吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据
#We import libraries for linear algebra, graphs, and evaluation of results
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_curve, roc_auc_score
from scipy.ndimage.filters import uniform_filter1d
#Keras is a high level neural networks library, based on either tensorflow or theano
from keras.models import Sequential, Model
from keras.layers import Conv1D, MaxPool1D, Dense, Dropout, Flatten, BatchNormalization, Input, concatenate, Activation
from keras.optimizers import Adam
INPUT_LIB = 'F:\\kaggleDataSet\\kepler-labelled\\'
raw_data = np.loadtxt(INPUT_LIB + 'exoTrain.csv', skiprows=1, delimiter=',')
x_train = raw_data[:, 1:]
y_train = raw_data[:, 0, np.newaxis] - 1.
raw_data = np.loadtxt(INPUT_LIB + 'exoTest.csv', skiprows=1, delimiter=',')
x_test = raw_data[:, 1:]
y_test = raw_data[:, 0, np.newaxis] - 1.
del raw_data
x_train = ((x_train - np.mean(x_train, axis=1).reshape(-1,1))/ np.std(x_train, axis=1).reshape(-1,1))
x_test = ((x_test - np.mean(x_test, axis=1).reshape(-1,1)) / np.std(x_test, axis=1).reshape(-1,1))
x_train = np.stack([x_train, uniform_filter1d(x_train, axis=1, size=200)], axis=2)
x_test = np.stack([x_test, uniform_filter1d(x_test, axis=1, size=200)], axis=2)
model = Sequential()
model.add(Conv1D(filters=8, kernel_size=11, activation='relu', input_shape=x_train.shape[1:]))
model.add(MaxPool1D(strides=4))
model.add(BatchNormalization())
model.add(Conv1D(filters=16, kernel_size=11, activation='relu'))
model.add(MaxPool1D(strides=4))
model.add(BatchNormalization())
model.add(Conv1D(filters=32, kernel_size=11, activation='relu'))
model.add(MaxPool1D(strides=4))
model.add(BatchNormalization())
