吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np
import pandas as pd
import os
import matplotlib.pyplot as pl
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('F:\\kaggleDataSet\\MedicalCostPersonal\\insurance.csv')
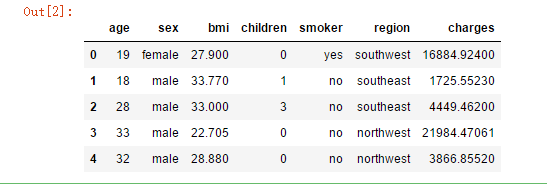
data.head()
data.isnull().sum()

from sklearn.preprocessing import LabelEncoder
#sex
le = LabelEncoder()
le.fit(data.sex.drop_duplicates())
data.sex = le.transform(data.sex)
# smoker or not
le.fit(data.smoker.drop_duplicates())
data.smoker = le.transform(data.smoker)
#region
le.fit(data.region.drop_duplicates())
data.region = le.transform(data.region)
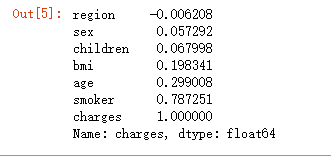
data.corr()['charges'].sort_values()
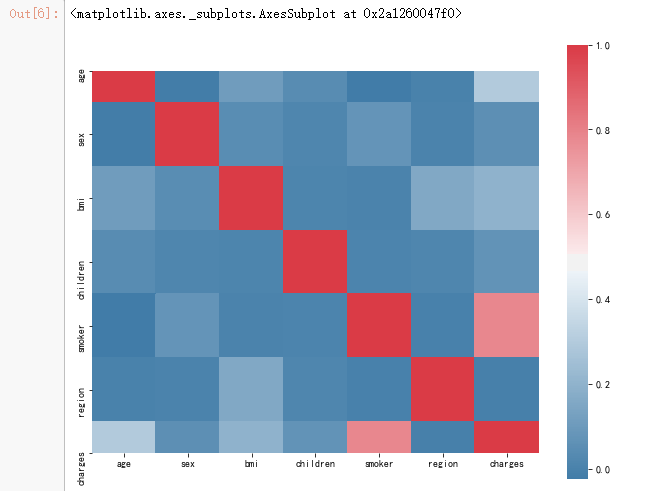
f, ax = pl.subplots(figsize=(10, 8))
corr = data.corr()
sns.heatmap(corr, mask=np.zeros_like(corr, dtype=np.bool), cmap=sns.diverging_palette(240,10,as_cmap=True),square=True, ax=ax)
from bokeh.io import output_notebook, show
from bokeh.plotting import figure
output_notebook()
import scipy.special
from bokeh.layouts import gridplot
from bokeh.plotting import figure, show, output_file
