Coursera, Big Data 1, Introduction (week 1/2)
Status: week 2 done.
Week 1, 主要讲了大数据的的来源 - 机器产生的数据,人产生的数据(比如社交软件上的update, 一般是unstructed data), 组织产生的数据(一般是structured data)
怎么把unstructured data 转化成 structured data?
利用 Hadoop, Storm, Spark and NoSQL. Hadoop 能解决data量大的问题,因为它是支持分布式计算的。 Storm 和 Spark 能分析像社交应用这种短时间内产生大量实时数据的情况, 还能和任何类型的DB集成.
传统的数据仓库是下面这样的。structed data 存在data warehouse里.
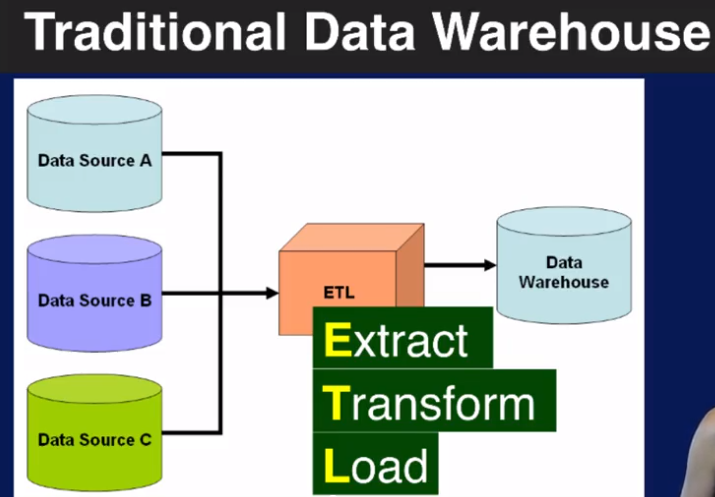
而现在的大数据时代,很多企业都是采用hybrid方案 - 把少量数据存在structured DB里,而更多的数据放在云上的 NoSQL DB里.
下面是两种NoSQL类型的数据库

Neo4j - graph db
Cassandra - key value db
Week 2
big data 的特征可以用几个V来概括.
Volume - Scale of data
Velocity (=Speed) - Analysis of streaming data (数据产生快,存储快,处理快)
Variety - Different forms of data
Veracity (=Quality) - Uncertainty of data
Valence - Connectness of big data in the forms of graphs


Getting value out of big data: 分析 big data, 形成 insight, 进而转化为 Action.
一个data stientist 应该具有相关的 technical skills, bussiness skills 和 soft skills, 并且因为需要的技能很多,最好形成团队来做一件事情.
Buiding a big data strategy:
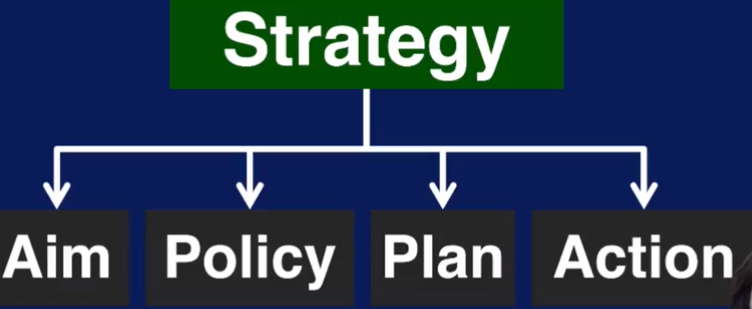