model.add(Conv1D(filters=64, kernel_size=11, activation='relu'))
model.add(MaxPool1D(strides=4))
model.add(Flatten())
model.add(Dropout(0.5))
model.add(Dense(64, activation='relu'))
model.add(Dropout(0.25))
model.add(Dense(64, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
def batch_generator(x_train, y_train, batch_size=32):
"""
Gives equal number of positive and negative samples, and rotates them randomly in time
"""
half_batch = batch_size // 2
x_batch = np.empty((batch_size, x_train.shape[1], x_train.shape[2]), dtype='float32')
y_batch = np.empty((batch_size, y_train.shape[1]), dtype='float32') yes_idx = np.where(y_train[:,0] == 1.)[0]
non_idx = np.where(y_train[:,0] == 0.)[0] while True:
np.random.shuffle(yes_idx)
np.random.shuffle(non_idx) x_batch[:half_batch] = x_train[yes_idx[:half_batch]]
x_batch[half_batch:] = x_train[non_idx[half_batch:batch_size]]
y_batch[:half_batch] = y_train[yes_idx[:half_batch]]
y_batch[half_batch:] = y_train[non_idx[half_batch:batch_size]] for i in range(batch_size):
sz = np.random.randint(x_batch.shape[1])
x_batch[i] = np.roll(x_batch[i], sz, axis = 0) yield x_batch, y_batch
#Start with a slightly lower learning rate, to ensure convergence
model.compile(optimizer=Adam(1e-5), loss = 'binary_crossentropy', metrics=['accuracy'])
hist = model.fit_generator(batch_generator(x_train, y_train, 32),
validation_data=(x_test, y_test),
verbose=0, epochs=5,
steps_per_epoch=x_train.shape[1]//32)
#Then speed things up a little
model.compile(optimizer=Adam(4e-5), loss = 'binary_crossentropy', metrics=['accuracy'])
hist = model.fit_generator(batch_generator(x_train, y_train, 32),
validation_data=(x_test, y_test),
verbose=2, epochs=40,