p = figure(title="Distribution of charges",tools="save",background_fill_color="#E8DDCB")
hist, edges = np.histogram(data.charges)
p.quad(top=hist, bottom=0, left=edges[:-1], right=edges[1:],fill_color="#036564", line_color="#033649")
p.xaxis.axis_label = 'x'
p.yaxis.axis_label = 'Pr(x)'
show(gridplot(p,ncols = 2, plot_width=400, plot_height=400, toolbar_location=None))

f= pl.figure(figsize=(12,5)) ax=f.add_subplot(121)
sns.distplot(data[(data.smoker == 1)]["charges"],color='c',ax=ax)
ax.set_title('Distribution of charges for smokers') ax=f.add_subplot(122)
sns.distplot(data[(data.smoker == 0)]['charges'],color='b',ax=ax)
ax.set_title('Distribution of charges for non-smokers')
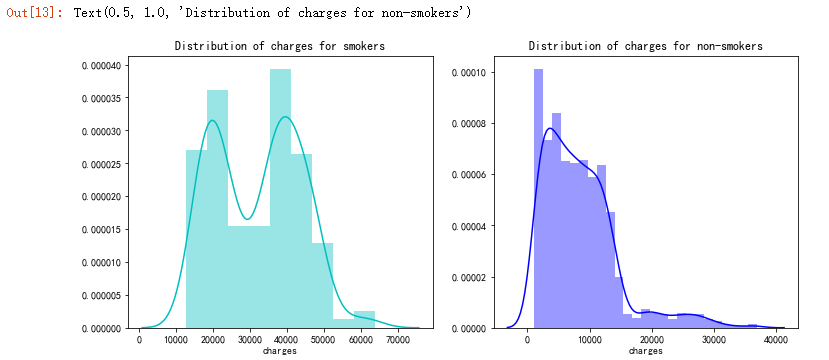
sns.catplot(x="smoker", kind="count",hue = 'sex', palette="pink", data=data)
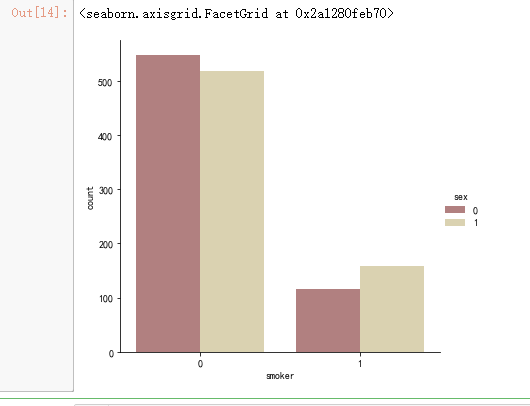
sns.catplot(x="sex", y="charges", hue="smoker",kind="violin", data=data, palette = 'magma')
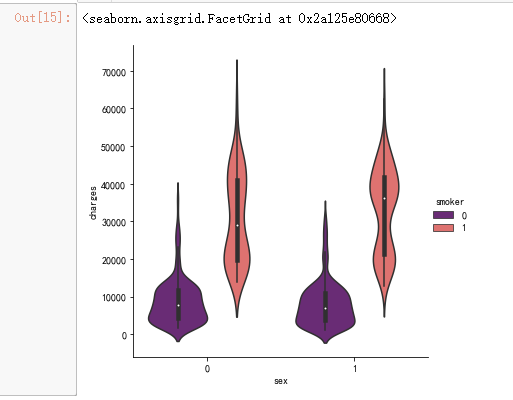
pl.figure(figsize=(12,5))
pl.title("Box plot for charges of women")
sns.boxplot(y="smoker", x="charges", data = data[(data.sex == 1)] , orient="h", palette = 'magma')