strategy 要成功,需要管理层的支持,一个多技能的团队,相应的培训,一个测试idea 的mini lab, 移除存取数据的障碍
数据科学的5个P
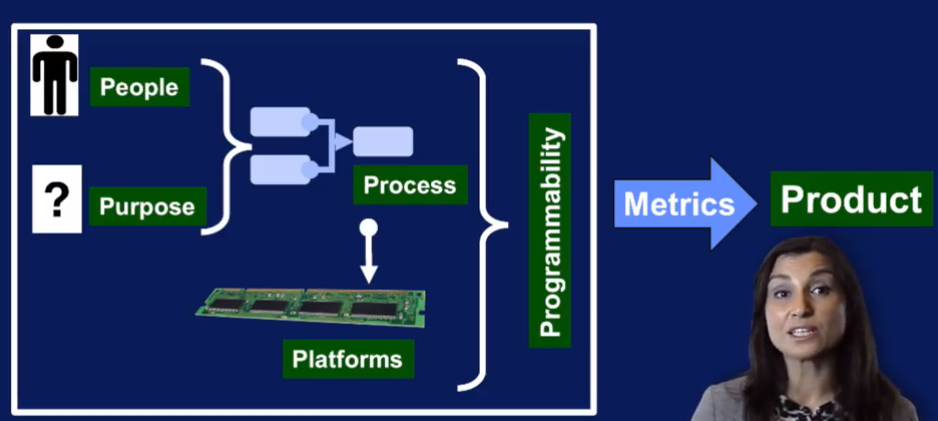
Steps in the data science process
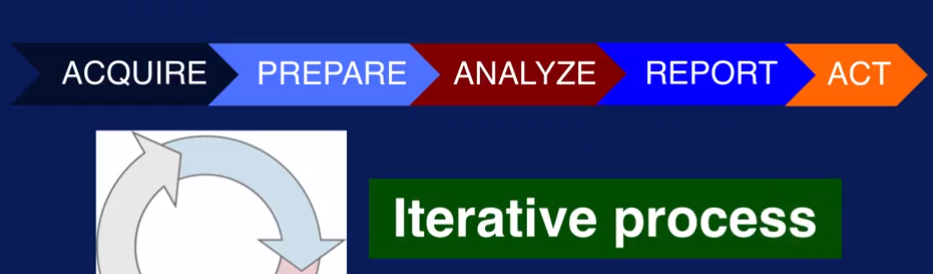
1. 获取原数据
从哪里获取,通过什么技术?
数据有结构化和非结构化的,来自不同来源. 结构化数据可以通过SQL 读取. 来自文件的data 可以通过Python等脚本语言读取. 远程数据(格式可能是xml, html, json ) 通过web service (rest, soap, web socket) 读取. 非结构化数据可以通过非结构数据库提供的API或者web service 来读取 (如下)
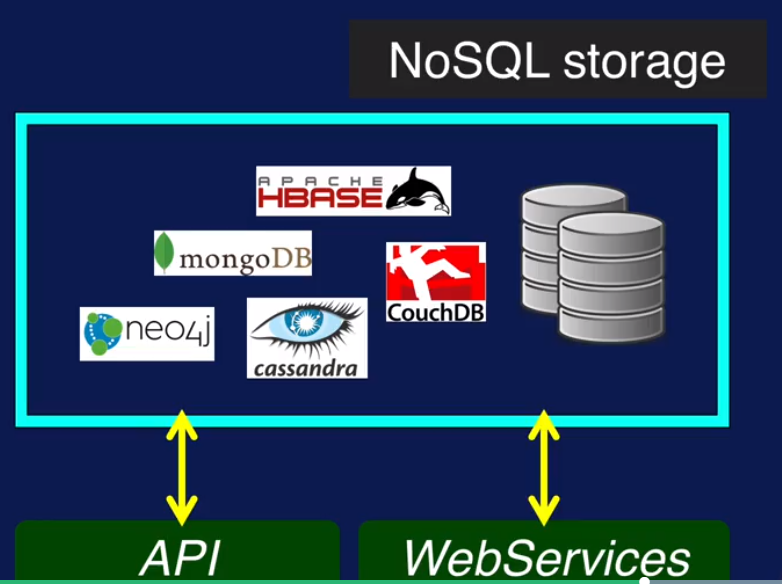
2. 准备数据
2.1 Explore data - understand your data (分析correlation, 画图表)
2.2 Pre-process (clean, integrate, package) :
Clean
Transform (Scaling, feature selection, Dimensionality Reduction)
3. 分析数据 (选分析技术,创建model)
要分析具体是什么问题然后选取对应的分析技术,比如,regression, classification, clustering, graph analytics, association analysis
4. 报告分析结果
报告什么内容,用什么技术 (R, Python 都有很好的画图功能)
5. Action - Turn insight into action
Coursera, Big Data 1, Introduction (week 1/2)的更多相关文章
- Coursera, Big Data 1, Introduction (week 3)
什么是分布式文件系统?为什么需要分布式文件系统? 如果文件系统可以管理用网络连接的很多个存储单元,叫分布式文件系统. 分布式文件系统提供了数据可扩展性,容错性,高并发. 这些是传统文件系统不具有的. ...