steps_per_epoch=x_train.shape[1]//32)


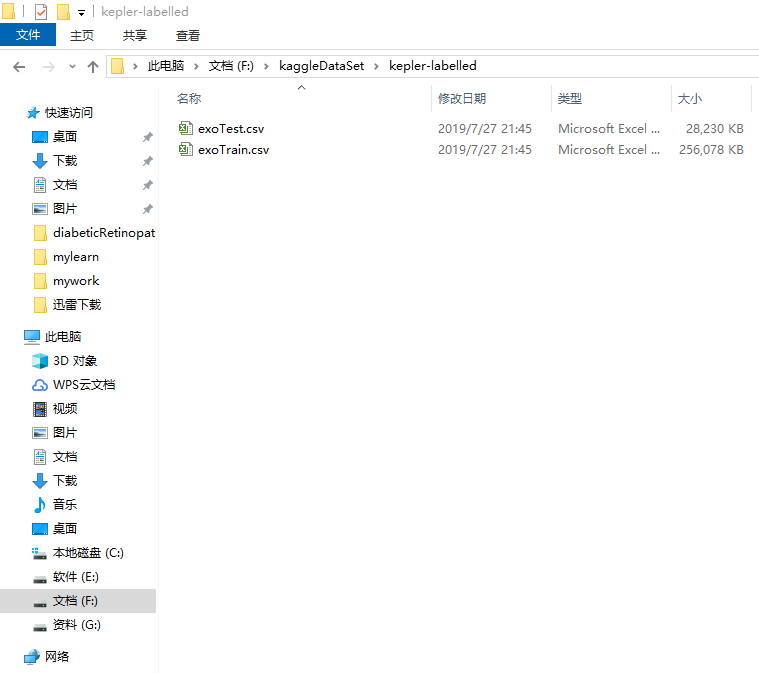
plt.plot(hist.history['loss'], color='b')
plt.plot(hist.history['val_loss'], color='r')
plt.show()
plt.plot(hist.history['acc'], color='b')
plt.plot(hist.history['val_acc'], color='r')
plt.show()
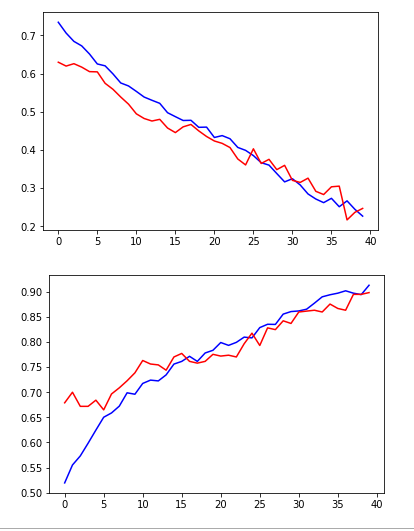
non_idx = np.where(y_test[:,0] == 0.)[0]
yes_idx = np.where(y_test[:,0] == 1.)[0]
y_hat = model.predict(x_test)[:,0]
plt.plot([y_hat[i] for i in yes_idx], 'bo')
plt.show()
plt.plot([y_hat[i] for i in non_idx], 'ro')
plt.show()
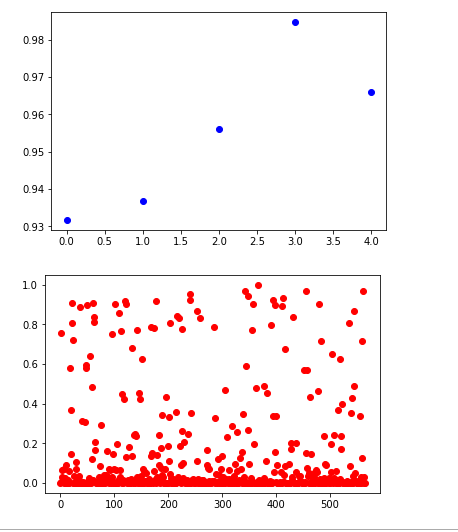
y_true = (y_test[:, 0] + 0.5).astype("int")
fpr, tpr, thresholds = roc_curve(y_true, y_hat)
plt.plot(thresholds, 1.-fpr)
plt.plot(thresholds, tpr)
plt.show()
crossover_index = np.min(np.where(1.-fpr <= tpr))
crossover_cutoff = thresholds[crossover_index]
crossover_specificity = 1.-fpr[crossover_index]
print("Crossover at {0:.2f} with specificity {1:.2f}".format(crossover_cutoff, crossover_specificity))
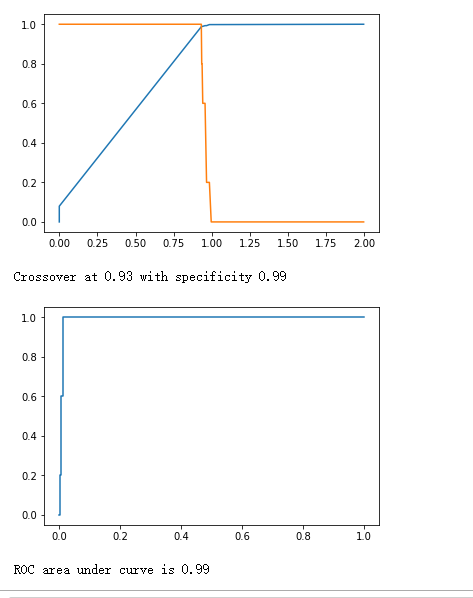
plt.plot(fpr, tpr)
plt.show()
print("ROC area under curve is {0:.2f}".format(roc_auc_score(y_true, y_hat)))
false_positives = np.where(y_hat * (1. - y_test) > 0.5)[0]
for i in non_idx:
if y_hat[i] > crossover_cutoff:
print(i)
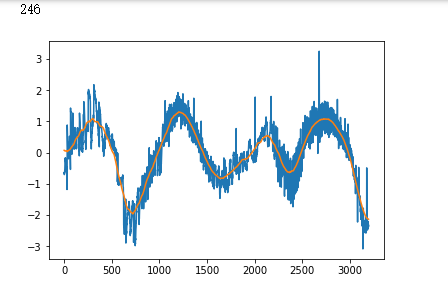
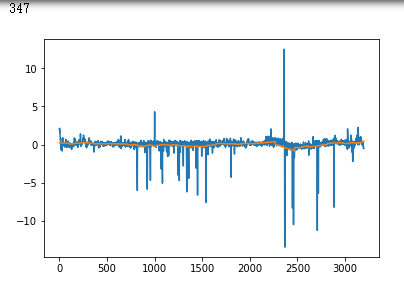
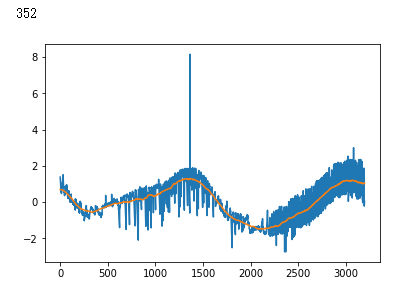
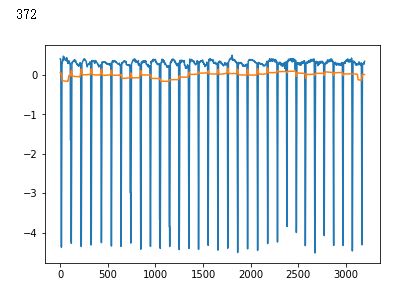
plt.plot(x_test[i])
plt.show()
吴裕雄--天生自然 PYTHON数据分析:基于Keras的CNN分析太空深处寻找系外行星数据的更多相关文章
- 吴裕雄--天生自然 python数据分析:健康指标聚集分析(健康分析)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:钦奈水资源管理分析
df = pd.read_csv("F:\\kaggleDataSet\\chennai-water\\chennai_reservoir_levels.csv") df[&quo ...