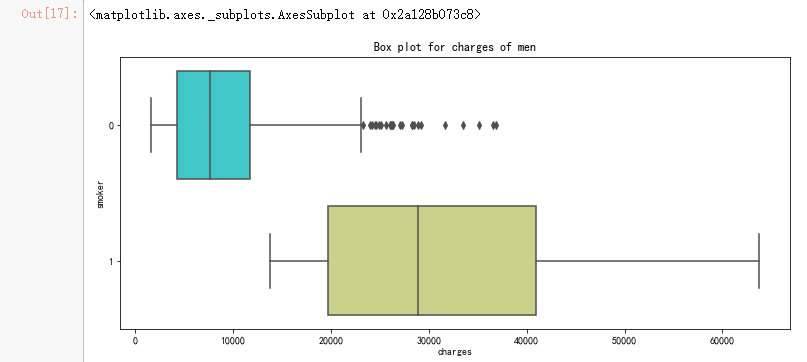
pl.figure(figsize=(12,5))
pl.title("Box plot for charges of men")
sns.boxplot(y="smoker", x="charges", data = data[(data.sex == 0)] , orient="h", palette = 'rainbow')
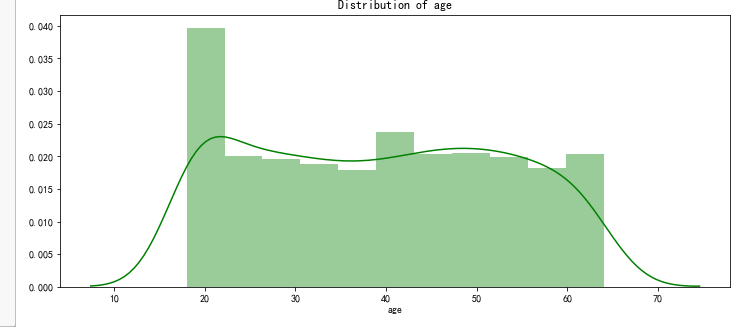
pl.figure(figsize=(12,5))
pl.title("Distribution of age")
ax = sns.distplot(data["age"], color = 'g')
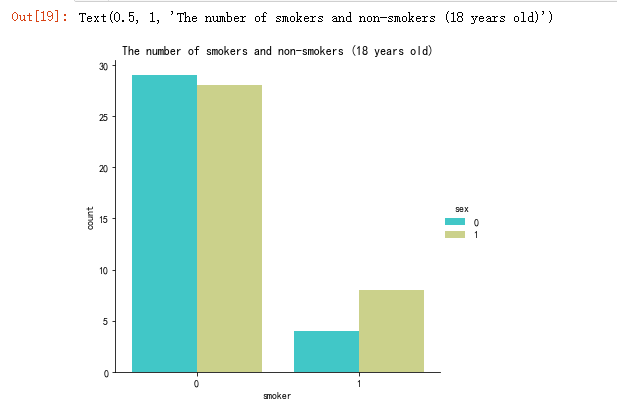
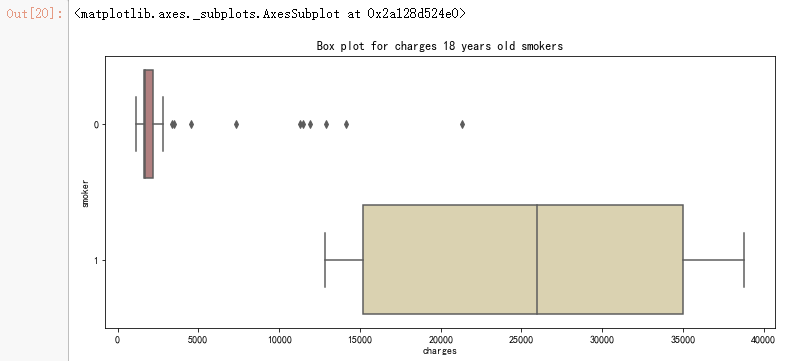
sns.catplot(x="smoker", kind="count",hue = 'sex', palette="rainbow", data=data[(data.age == 18)])
pl.title("The number of smokers and non-smokers (18 years old)")
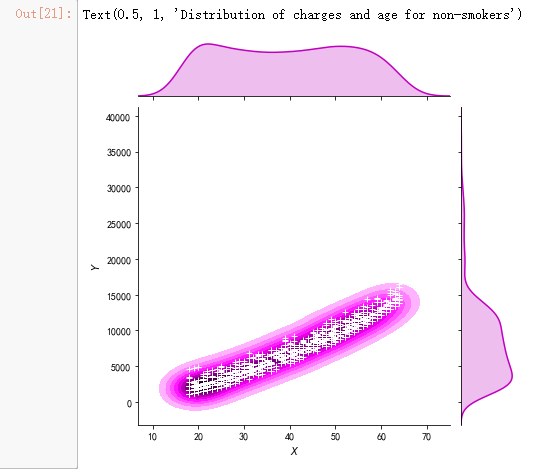
g = sns.jointplot(x="age", y="charges", data = data[(data.smoker == 0)],kind="kde", color="m")
g.plot_joint(pl.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$")
ax.set_title('Distribution of charges and age for non-smokers')
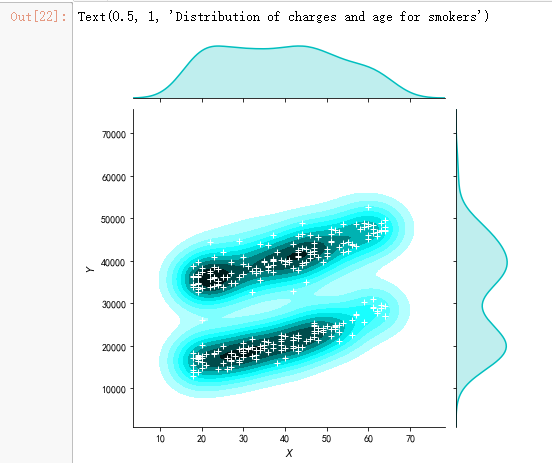
g = sns.jointplot(x="age", y="charges", data = data[(data.smoker == 1)],kind="kde", color="c")
g.plot_joint(pl.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$")
ax.set_title('Distribution of charges and age for smokers')
