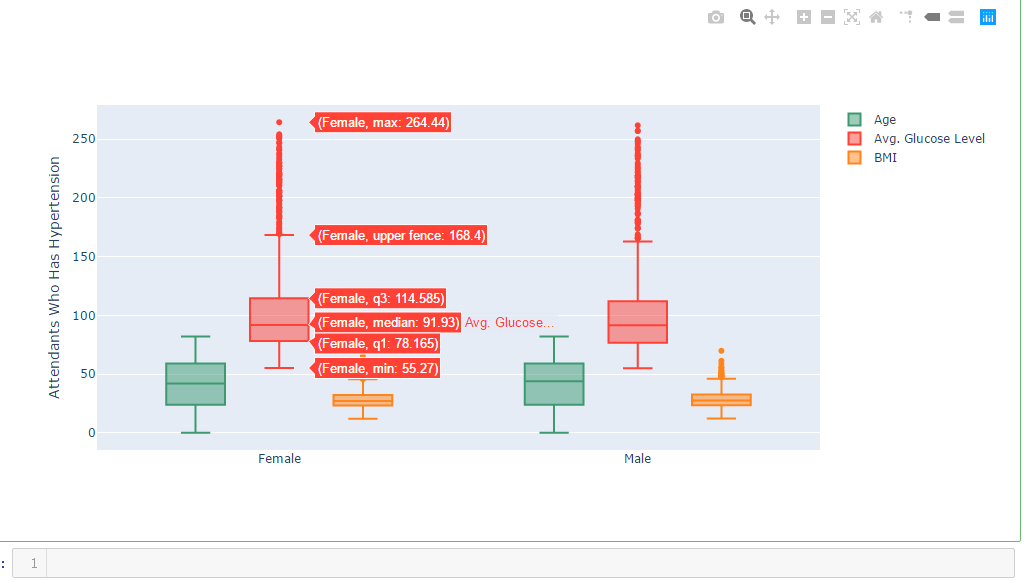
df_hypertension= dataframe[dataframe.hypertension == 1]
labels1 = df_hypertension.gender
x = labels1 trace0 = go.Box(
y=dataframe.age,
x=x,
name='Age',
marker=dict(
color='#3D9970'
)
)
trace1 = go.Box(
y=dataframe.avg_glucose_level,
x=x,
name='Avg. Glucose Level',
marker=dict(
color='#FF4136'
)
)
trace2 = go.Box(
y=dataframe.bmi,
x=x,
name='BMI',
marker=dict(
color='#FF851B'
)
)
data = [trace0, trace1, trace2]
layout = go.Layout(
yaxis=dict(
title='Attendants Who Has Hypertension',
zeroline=False
),
boxmode='group'
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
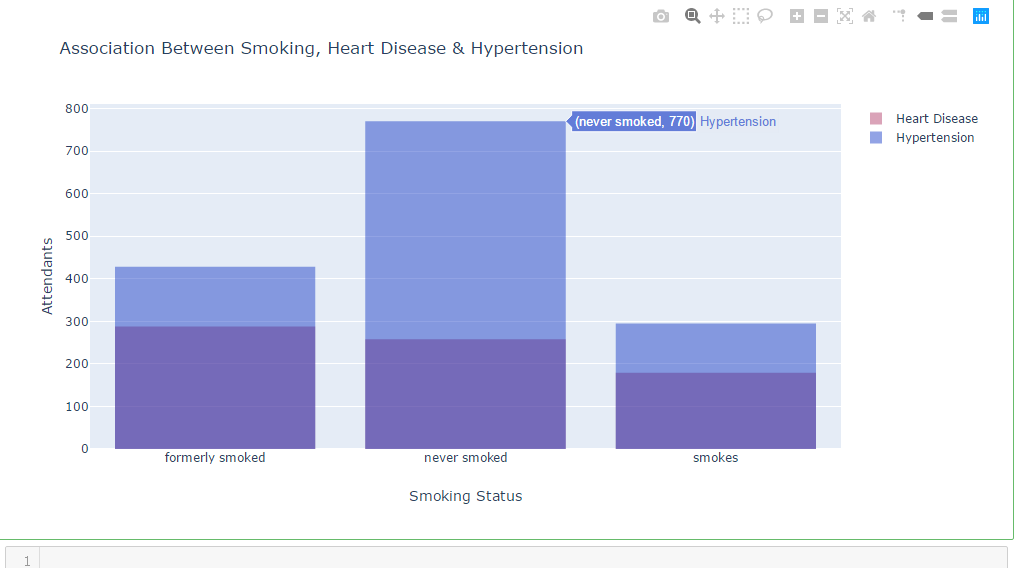
df_heart_disease_1 = dataframe.smoking_status [dataframe.heart_disease == 1 ]
df_hypertension_1 = dataframe.smoking_status [dataframe.hypertension == 1 ]
trace1 = go.Histogram(
x=df_heart_disease_1,
opacity=0.75,
name = "Heart Disease",
marker=dict(color='rgba(171, 50, 96, 0.6)'))
trace2 = go.Histogram(
x=df_hypertension_1,
opacity=0.75,
name = "Hypertension",
marker=dict(color='rgba(12, 50, 196, 0.6)')) data = [trace1, trace2]
layout = go.Layout(barmode='overlay',
title=' Association Between Smoking, Heart Disease & Hypertension',
xaxis=dict(title='Smoking Status'),
yaxis=dict( title='Attendants'),
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)
df_heart_disease_1 = dataframe.work_type [dataframe.heart_disease == 1 ]
df_hypertension_1 = dataframe.work_type [dataframe.hypertension == 1 ] trace1 = go.Histogram(
x=df_heart_disease_1,
opacity=0.75,
name = "Heart Disease",
marker=dict(color='rgba(171, 50, 96, 0.6)'))
trace2 = go.Histogram(
x=df_hypertension_1,
opacity=0.75,
name = "Hypertension",
marker=dict(color='rgba(12, 50, 196, 0.6)')) data = [trace1, trace2]
layout = go.Layout(barmode='overlay',
title=' Association Between Work Type, Heart Disease & Hypertension',