- 吴裕雄--天生自然 python数据分析:基于Keras使用CNN神经网络处理手写数据集
import pandas as pd import numpy as np import matplotlib.pyplot as plt import matplotlib.image as mp ...
- 吴裕雄--天生自然 PYTHON数据分析:糖尿病视网膜病变数据分析(完整版)
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 PYTHON数据分析:所有美国股票和etf的历史日价格和成交量分析
# This Python 3 environment comes with many helpful analytics libraries installed # It is defined by ...
- 吴裕雄--天生自然 python数据分析:葡萄酒分析
# import pandas import pandas as pd # creating a DataFrame pd.DataFrame({'Yes': [50, 31], 'No': [101 ...
- 吴裕雄--天生自然 PYTHON数据分析:人类发展报告——HDI, GDI,健康,全球人口数据数据分析
import pandas as pd # Data analysis import numpy as np #Data analysis import seaborn as sns # Data v ...
- 吴裕雄--天生自然 python数据分析:医疗费数据分析
import numpy as np import pandas as pd import os import matplotlib.pyplot as pl import seaborn as sn ...
- 吴裕雄--天生自然 PYTHON数据分析:医疗数据分析
import numpy as np # linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.rea ...
随机推荐
- geodjango七日学习笔记 (7.30整理本地笔记上传到网络)
第一天进行到现在,在开端的尾巴,想起来写一个学习笔记, 开发环境已搭好,用的是pycharm 环境是本机已有的interpreter python3.7 接下来要做的是新建一个geodjango项 ...
- java和数据库中所有的锁都在这了
1.java中的锁 1.1 锁的种类 公平锁/非公平锁 可重入锁/不可重入 独享锁/共享锁 读写锁 分段锁 偏向锁/轻量级锁/重量级锁 自旋锁 1.2 锁详细介绍 1.2.1 公平锁,非公平锁 公平锁 ...
- cin cout
编写一个程序,要求用户输入一串整数和任意数目的空格,这些整数必须位于同一行中,但允许出现在该行的任何位置.当用户按下enter键,数据输入停止.程序自动对所有的整数进行求和并打印出结果. 需要解决两个 ...
- ZJNU 1538 - YN!ngC的取子游戏--高级
Nim博弈 因为移动到第0阶会消失 所以可以得到从最后一个人操作必定是把第1阶所有子全部移动到第0阶 递推可得,最后一个能把奇数阶的子移动到偶数阶上的人将会必胜 所以这个必胜条件就是奇数阶上的子全部为 ...
- 自动按键的Sendkeys工具的下载和使用
大家好! 下面介绍一款自动按键的小工具:Sendkeys 下载地址 Sendkeys.rar 按键脚本的书写规则如下: 启动本工具后,在工具中打开一个脚本文件,然后在工具中按下Ctrl+A全选所有脚本 ...
- zookeeper注册中心和客户端
1.zookeeper和eureka区别 zookeeper向client进行ping操作,如果不通,就删除client节点 eureka自我保护机制是client向注册中心发送心跳包,如果一定时间内 ...
- 吴裕雄--天生自然TensorFlow高层封装:解决ValueError: Invalid backend. Missing required entry : placeholder
找到对应的keras配置文件keras.json 将里面的内容修改为以下就可以了
- 学习ECC及Openssl下ECC生成密钥的部分源代码心得
一.ECC的简介 椭圆曲线算法可以看作是定义在特殊集合下数的运算,满足一定的规则.椭圆曲线在如下两个域中定义:Fp域和F2m域. Fp域,素数域,p为素数: F2m域:特征为2的有限域,称之为二元域或 ...
- Java基础的坑
仍会出现NPE 需要改成
- PHP小点注意
(1)控制器不可以有list,因为它属于thinkPHP的保留关键字,不可以重名