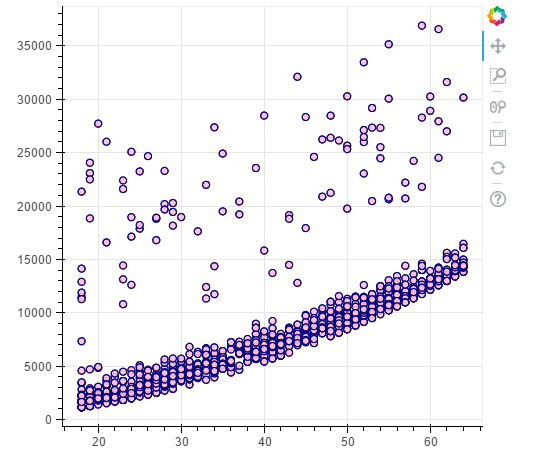
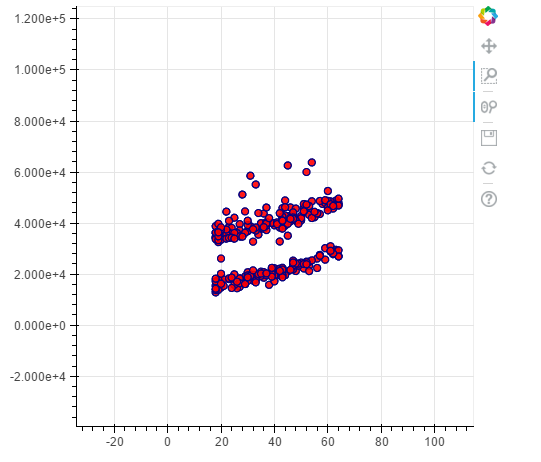
#non - smokers
p = figure(plot_width=500, plot_height=450)
p.circle(x=data[(data.smoker == 0)].age,y=data[(data.smoker == 0)].charges, size=7, line_color="navy", fill_color="pink", fill_alpha=0.9) show(p)
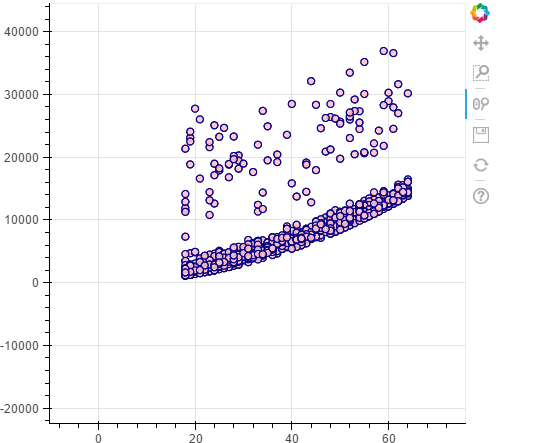
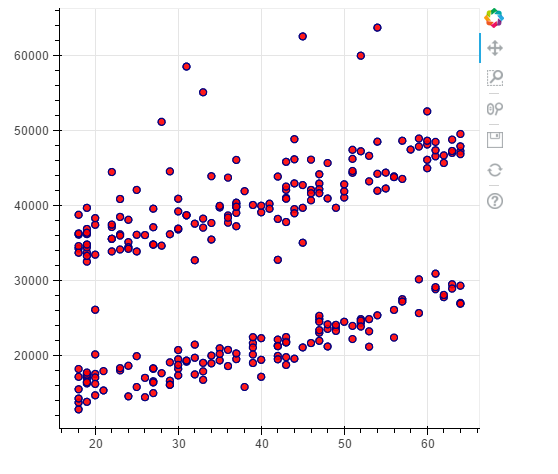
#smokers
p = figure(plot_width=500, plot_height=450)
p.circle(x=data[(data.smoker == 1)].age,y=data[(data.smoker == 1)].charges, size=7, line_color="navy", fill_color="red", fill_alpha=0.9)
show(p)
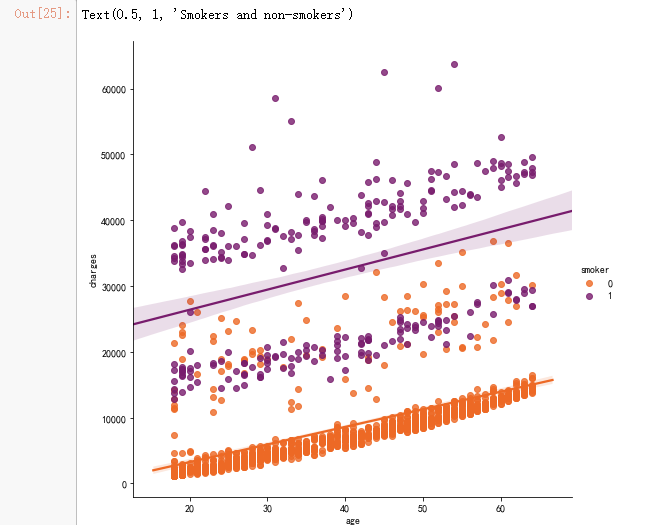
sns.lmplot(x="age", y="charges", hue="smoker", data=data, palette = 'inferno_r', size = 7)
ax.set_title('Smokers and non-smokers')
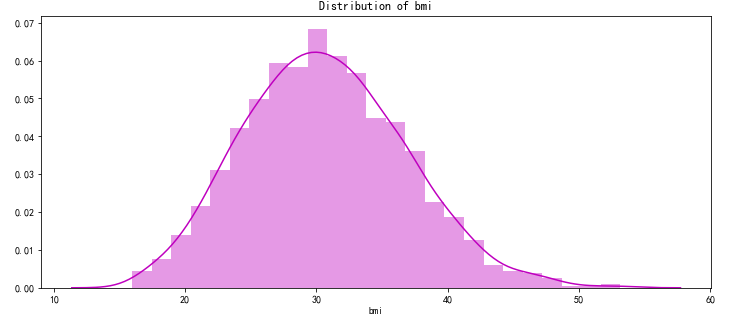
pl.figure(figsize=(12,5))
pl.title("Distribution of bmi")
ax = sns.distplot(data["bmi"], color = 'm')
pl.figure(figsize=(12,5))
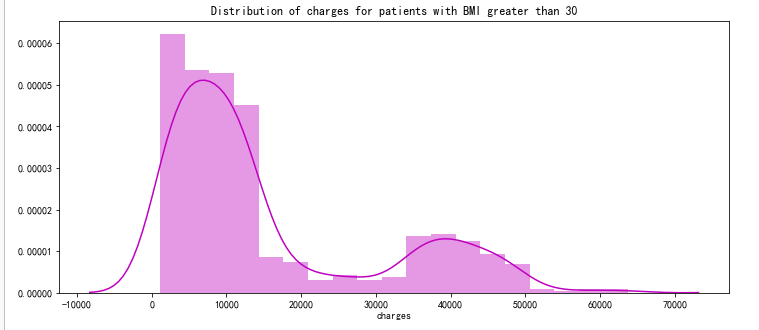
pl.title("Distribution of charges for patients with BMI greater than 30")
ax = sns.distplot(data[(data.bmi >= 30)]['charges'], color = 'm')
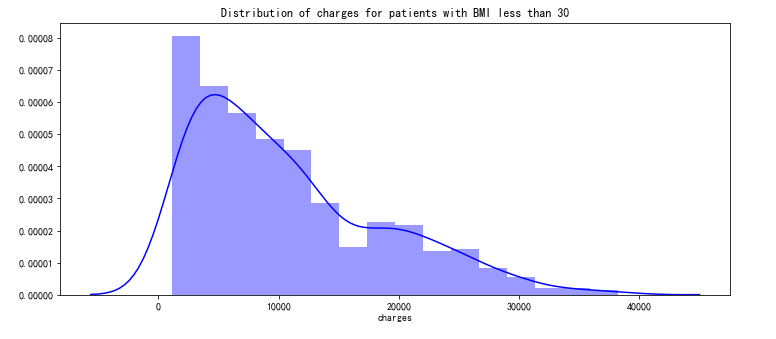
pl.figure(figsize=(12,5))
