Spark学习进度7-综合案例
综合案例
文件排序

解法:
1.读取数据
2.数据清洗,变换数据格式
3.从新分区成一个分区
4.按照key排序,返还带有位次的元组
5.输出
@Test
def filesort(): Unit ={
val source=sc.textFile("dataset/filesort.txt",3)
var index=0
/*
partitionBy:把所有的分区相关的数据组成一个新的分区
HashPartitioner(1):分成一个分区,使得在一个分区内总体有序
*/
val result= source.filter(_.trim().length>0).map(n => (n.trim.toInt,""))
.partitionBy(new HashPartitioner(1))
.sortByKey().map( t=> {
index+=1
(index,t._1)
})
result.foreach(println(_))
}
二次排序
题目大意:先按照第一个比,相同则按照第二个比
题意思路:
1.读取数据
2.转换格式如下


可用图片展示:

class SecondarySortKey(val first:Int,val second:Int) extends Ordered
[SecondarySortKey] with Serializable{ override def compare(that: SecondarySortKey): Int = {
if(this.first-that.first!=0){
this.first-that.first
}else {
this.second-that.second
}
}
}
//二次排序
@Test
def sortsecond(): Unit ={ val source=sc.textFile("dataset/secondsort.txt",3)
val secondrdd = source.map(item => (new SecondarySortKey(item.split(" ")(0).toInt, item.split(" ")(1).toInt), item))
.partitionBy(new HashPartitioner(1))
secondrdd.sortByKey(false)
.map(item => item._2)
.foreach(println(_)) }
连接操作
案例介绍:
有两个表:movie表,和score表
score:包含的信息为:用户ID,电影ID,电影评分
movie:电影ID,电影名字
我们想要得到,评分超过4分的(电影ID,电影名字,电影评分)
思路如下:
首先先弄score表:
1.获取想要的信息
2.获取对应电影ID的平均值
3.更换格式:keyBy,如下

对于movie表进行连接,连接前需要变化下格式
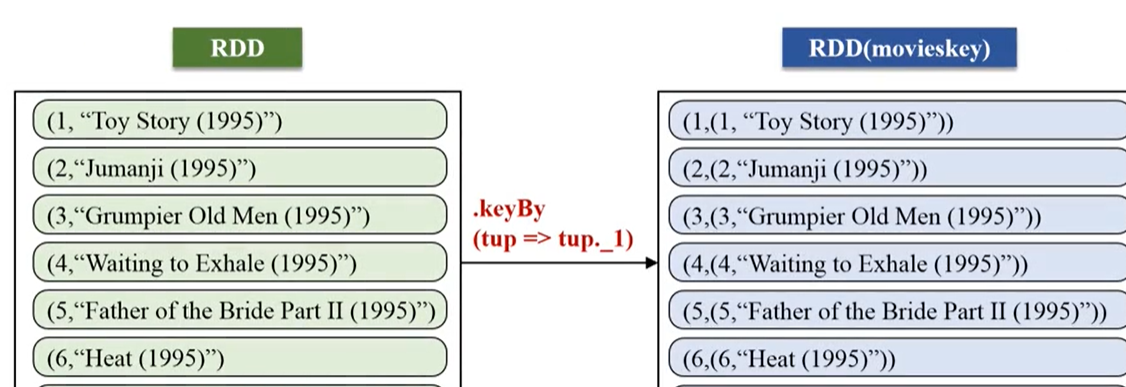
然后可通过相同的key进行连接join,后的结果如下:
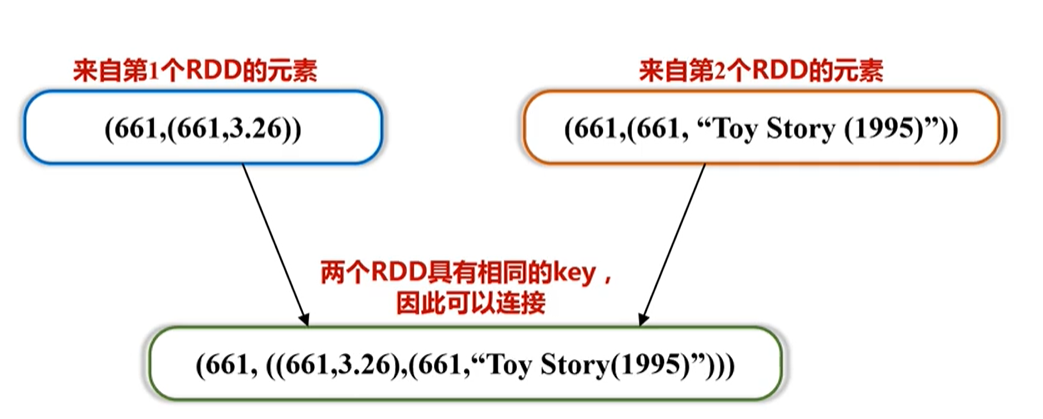
进行评分的过滤,然后取出需要的数据
@Test
/*
score:包含的信息为:用户ID,电影ID,电影评分
movie:电影ID,电影名字
*/
def joinTest(): Unit ={
val scoreRDD=sc.textFile("dataset/score.txt")
.map(line => {
val filed=line.split(",")
(filed(1).toInt,filed(2).toDouble)
})
.groupByKey()
.map(data =>{
val avg=data._2.sum/data._2.size
(data._1,avg)
})
.keyBy(it =>it._1) val movie=sc.textFile("dataset/movie.txt")
.map(line => {
val filed=line.split(",")
(filed(0).toInt,filed(1))
})
.keyBy(it =>it._1) scoreRDD.join(movie)
.filter(item => item._2._1._2>4.0)
.map(it => (it._1,it._2._2._2,it._2._1._2))
.foreach(println(_))
}
输出:
score表:

movie表:

最终输出:

Spark学习进度7-综合案例的更多相关文章
- Spark学习进度11-Spark Streaming&Structured Streaming
Spark Streaming Spark Streaming 介绍 批量计算 流计算 Spark Streaming 入门 Netcat 的使用 项目实例 目标:使用 Spark Streaming ...
- Spark学习进度-Spark环境搭建&Spark shell
Spark环境搭建 下载包 所需Spark包:我选择的是2.2.0的对应Hadoop2.7版本的,下载地址:https://archive.apache.org/dist/spark/spark-2. ...
- Spark学习进度-实战测试
spark-shell 交互式编程 题目:该数据集包含了某大学计算机系的成绩,数据格式如下所示: Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure ...
- SparkSQL学习进度9-SQL实战案例
Spark SQL 基本操作 将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json. { "id":1 , "name&quo ...
- Spark学习进度10-DS&DF基础操作
有类型操作 flatMap 通过 flatMap 可以将一条数据转为一个数组, 后再展开这个数组放入 Dataset val ds1=Seq("hello spark"," ...
- Spark学习进度-RDD
RDD RDD 是什么 定义 RDD, 全称为 Resilient Distributed Datasets, 是一个容错的, 并行的数据结构, 可以让用户显式地将数据存储到磁盘和内存中, 并能控制数 ...
- Spark学习进度-Transformation算子
Transformation算子 intersection 交集 /* 交集 */ @Test def intersection(): Unit ={ val rdd1=sc.parallelize( ...
- spark 学习路线及参考课程
一.Scala编程详解: 第1讲-Spark的前世今生 第2讲-课程介绍.特色与价值 第3讲-Scala编程详解:基础语法 第4讲-Scala编程详解:条件控制与循环 第5讲-Scala编程详解:函数 ...
- 【原创 Hadoop&Spark 动手实践 13】Spark综合案例:简易电影推荐系统
[原创 Hadoop&Spark 动手实践 13]Spark综合案例:简易电影推荐系统
随机推荐
- PHP代码审计分段讲解(2)
03 多重加密 源代码为: <?php include 'common.php'; $requset = array_merge($_GET, $_POST, $_SESSION, $_COOK ...
- vue项目中增加打印功能
export default function printFile(html) { let userAgent = navigator.userAgent; if ( (userAgent.index ...
- 原创:DynamicDataDisplay波形显示自定义格式
原创:DynamicDataDisplay 原版本在日期显示的格式上与我们的习惯不一样,特做如下修改: 自定义日期格式修改: //MainWindow.cs中 var ds = new Enumera ...
- OI知识点/得分技巧的归纳总结
网络流 拆点/拆边技巧 题目来源 bzoj1070 题目描述 同一时刻有\(N\)位车主带着他们的爱车来到了汽车维修中心.维修中心共有\(M\)位技术人员,不同的技术人员对不同 的车进行维修所用的时间 ...
- MySQL技术内幕InnoDB存储引擎(四)——表相关
表是什么? 就是关于特定实体地数据集合,是关系型数据库模型地核心. 索引组织表 什么是索引组织表? 表中数据都是根据主键的顺序组织存放的,这种存储方式就是索引组织表.就是存储在一个索引结构中的表. 也 ...
- java、tomcat安装
今天记录下如何安装java和tomcat,毕竟作为开发人员换电脑或重装系统后都是要装好这些环境的. java的安装: 1.下载sdk,官网地址:https://www.oracle.com/techn ...
- 【JAVA基础&Python】静态/非静态代码块
/* * * static静态代码块: * 调用静态属性的时候 对应类里面的静态代码块就会被直接执行 * 注意: 只会执行一次,只能调用类内静态结构的(方法/属性) * 作用: 初始化类的属性 * * ...
- [C#] (原创)一步一步教你自定义控件——05,Label(原生控件)
一.前言 技术没有先进与落后,只有合适与不合适. 自定义控件可以分为三类: 一类是"无中生有".就如之前文章中的的那些控件,都是继承基类Control,来实现特定的功能效果: 一类 ...
- Centos8 Docker+Nginx部署Asp.Net Core Nginx正向代理与反向代理 负载均衡实现无状态更新
首先了解Nginx 相关介绍(正向代理和反向代理区别) 所谓代理就是一个代表.一个渠道: 此时就涉及到两个角色,一个是被代理角色,一个是目标角色,被代理角色通过这个代理访问目标角色完成一些任务的过程称 ...
- Sentinel入门学习记录
最近公司里面在进行微服务开发,因为有使用到限流降级,所以去调研学习了一下Sentinel,在这里做一个记录. Sentinel官方文档:https://github.com/alibaba/Senti ...