xaxis=dict(title=''),
yaxis=dict( title='Attendants'),
)
fig = go.Figure(data=data, layout=layout)
iplot(fig)

吴裕雄--天生自然 PYTHON数据分析:医疗数据分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 PYTHON语言数据分析:ESA的火星快车操作数据集分析
import os import numpy as np import pandas as pd from datetime import datetime import matplotlib imp ...
- 吴裕雄--天生自然 python语言数据分析:开普勒系外行星搜索结果分析
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) pd.DataFrame({'Bob': ['I liked i ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
随机推荐
- UML-如何进行对象设计?
之前的章节,学过了OOA,以及交互图+类图.本章主要讲述OOD.OOD就是面向对象设计,那如何进行对象设计? 概览 1.输入制品 注:这些制品并非都必要. 2.活动 1).针对输入的制品,采用什么样的 ...
- 豆瓣爬虫Scrapy“抄袭”改写
主要是把项目从docker里面扒拉出来,但是扒拉完好像又没有什么用,放在docker里面运行多好. 源码下载下面主要记一下改动的地方吧. 配置:在database.py中改掉自己的数据库配置. 表结构 ...
- 第五章——Pytorch中常用的工具
2018年07月07日 17:30:40 __矮油不错哟 阅读数:221 1. 数据处理 数据加载 ImageFolder DataLoader加载数据 sampler:采样模块 1. 数据处理 ...
- 套接字详解(socket)
用户认为的信息之间传输只是建立以两个应用程序上,实际上在TCP连接中是靠套接字来作为他们连接的桥梁. 那么什么是套接字呢? TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点,这种端点就叫做 ...
- 如何判断Office是32位还是64位?
对于持续学习VBA的老铁们,有必要了解Office的位数. 如果系统是32位的,则不需要判断Office位数了,因为只能安装32位Office. 下面只讨论64位系统中,Office的位数判断问题. ...
- npm安装依赖报 npm ERR! code Z_BUF_ERROR npm ERR! errno -5 npm ERR! zlib: unexpected end of file 这个错误解决方案
今天碰到了一个比较奇怪的问题,下载依赖有问题报错 npm ERR! code Z_BUF_ERROR npm ERR! errno -5 npm ERR! zlib: unexpected end o ...
- ORM表之间高级设计
ORM表之间高级设计 一.表的继承 # db_test1 # 一.基表 # Model类的内部配置Meta类要设置abstract=True, # 这样的Model类就是用来作为基表 # 多表:Boo ...
- IMX6开发板qt creator直接编译ARM架构程序
除了通过 11.2.2 小节通过命令行的操作来编译在 iTOP-imx6 开发板上运行的程序,还可以直接在 qtcreator 上设置,然后每次编译的程序都可以在开发板上运行.如下图所示,打开 qtc ...
- Java快速输入输出
一.StreamTokenizer实现快速输入 需要的jar包 import java.io.BufferedReader;import java.io.IOException;import java ...
- C3D使用指南
C3D GitHub项目地址:https://github.com/facebook/C3D C3D 官方用户指南:https://goo.gl/k2SnLY 1. C3D特征提取 1.1 命令参数介 ...