pl.title("Distribution of charges for patients with BMI less than 30")
ax = sns.distplot(data[(data.bmi < 30)]['charges'], color = 'b')
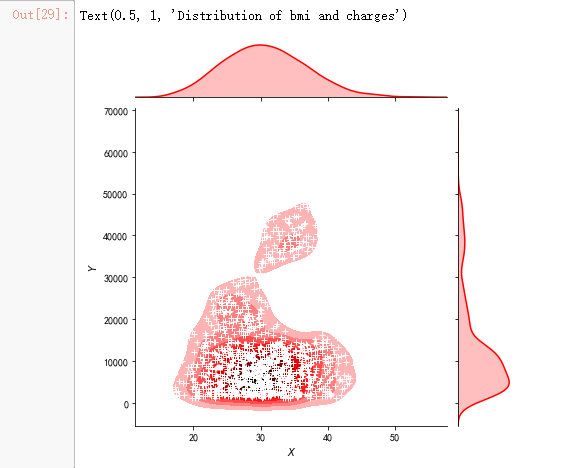
g = sns.jointplot(x="bmi", y="charges", data = data,kind="kde", color="r")
g.plot_joint(pl.scatter, c="w", s=30, linewidth=1, marker="+")
g.ax_joint.collections[0].set_alpha(0)
g.set_axis_labels("$X$", "$Y$")
ax.set_title('Distribution of bmi and charges')
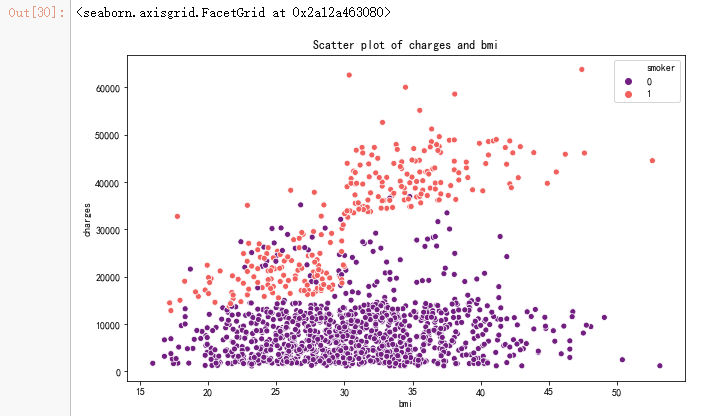
pl.figure(figsize=(10,6))
ax = sns.scatterplot(x='bmi',y='charges',data=data,palette='magma',hue='smoker')
ax.set_title('Scatter plot of charges and bmi') sns.lmplot(x="bmi", y="charges", hue="smoker", data=data, palette = 'magma', size = 8)
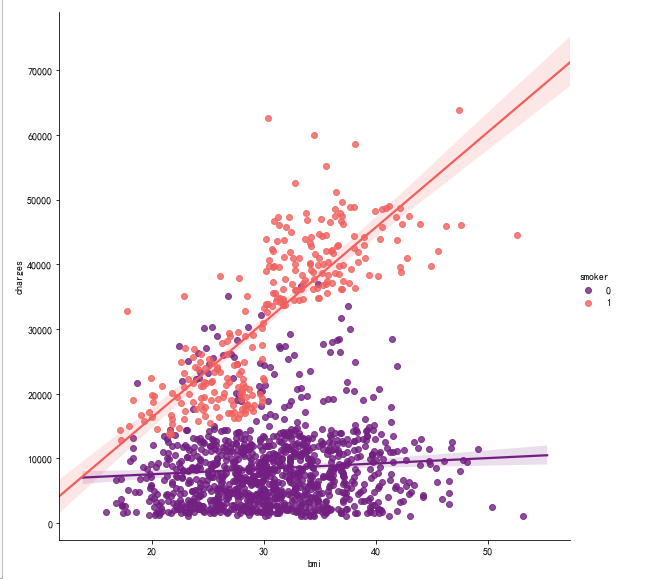
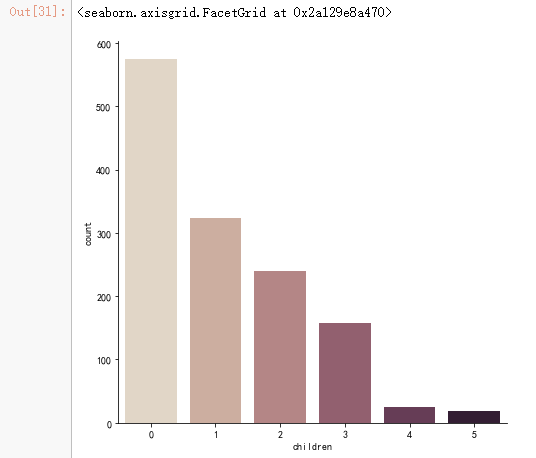
sns.catplot(x="children", kind="count", palette="ch:.25", data=data, size = 6)
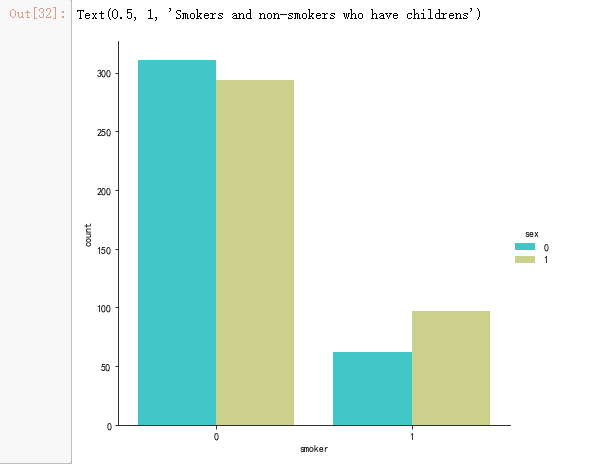
sns.catplot(x="smoker", kind="count", palette="rainbow",hue = "sex",
data=data[(data.children > 0)], size = 6)
ax.set_title('Smokers and non-smokers who have childrens')
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import PolynomialFeatures