- Building Applications with Force.com and VisualForce(Dev401)(十六):Data Management: Introduction to Upsert
Dev401-017:Data Management: Introduction to Upsert Module Objectives1.Define upsert.2.Define externa ...
- Coursera, Big Data 2, Modeling and Management Systems (week 1/2/3)
Introduction to data management 整个coures 2 是讲data management and storage 的,主要内容就是分布式文件系统,HDFS, Redis ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 1/2)
Week 1 Machine Learning with Big Data KNime - GUI based Spark MLlib - inside Spark CRISP-DM Week 2, ...
- Coursera, Big Data 3, Integration and Processing (week 5)
Week 5, Big Data Analytics using Spark Programing in Spark Spark Core: Programming in Spark us ...
- Coursera, Big Data 3, Integration and Processing (week 4)
Week 4 Big Data Precessing Pipeline 上图可以generalize 成下图,也就是Big data pipeline some high level processi ...
- Coursera, Big Data 3, Integration and Processing (week 1/2/3)
This is the 3rd course in big data specification courses. Data model reivew 1, data model 的特点: Struc ...
- Coursera, Big Data 2, Modeling and Management Systems (week 4/5/6)
week4 streaming data format 下面讲 data lakes schema-on-read: 从数据源读取raw data 直接放到 data lake 里,然后再读到mode ...
- Coursera, Big Data 4, Machine Learning With Big Data (week 3/4/5)
week 3 Classification KNN :基本思想是 input value 类似,就可能是同一类的 Decision Tree Naive Bayes Week 4 Evaluating ...
随机推荐
- eureka集群基于DNS配置方式
https://www.cnblogs.com/relinson/p/eureka_ha_use_dns.html 最近在研究spring cloud eureka集群配置的时候碰到问题:多台eu ...
- 软件补丁问题(SPFA+位运算)
洛谷P2761 1.考虑到所有的错误只有“修复,未修复”两种情况,所以可以用0,1标记压缩状态,采用位运算减少时空浪费. 又考虑到有修复时间的关系,将时间抽象成边,将状态抽象为点(设修复为0,未修复为 ...
- Mybatis 批量插入时得到插入的id(mysql)
前言: 在开发中,我们可能很多的时候可能需要在新增时得到刚才新增的id,后续的逻辑需要用到这个id. 在插入单条记录的情况下,这个是很简单的问题.多条记录时有个坑在里面. 单条记录的代码如下 < ...
- Django 自定义过滤器
设定自定义过滤器之前要现在配置文件内把自己项目名在 INSTALLED_APPS 内导入 #已安装的django应用 INSTALLED_APPS = [ 'django.contrib.admin' ...
- 物理服务器Linux下软RAID和UUID方式挂载方法--Megacli64
一.业务部门需求说明:公司最近来了一批服务器,用于大数据业务部署.数据节点服务器由14块物理磁盘,其中有2块是900G的盘,12块是4T的盘.在服务器系统安装时,进入系统的BIOS界面:1)将2块90 ...
- opencv: 排序
opencv提供了排序函数: sort和sorIdx , 其中sortIdx可以获取排序后的序号,比较方便: sortIdx原型: C++: void sortIdx(InputArray src, ...
- break #立即终止本次循环
#!/user/bin/python# -*- coding:utf-8 -*-# print(111)# while True:# print(222)# print(333)# break #立即 ...
- 图论分支-Tarjan初步-点双连通分量
上一次我们讲到了边双,这次我们来看点双. 说实话来说,点双比边双稍微复杂一些: 学完边双,我们先看一道题 第一问都不用说了吧,多余的道路,明显的割边. 是不是首先想到用边双,但是我们来看一个图: 有点 ...
- JavaSE_坚持读源码_String对象_Java1.7
/** * Compares this string to the specified object. The result is {@code * true} if and only if the ...
- 【.net】“Newtonsoft.Json”已拥有为“Microsoft.CSharp”定义的依赖项。
#事故现场: “Newtonsoft.Json”已拥有为“Microsoft.CSharp”定义的依赖项. #事故原因: 安装的Newtonsoft.Json版本为11.0.2,版本过高,与Micro ...