from sklearn.metrics import r2_score,mean_squared_error
from sklearn.ensemble import RandomForestRegressor
x = data.drop(['charges'], axis = 1)
y = data.charges x_train,x_test,y_train,y_test = train_test_split(x,y, random_state = 0)
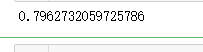
lr = LinearRegression().fit(x_train,y_train) y_train_pred = lr.predict(x_train)
y_test_pred = lr.predict(x_test) print(lr.score(x_test,y_test))
X = data.drop(['charges','region'], axis = 1)
Y = data.charges quad = PolynomialFeatures (degree = 2)
x_quad = quad.fit_transform(X) X_train,X_test,Y_train,Y_test = train_test_split(x_quad,Y, random_state = 0) plr = LinearRegression().fit(X_train,Y_train) Y_train_pred = plr.predict(X_train)
Y_test_pred = plr.predict(X_test) print(plr.score(X_test,Y_test))
forest = RandomForestRegressor(n_estimators = 100,criterion = 'mse',random_state = 1,n_jobs = -1)
forest.fit(x_train,y_train)
forest_train_pred = forest.predict(x_train)
forest_test_pred = forest.predict(x_test) print('MSE train data: %.3f, MSE test data: %.3f' % (
mean_squared_error(y_train,forest_train_pred),
mean_squared_error(y_test,forest_test_pred)))
print('R2 train data: %.3f, R2 test data: %.3f' % (
r2_score(y_train,forest_train_pred),
r2_score(y_test,forest_test_pred)))

pl.figure(figsize=(10,6)) pl.scatter(forest_train_pred,forest_train_pred - y_train,c = 'black', marker = 'o', s = 35, alpha = 0.5,label = 'Train data')
pl.scatter(forest_test_pred,forest_test_pred - y_test,c = 'c', marker = 'o', s = 35, alpha = 0.7,label = 'Test data')
pl.xlabel('Predicted values')
pl.ylabel('Tailings')
pl.legend(loc = 'upper left')
pl.hlines(y = 0, xmin = 0, xmax = 60000, lw = 2, color = 'red')
pl.show()

吴裕雄--天生自然 python数据分析:医疗费数据分析的更多相关文章
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 PYTHON语言数据分析:ESA的火星快车操作数据集分析
import os import numpy as np import pandas as pd from datetime import datetime import matplotlib imp ...
- 吴裕雄--天生自然 python语言数据分析:开普勒系外行星搜索结果分析
import pandas as pd pd.DataFrame({'Yes': [50, 21], 'No': [131, 2]}) pd.DataFrame({'Bob': ['I liked i ...
- 吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results import numpy as np import ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
随机推荐
- VS debug下为什么多此一举jmp函数地址?
VS debug下为什么call 函数后,会jmp函数地址?多此一举? http://blog.csdn.net/viper/article/details/6332934 在写跑在main之前的时候 ...
- hdu 1159求最长公共子序列
题目描述:给出两个字符串,求两个字符串的公共子序列(不是公共子串,不要求连续,但要符合在原字符串中的顺序) in: abcfbc abfcab programming contest abcd mnp ...
- kendo-ui 几个有用的数据操作
在工作中发现几个有用的api: 一,grid1.获得grid var grid = $("#proList").data("kendoGrid");2.获得da ...
- Python常用库 - logging日志库
logging的简单介绍 用作记录日志,默认分为六种日志级别(括号为级别对应的数值) NOTSET(0) DEBUG(10) INFO(20) WARNING(30) ERROR(40) CRITIC ...
- 《 Java 编程思想》CH08 多态
在面向对象的程序设计语言中,多态是继数据抽象和继承之后的第三种基本特征. 多态通过分离做什么和怎么做,从另一个角度将接口和实现分离开来. "封装"通过合并特征和行为来创建新的数据类 ...
- java服务器端线程体会
一个完整的项目包括服务器和客服端 服务器端初步编写: (1) 服务器端应用窗口的编写 (服务器类Server): 包括窗口和组件的一些设置, 添加一些客服端的元素,如客服端在线用户表(Vector), ...
- MySQL的简介
什么是数据库 1. 数据库(Database)是按照数据结构来组织.存储和管理数据的仓库,每个数据库都有一个或多个不同 的API(接口)用于创建,访问,管理,搜索和复制所保存的数据 2. 我们也可以将 ...
- idea快速创建一个类 实现一个接口
一 创建一个接口类 二 点击接口名称 按alt + ent 三 选择implement interface 选项 完美!!!!!!!
- 新手必看:PyCharm安装教程,Python开发者的有力工具
PyCharm是由JetBrains打造的一款Python IDE,VS2010的重构插件Resharper就是出自JetBrains之手. 同时支持Google App Engine,PyCharm ...
- EF--封装三层架构IOC
为什么分层? 不分层封装的话,下面的代码就是上端直接依赖于下端,也就是UI层直接依赖于数据访问层,分层一定要依赖抽象,满足依赖倒置原则,所以我们要封装,要分层 下面这张图和传统的三层略有不同,不同之处 ...